 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparate This, and All of these Things Around It: Music Source Separation via Hyperellipsoidal Queries
Jan 27, 2025



Music source separation is an audio-to-audio retrieval task of extracting one or more constituent components, or composites thereof, from a musical audio mixture. Each of these constituent components is often referred to as a "stem" in literature. Historically, music source separation has been dominated by a stem-based paradigm, leading to most state-of-the-art systems being either a collection of single-stem extraction models, or a tightly coupled system with a fixed, difficult-to-modify, set of supported stems. Combined with the limited data availability, advances in music source separation have thus been mostly limited to the "VDBO" set of stems: \textit{vocals}, \textit{drum}, \textit{bass}, and the catch-all \textit{others}. Recent work in music source separation has begun to challenge the fixed-stem paradigm, moving towards models able to extract any musical sound as long as this target type of sound could be specified to the model as an additional query input. We generalize this idea to a \textit{query-by-region} source separation system, specifying the target based on the query regardless of how many sound sources or which sound classes are contained within it. To do so, we propose the use of hyperellipsoidal regions as queries to allow for an intuitive yet easily parametrizable approach to specifying both the target (location) as well as its spread. Evaluation of the proposed system on the MoisesDB dataset demonstrated state-of-the-art performance of the proposed system both in terms of signal-to-noise ratios and retrieval metrics.
Uncertainty Estimation in the Real World: A Study on Music Emotion Recognition
Jan 20, 2025
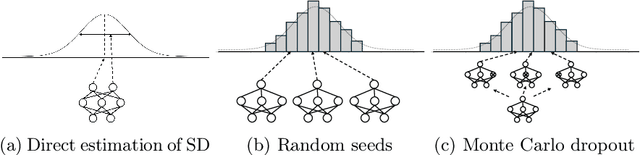
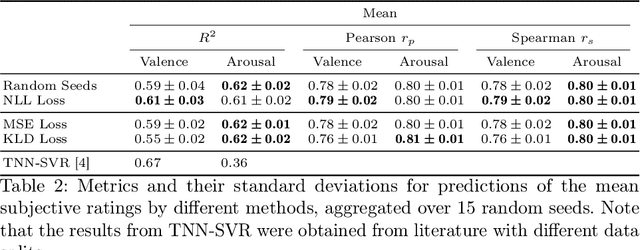
Any data annotation for subjective tasks shows potential variations between individuals. This is particularly true for annotations of emotional responses to musical stimuli. While older approaches to music emotion recognition systems frequently addressed this uncertainty problem through probabilistic modeling, modern systems based on neural networks tend to ignore the variability and focus only on predicting central tendencies of human subjective responses. In this work, we explore several methods for estimating not only the central tendencies of the subjective responses to a musical stimulus, but also for estimating the uncertainty associated with these responses. In particular, we investigate probabilistic loss functions and inference-time random sampling. Experimental results indicate that while the modeling of the central tendencies is achievable, modeling of the uncertainty in subjective responses proves significantly more challenging with currently available approaches even when empirical estimates of variations in the responses are available.
