 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Web Toolkits for Multimodal Piano Performance Dataset Acquisition and Fingering Annotation
Sep 18, 2025Piano performance is a multimodal activity that intrinsically combines physical actions with the acoustic rendition. Despite growing research interest in analyzing the multimodal nature of piano performance, the laborious process of acquiring large-scale multimodal data remains a significant bottleneck, hindering further progress in this field. To overcome this barrier, we present an integrated web toolkit comprising two graphical user interfaces (GUIs): (i) PiaRec, which supports the synchronized acquisition of audio, video, MIDI, and performance metadata. (ii) ASDF, which enables the efficient annotation of performer fingering from the visual data. Collectively, this system can streamline the acquisition of multimodal piano performance datasets.
PianoVAM: A Multimodal Piano Performance Dataset
Sep 10, 2025



The multimodal nature of music performance has driven increasing interest in data beyond the audio domain within the music information retrieval (MIR) community. This paper introduces PianoVAM, a comprehensive piano performance dataset that includes videos, audio, MIDI, hand landmarks, fingering labels, and rich metadata. The dataset was recorded using a Disklavier piano, capturing audio and MIDI from amateur pianists during their daily practice sessions, alongside synchronized top-view videos in realistic and varied performance conditions. Hand landmarks and fingering labels were extracted using a pretrained hand pose estimation model and a semi-automated fingering annotation algorithm. We discuss the challenges encountered during data collection and the alignment process across different modalities. Additionally, we describe our fingering annotation method based on hand landmarks extracted from videos. Finally, we present benchmarking results for both audio-only and audio-visual piano transcription using the PianoVAM dataset and discuss additional potential applications.
Survey on the Evaluation of Generative Models in Music
Jun 05, 2025Research on generative systems in music has seen considerable attention and growth in recent years. A variety of attempts have been made to systematically evaluate such systems. We provide an interdisciplinary review of the common evaluation targets, methodologies, and metrics for the evaluation of both system output and model usability, covering subjective and objective approaches, qualitative and quantitative approaches, as well as empirical and computational methods. We discuss the advantages and challenges of such approaches from a musicological, an engineering, and an HCI perspective.
Separate This, and All of these Things Around It: Music Source Separation via Hyperellipsoidal Queries
Jan 27, 2025



Music source separation is an audio-to-audio retrieval task of extracting one or more constituent components, or composites thereof, from a musical audio mixture. Each of these constituent components is often referred to as a "stem" in literature. Historically, music source separation has been dominated by a stem-based paradigm, leading to most state-of-the-art systems being either a collection of single-stem extraction models, or a tightly coupled system with a fixed, difficult-to-modify, set of supported stems. Combined with the limited data availability, advances in music source separation have thus been mostly limited to the "VDBO" set of stems: \textit{vocals}, \textit{drum}, \textit{bass}, and the catch-all \textit{others}. Recent work in music source separation has begun to challenge the fixed-stem paradigm, moving towards models able to extract any musical sound as long as this target type of sound could be specified to the model as an additional query input. We generalize this idea to a \textit{query-by-region} source separation system, specifying the target based on the query regardless of how many sound sources or which sound classes are contained within it. To do so, we propose the use of hyperellipsoidal regions as queries to allow for an intuitive yet easily parametrizable approach to specifying both the target (location) as well as its spread. Evaluation of the proposed system on the MoisesDB dataset demonstrated state-of-the-art performance of the proposed system both in terms of signal-to-noise ratios and retrieval metrics.
