 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the impact of stereo processing -- a study for extending the Open Dataset of Audio Quality (ODAQ)
Dec 16, 2025In this paper, we present an initial study for extending Open Dataset of Audio Quality (ODAQ) towards the impact of stereo processing. Monaural artifacts from ODAQ were adapted in combinations with left-right (LR) and mid-side (MS) stereo processing, across stimuli including solo instruments, typical wide stereo mixes and and hard-panned mixes. Listening tests in different presentation context -- with and without direct comparison of MS and LR conditions -- were conducted to collect subjective data beyond monaural artifacts while also scrutinizing the listening test methodology. The ODAQ dataset is extended with new material along with subjective scores from 16 expert listeners. The listening test results show substantial influences of the stimuli's spatial characteristics as well as the presentation context. Notably, several significant disparities between LR and MS only occur when presented in direct comparison. The findings suggest that listeners primarily assess timbral impairments when spatial characteristics are consistent and focus on stereo image only when timbral quality is similar. The rating of an additional mono anchor was overall consistent across different stereo characteristics, averaging at 65 on the MUSHRA scale, further corroborating that listeners prioritize timbral over spatial impressions.
Exploring Perceptual Audio Quality Measurement on Stereo Processing Using the Open Dataset of Audio Quality
Dec 11, 2025



ODAQ (Open Dataset of Audio Quality) provides a comprehensive framework for exploring both monaural and binaural audio quality degradations across a range of distortion classes and signals, accompanied by subjective quality ratings. A recent update of ODAQ, focusing on the impact of stereo processing methods such as Mid/Side (MS) and Left/Right (LR), provides test signals and subjective ratings for the in-depth investigation of state-of-the-art objective audio quality metrics. Our evaluation results suggest that, while timbre-focused metrics often yield robust results under simpler conditions, their prediction performance tends to suffer under the conditions with a more complex presentation context. Our findings underscore the importance of modeling the interplay of bottom-up psychoacoustic processes and top-down contextual factors, guiding future research toward models that more effectively integrate both timbral and spatial dimensions of perceived audio quality.
Expanding and Analyzing ODAQ -- the Open Dataset of Audio Quality
Apr 01, 2025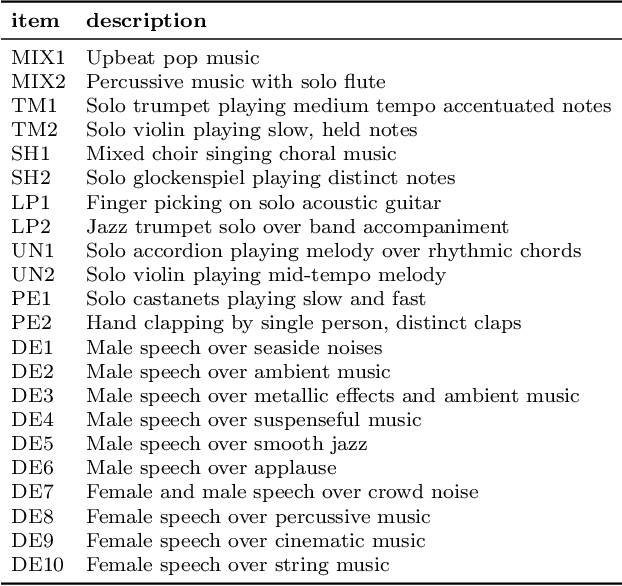