Facing the Music: Tackling Singing Voice Separation in Cinematic Audio Source Separation
Aug 07, 2024Cinematic audio source separation (CASS) is a fairly new subtask of audio source separation. A typical setup of CASS is a three-stem problem, with the aim of separating the mixture into the dialogue stem (DX), music stem (MX), and effects stem (FX). In practice, however, several edge cases exist as some sound sources do not fit neatly in either of these three stems, necessitating the use of additional auxiliary stems in production. One very common edge case is the singing voice in film audio, which may belong in either the DX or MX, depending heavily on the cinematic context. In this work, we demonstrate a very straightforward extension of the dedicated-decoder Bandit and query-based single-decoder Banquet models to a four-stem problem, treating non-musical dialogue, instrumental music, singing voice, and effects as separate stems. Interestingly, the query-based Banquet model outperformed the dedicated-decoder Bandit model. We hypothesized that this is due to a better feature alignment at the bottleneck as enforced by the band-agnostic FiLM layer. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Remastering Divide and Remaster: A Cinematic Audio Source Separation Dataset with Multilingual Support
Jul 09, 2024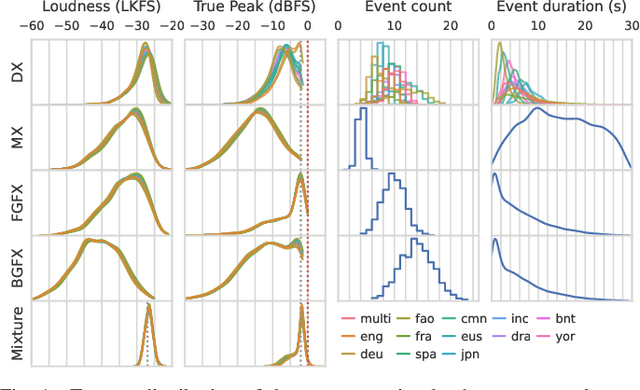
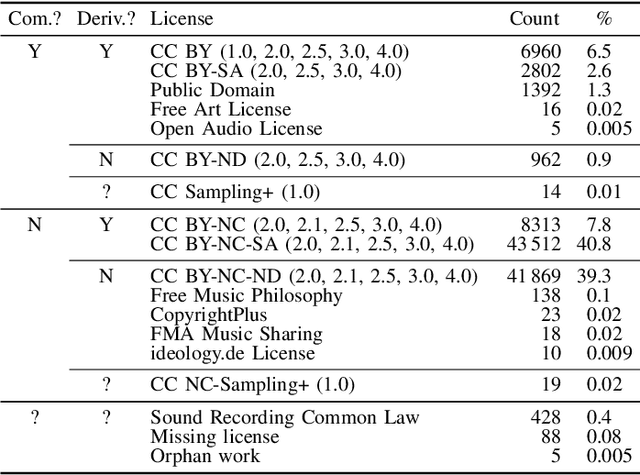
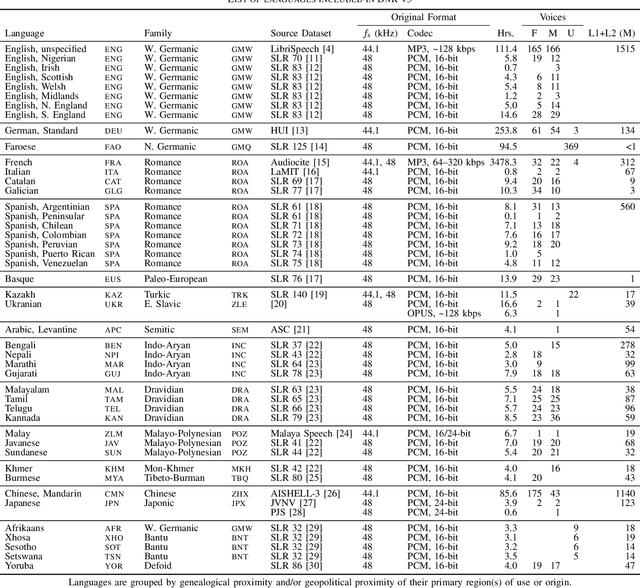
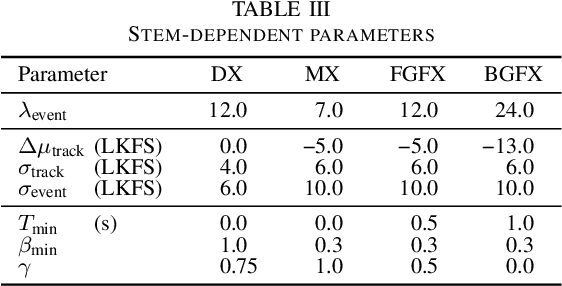
Cinematic audio source separation (CASS) is a relatively new subtask of audio source separation, concerned with the separation of a mixture into the dialogue, music, and effects stems. To date, only one publicly available dataset exists for CASS, that is, the Divide and Remaster (DnR) dataset, which is currently at version 2. While DnR v2 has been an incredibly useful resource for CASS, several areas of improvement have been identified, particularly through its use in the 2023 Sound Demixing Challenge. In this work, we develop version 3 of the DnR dataset, addressing issues relating to vocal content in non-dialogue stems, loudness distributions, mastering process, and linguistic diversity. In particular, the dialogue stem of DnR v3 includes speech content from more than 30 languages from multiple families including but not limited to the Germanic, Romance, Indo-Aryan, Dravidian, Malayo-Polynesian, and Bantu families. Benchmark results using the Bandit model indicated that training on multilingual data yields significant generalizability to the model even in languages with low data availability. Even in languages with high data availability, the multilingual model often performs on par or better than dedicated models trained on monolingual CASS datasets.