Uncertainty Estimation in the Real World: A Study on Music Emotion Recognition
Jan 20, 2025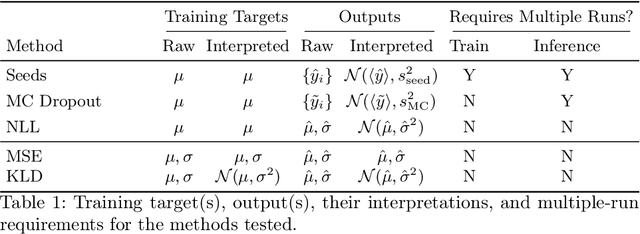
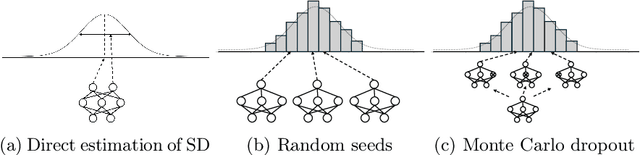
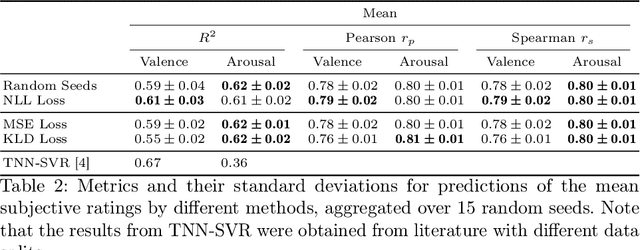
Any data annotation for subjective tasks shows potential variations between individuals. This is particularly true for annotations of emotional responses to musical stimuli. While older approaches to music emotion recognition systems frequently addressed this uncertainty problem through probabilistic modeling, modern systems based on neural networks tend to ignore the variability and focus only on predicting central tendencies of human subjective responses. In this work, we explore several methods for estimating not only the central tendencies of the subjective responses to a musical stimulus, but also for estimating the uncertainty associated with these responses. In particular, we investigate probabilistic loss functions and inference-time random sampling. Experimental results indicate that while the modeling of the central tendencies is achievable, modeling of the uncertainty in subjective responses proves significantly more challenging with currently available approaches even when empirical estimates of variations in the responses are available.
Towards Robust Transcription: Exploring Noise Injection Strategies for Training Data Augmentation
Oct 18, 2024


Recent advancements in Automatic Piano Transcription (APT) have significantly improved system performance, but the impact of noisy environments on the system performance remains largely unexplored. This study investigates the impact of white noise at various Signal-to-Noise Ratio (SNR) levels on state-of-the-art APT models and evaluates the performance of the Onsets and Frames model when trained on noise-augmented data. We hope this research provides valuable insights as preliminary work toward developing transcription models that maintain consistent performance across a range of acoustic conditions.
Music auto-tagging in the long tail: A few-shot approach
Sep 12, 2024



In the realm of digital music, using tags to efficiently organize and retrieve music from extensive databases is crucial for music catalog owners. Human tagging by experts is labor-intensive but mostly accurate, whereas automatic tagging through supervised learning has approached satisfying accuracy but is restricted to a predefined set of training tags. Few-shot learning offers a viable solution to expand beyond this small set of predefined tags by enabling models to learn from only a few human-provided examples to understand tag meanings and subsequently apply these tags autonomously. We propose to integrate few-shot learning methodology into multi-label music auto-tagging by using features from pre-trained models as inputs to a lightweight linear classifier, also known as a linear probe. We investigate different popular pre-trained features, as well as different few-shot parametrizations with varying numbers of classes and samples per class. Our experiments demonstrate that a simple model with pre-trained features can achieve performance close to state-of-the-art models while using significantly less training data, such as 20 samples per tag. Additionally, our linear probe performs competitively with leading models when trained on the entire training dataset. The results show that this transfer learning-based few-shot approach could effectively address the issue of automatically assigning long-tail tags with only limited labeled data.
A Stem-Agnostic Single-Decoder System for Music Source Separation Beyond Four Stems
Jun 26, 2024Despite significant recent progress across multiple subtasks of audio source separation, few music source separation systems support separation beyond the four-stem vocals, drums, bass, and other (VDBO) setup. Of the very few current systems that support source separation beyond this setup, most continue to rely on an inflexible decoder setup that can only support a fixed pre-defined set of stems. Increasing stem support in these inflexible systems correspondingly requires increasing computational complexity, rendering extensions of these systems computationally infeasible for long-tail instruments. In this work, we propose Banquet, a system that allows source separation of multiple stems using just one decoder. A bandsplit source separation model is extended to work in a query-based setup in tandem with a music instrument recognition PaSST model. On the MoisesDB dataset, Banquet, at only 24.9 M trainable parameters, approached the performance level of the significantly more complex 6-stem Hybrid Transformer Demucs on VDBO stems and outperformed it on guitar and piano. The query-based setup allows for the separation of narrow instrument classes such as clean acoustic guitars, and can be successfully applied to the extraction of less common stems such as reeds and organs. Implementation is available at https://github.com/kwatcharasupat/query-bandit.
