 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Compression for Teacher-to-Student Knowledge Transfer
Paper and Code
Feb 09, 2024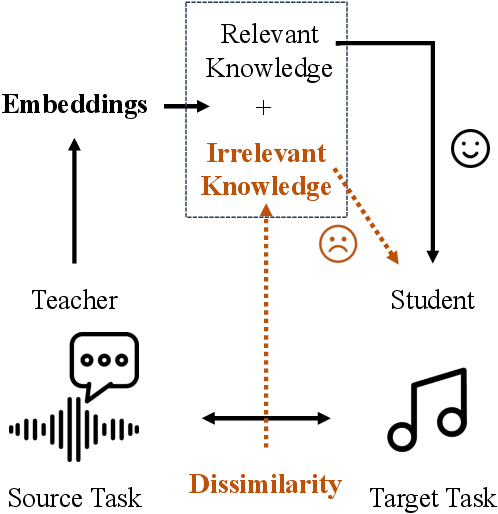
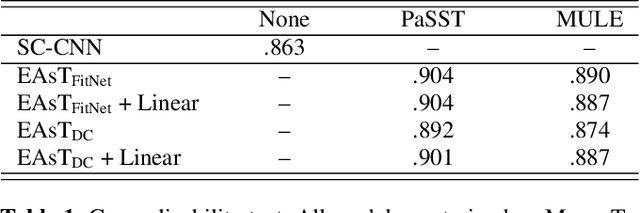
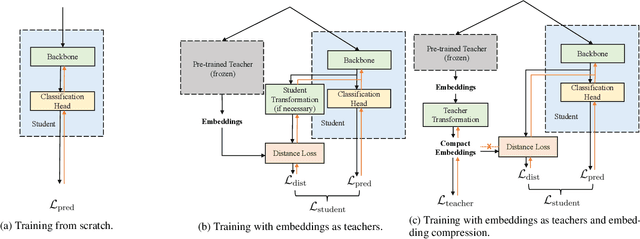
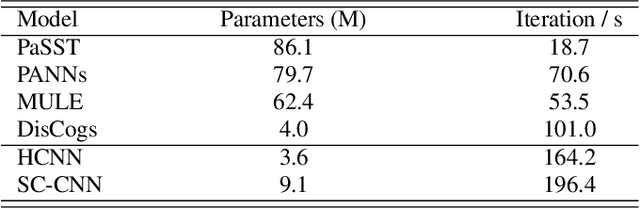
Common knowledge distillation methods require the teacher model and the student model to be trained on the same task. However, the usage of embeddings as teachers has also been proposed for different source tasks and target tasks. Prior work that uses embeddings as teachers ignores the fact that the teacher embeddings are likely to contain irrelevant knowledge for the target task. To address this problem, we propose to use an embedding compression module with a trainable teacher transformation to obtain a compact teacher embedding. Results show that adding the embedding compression module improves the classification performance, especially for unsupervised teacher embeddings. Moreover, student models trained with the guidance of embeddings show stronger generalizability.