Automating Urban Soundscape Enhancements with AI: In-situ Assessment of Quality and Restorativeness in Traffic-Exposed Residential Areas
Jul 08, 2024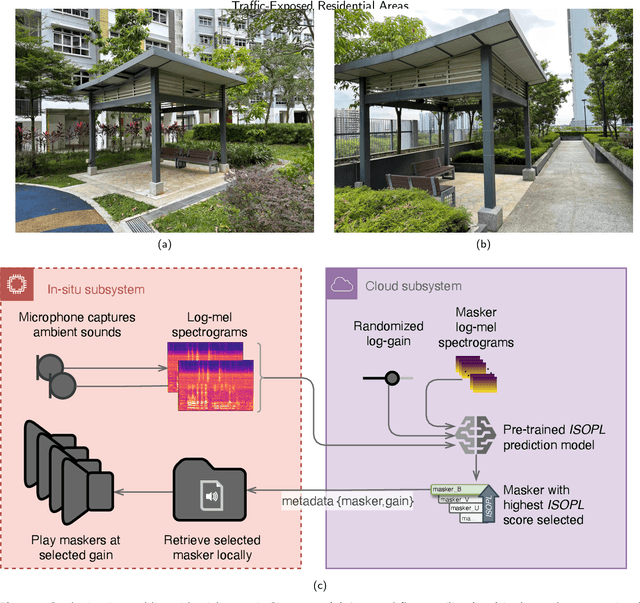


Formalized in ISO 12913, the "soundscape" approach is a paradigmatic shift towards perception-based urban sound management, aiming to alleviate the substantial socioeconomic costs of noise pollution to advance the United Nations Sustainable Development Goals. Focusing on traffic-exposed outdoor residential sites, we implemented an automatic masker selection system (AMSS) utilizing natural sounds to mask (or augment) traffic soundscapes. We employed a pre-trained AI model to automatically select the optimal masker and adjust its playback level, adapting to changes over time in the ambient environment to maximize "Pleasantness", a perceptual dimension of soundscape quality in ISO 12913. Our validation study involving ($N=68$) residents revealed a significant 14.6 % enhancement in "Pleasantness" after intervention, correlating with increased restorativeness and positive affect. Perceptual enhancements at the traffic-exposed site matched those at a quieter control site with 6 dB(A) lower $L_\text{A,eq}$ and road traffic noise dominance, affirming the efficacy of AMSS as a soundscape intervention, while streamlining the labour-intensive assessment of "Pleasantness" with probabilistic AI prediction.
A Stem-Agnostic Single-Decoder System for Music Source Separation Beyond Four Stems
Jun 26, 2024Despite significant recent progress across multiple subtasks of audio source separation, few music source separation systems support separation beyond the four-stem vocals, drums, bass, and other (VDBO) setup. Of the very few current systems that support source separation beyond this setup, most continue to rely on an inflexible decoder setup that can only support a fixed pre-defined set of stems. Increasing stem support in these inflexible systems correspondingly requires increasing computational complexity, rendering extensions of these systems computationally infeasible for long-tail instruments. In this work, we propose Banquet, a system that allows source separation of multiple stems using just one decoder. A bandsplit source separation model is extended to work in a query-based setup in tandem with a music instrument recognition PaSST model. On the MoisesDB dataset, Banquet, at only 24.9 M trainable parameters, approached the performance level of the significantly more complex 6-stem Hybrid Transformer Demucs on VDBO stems and outperformed it on guitar and piano. The query-based setup allows for the separation of narrow instrument classes such as clean acoustic guitars, and can be successfully applied to the extraction of less common stems such as reeds and organs. Implementation is available at https://github.com/kwatcharasupat/query-bandit.
