 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODAQ: Open Dataset of Audio Quality
Dec 30, 2023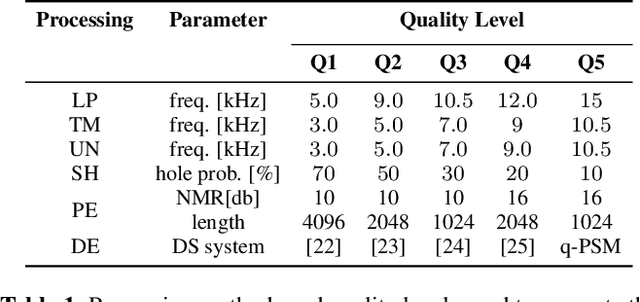
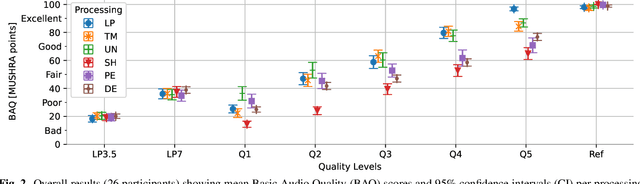
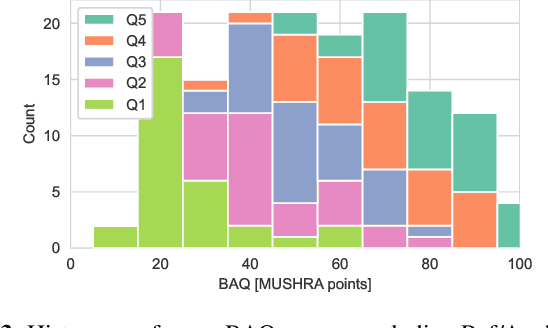
Research into the prediction and analysis of perceived audio quality is hampered by the scarcity of openly available datasets of audio signals accompanied by corresponding subjective quality scores. To address this problem, we present the Open Dataset of Audio Quality (ODAQ), a new dataset containing the results of a MUSHRA listening test conducted with expert listeners from 2 international laboratories. ODAQ contains 240 audio samples and corresponding quality scores. Each audio sample is rated by 26 listeners. The audio samples are stereo audio signals sampled at 44.1 or 48 kHz and are processed by a total of 6 method classes, each operating at different quality levels. The processing method classes are designed to generate quality degradations possibly encountered during audio coding and source separation, and the quality levels for each method class span the entire quality range. The diversity of the processing methods, the large span of quality levels, the high sampling frequency, and the pool of international listeners make ODAQ particularly suited for further research into subjective and objective audio quality. The dataset is released with permissive licenses, and the software used to conduct the listening test is also made publicly available.
A Generalized Bandsplit Neural Network for Cinematic Audio Source Separation
Sep 07, 2023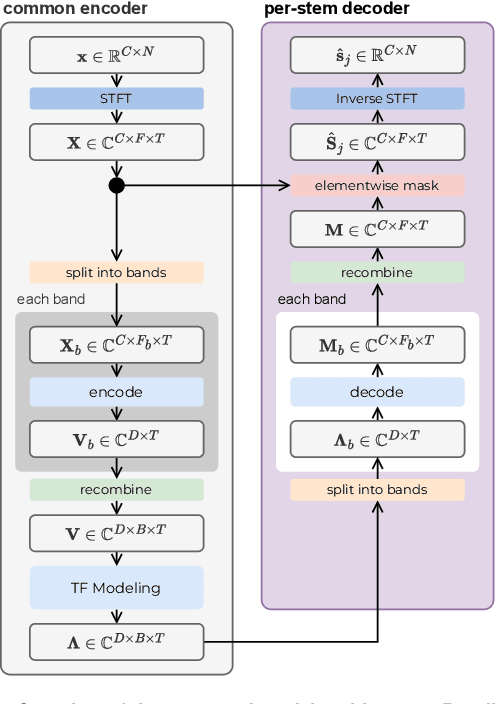
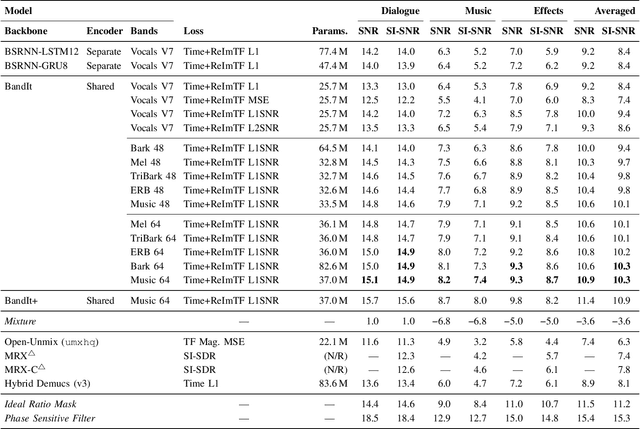
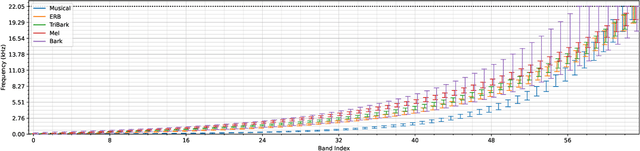

Cinematic audio source separation is a relatively new subtask of audio source separation, with the aim of extracting the dialogue stem, the music stem, and the effects stem from their mixture. In this work, we developed a model generalizing the Bandsplit RNN for any complete or overcomplete partitions of the frequency axis. Psycho-acoustically motivated frequency scales were used to inform the band definitions which are now defined with redundancy for more reliable feature extraction. A loss function motivated by the signal-to-noise ratio and the sparsity-promoting property of the 1-norm was proposed. We additionally exploit the information-sharing property of a common-encoder setup to reduce computational complexity during both training and inference, improve separation performance for hard-to-generalize classes of sounds, and allow flexibility during inference time with easily detachable decoders. Our best model sets the state of the art on the Divide and Remaster dataset with performance above the ideal ratio mask for the dialogue stem.