Understanding Pedestrian Movement Using Urban Sensing Technologies: The Promise of Audio-based Sensors
Jun 14, 2024While various sensors have been deployed to monitor vehicular flows, sensing pedestrian movement is still nascent. Yet walking is a significant mode of travel in many cities, especially those in Europe, Africa, and Asia. Understanding pedestrian volumes and flows is essential for designing safer and more attractive pedestrian infrastructure and for controlling periodic overcrowding. This study discusses a new approach to scale up urban sensing of people with the help of novel audio-based technology. It assesses the benefits and limitations of microphone-based sensors as compared to other forms of pedestrian sensing. A large-scale dataset called ASPED is presented, which includes high-quality audio recordings along with video recordings used for labeling the pedestrian count data. The baseline analyses highlight the promise of using audio sensors for pedestrian tracking, although algorithmic and technological improvements to make the sensors practically usable continue. This study also demonstrates how the data can be leveraged to predict pedestrian trajectories. Finally, it discusses the use cases and scenarios where audio-based pedestrian sensing can support better urban and transportation planning.
Embedding Compression for Teacher-to-Student Knowledge Transfer
Feb 09, 2024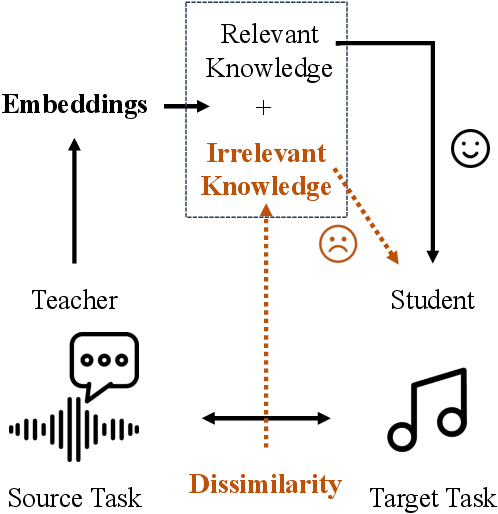
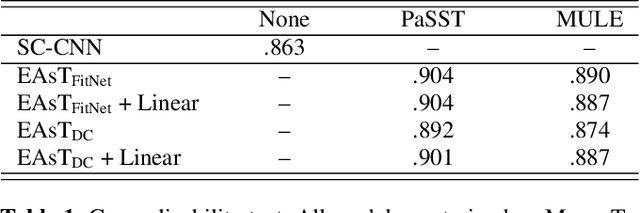
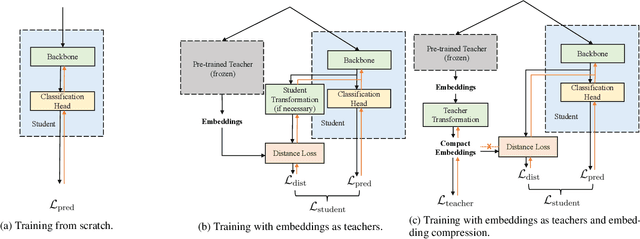
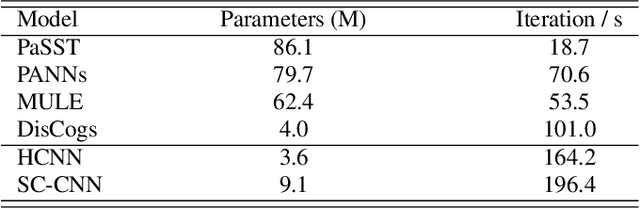
Common knowledge distillation methods require the teacher model and the student model to be trained on the same task. However, the usage of embeddings as teachers has also been proposed for different source tasks and target tasks. Prior work that uses embeddings as teachers ignores the fact that the teacher embeddings are likely to contain irrelevant knowledge for the target task. To address this problem, we propose to use an embedding compression module with a trainable teacher transformation to obtain a compact teacher embedding. Results show that adding the embedding compression module improves the classification performance, especially for unsupervised teacher embeddings. Moreover, student models trained with the guidance of embeddings show stronger generalizability.