A Generalized Bandsplit Neural Network for Cinematic Audio Source Separation
Sep 07, 2023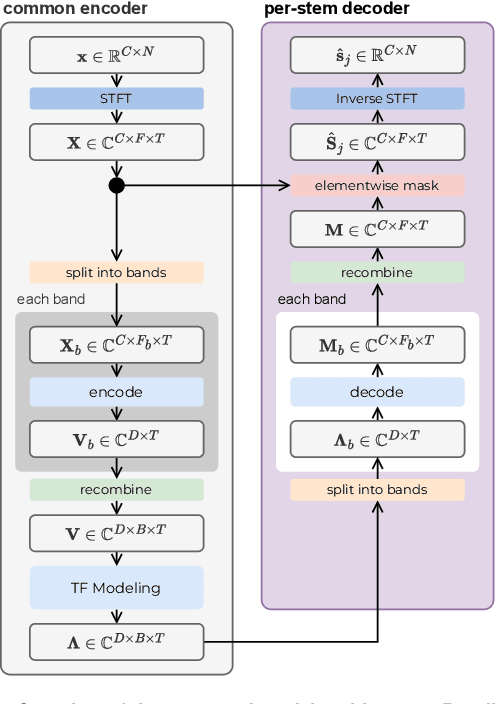
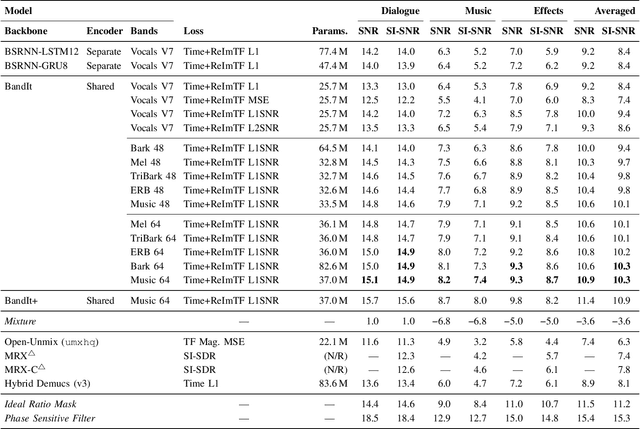
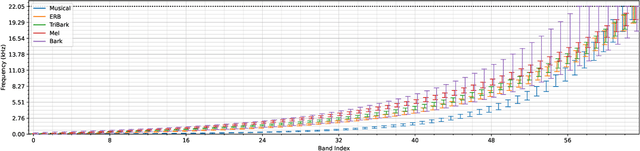

Cinematic audio source separation is a relatively new subtask of audio source separation, with the aim of extracting the dialogue stem, the music stem, and the effects stem from their mixture. In this work, we developed a model generalizing the Bandsplit RNN for any complete or overcomplete partitions of the frequency axis. Psycho-acoustically motivated frequency scales were used to inform the band definitions which are now defined with redundancy for more reliable feature extraction. A loss function motivated by the signal-to-noise ratio and the sparsity-promoting property of the 1-norm was proposed. We additionally exploit the information-sharing property of a common-encoder setup to reduce computational complexity during both training and inference, improve separation performance for hard-to-generalize classes of sounds, and allow flexibility during inference time with easily detachable decoders. Our best model sets the state of the art on the Divide and Remaster dataset with performance above the ideal ratio mask for the dialogue stem.
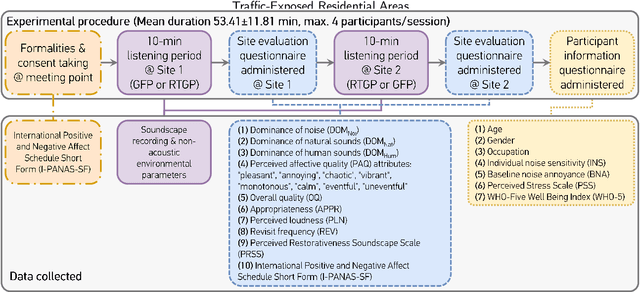
Preliminary investigation of the short-term in situ performance of an automatic masker selection system
Aug 15, 2023
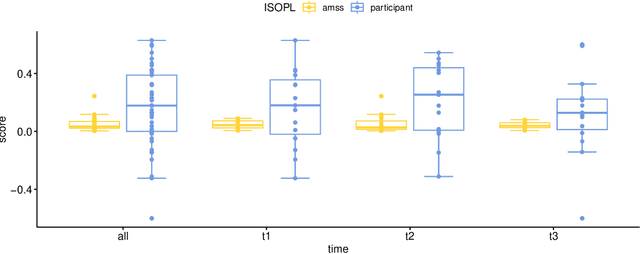
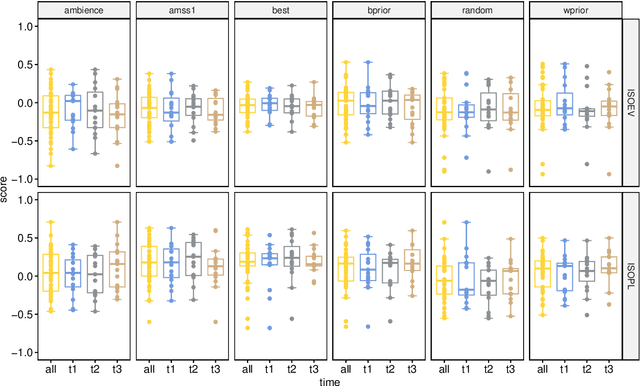

Soundscape augmentation or "masking" introduces wanted sounds into the acoustic environment to improve acoustic comfort. Usually, the masker selection and playback strategies are either arbitrary or based on simple rules (e.g. -3 dBA), which may lead to sub-optimal increment or even reduction in acoustic comfort for dynamic acoustic environments. To reduce ambiguity in the selection of maskers, an automatic masker selection system (AMSS) was recently developed. The AMSS uses a deep-learning model trained on a large-scale dataset of subjective responses to maximize the derived ISO pleasantness (ISO 12913-2). Hence, this study investigates the short-term in situ performance of the AMSS implemented in a gazebo in an urban park. Firstly, the predicted ISO pleasantness from the AMSS is evaluated in comparison to the in situ subjective evaluation scores. Secondly, the effect of various masker selection schemes on the perceived affective quality and appropriateness would be evaluated. In total, each participant evaluated 6 conditions: (1) ambient environment with no maskers; (2) AMSS; (3) bird and (4) water masker from prior art; (5) random selection from same pool of maskers used to train the AMSS; and (6) selection of best-performing maskers based on the analysis of the dataset used to train the AMSS.
Evaluation of Spatial Distortion in Multichannel Audio
Jun 13, 2023



Despite the recent proliferation of spatial audio technologies, the evaluation of spatial quality continues to rely on subjective listening tests, often requiring expert listeners. Based on the duplex theory of spatial hearing, it is possible to construct a signal model for frequency-independent spatial distortion by accounting for inter-channel time and level differences relative to a reference signal. By using a combination of least-square optimization and heuristics, we propose a signal decomposition method to isolate the spatial error from a processed signal. This allows the computation of simple energy-ratio metrics, providing objective measures of spatial and non-spatial signal qualities, with minimal assumption and no dataset dependency. Experiments demonstrate robustness of the method against common signal degradation as introduced by, e.g., audio compression and music source separation. Implementation is available at https://github.com/karnwatcharasupat/spauq.
Autonomous Soundscape Augmentation with Multimodal Fusion of Visual and Participant-linked Inputs
Mar 15, 2023

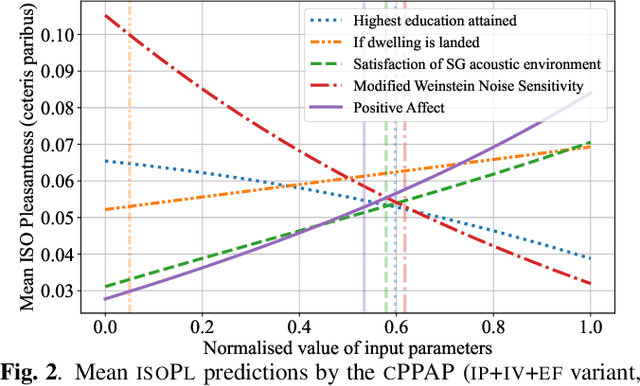
Autonomous soundscape augmentation systems typically use trained models to pick optimal maskers to effect a desired perceptual change. While acoustic information is paramount to such systems, contextual information, including participant demographics and the visual environment, also influences acoustic perception. Hence, we propose modular modifications to an existing attention-based deep neural network, to allow early, mid-level, and late feature fusion of participant-linked, visual, and acoustic features. Ablation studies on module configurations and corresponding fusion methods using the ARAUS dataset show that contextual features improve the model performance in a statistically significant manner on the normalized ISO Pleasantness, to a mean squared error of $0.1194\pm0.0012$ for the best-performing all-modality model, against $0.1217\pm0.0009$ for the audio-only model. Soundscape augmentation systems can thereby leverage multimodal inputs for improved performance. We also investigate the impact of individual participant-linked factors using trained models to illustrate improvements in model explainability.