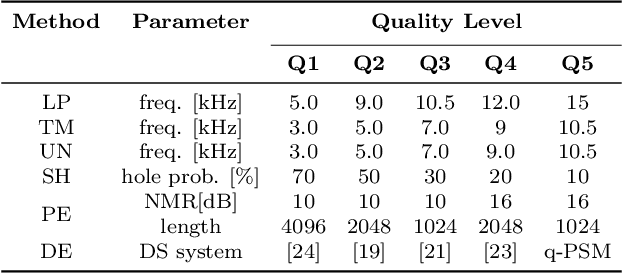

The Open Dataset of Audio Quality (ODAQ) was recently introduced to address the scarcity of openly available audio datasets with corresponding subjective quality scores. The dataset, released under permissive licenses, comprises audio material processed using six different signal processing methods operating at five quality levels, along with corresponding subjective test results. To expand the dataset, we provided listener training to university students to conduct further subjective tests and obtained results consistent with previous expert listeners. We also showed how different training approaches affect the use of absolute scales and anchors. The expanded dataset now comprises results from three international laboratories providing a total of 42 listeners and 10080 subjective scores. This paper provides the details of the expansion and an in-depth analysis. As part of this analysis, we initiate the use of ODAQ as a benchmark to evaluate objective audio quality metrics in their ability to predict subjective scores
Facing the Music: Tackling Singing Voice Separation in Cinematic Audio Source Separation
Aug 07, 2024Cinematic audio source separation (CASS) is a fairly new subtask of audio source separation. A typical setup of CASS is a three-stem problem, with the aim of separating the mixture into the dialogue stem (DX), music stem (MX), and effects stem (FX). In practice, however, several edge cases exist as some sound sources do not fit neatly in either of these three stems, necessitating the use of additional auxiliary stems in production. One very common edge case is the singing voice in film audio, which may belong in either the DX or MX, depending heavily on the cinematic context. In this work, we demonstrate a very straightforward extension of the dedicated-decoder Bandit and query-based single-decoder Banquet models to a four-stem problem, treating non-musical dialogue, instrumental music, singing voice, and effects as separate stems. Interestingly, the query-based Banquet model outperformed the dedicated-decoder Bandit model. We hypothesized that this is due to a better feature alignment at the bottleneck as enforced by the band-agnostic FiLM layer. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Remastering Divide and Remaster: A Cinematic Audio Source Separation Dataset with Multilingual Support
Jul 09, 2024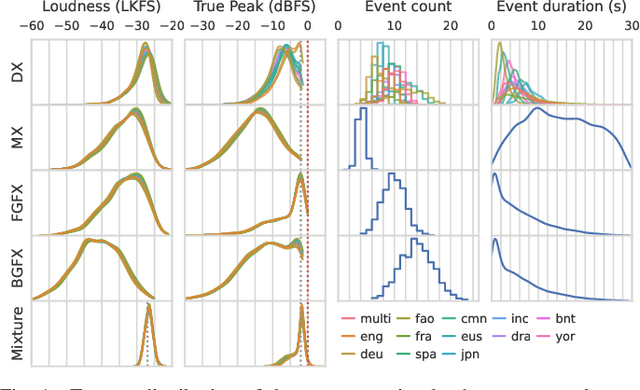
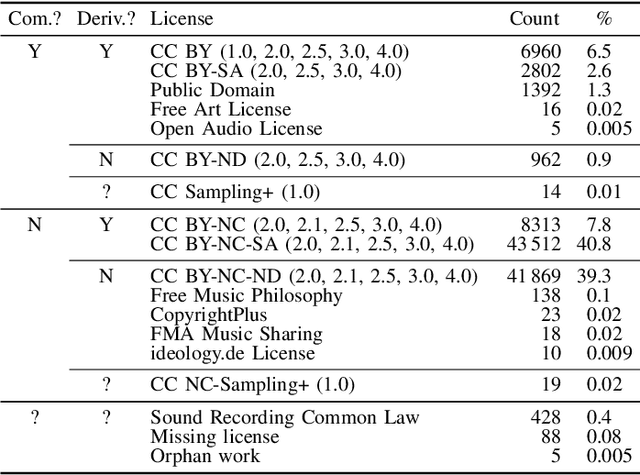
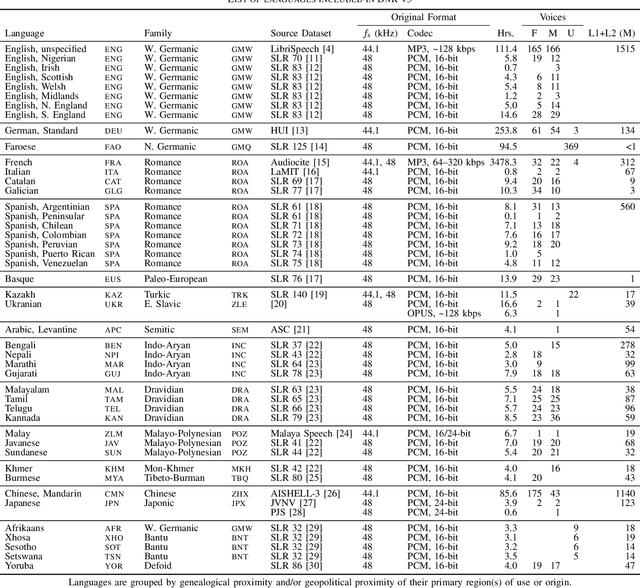
Cinematic audio source separation (CASS) is a relatively new subtask of audio source separation, concerned with the separation of a mixture into the dialogue, music, and effects stems. To date, only one publicly available dataset exists for CASS, that is, the Divide and Remaster (DnR) dataset, which is currently at version 2. While DnR v2 has been an incredibly useful resource for CASS, several areas of improvement have been identified, particularly through its use in the 2023 Sound Demixing Challenge. In this work, we develop version 3 of the DnR dataset, addressing issues relating to vocal content in non-dialogue stems, loudness distributions, mastering process, and linguistic diversity. In particular, the dialogue stem of DnR v3 includes speech content from more than 30 languages from multiple families including but not limited to the Germanic, Romance, Indo-Aryan, Dravidian, Malayo-Polynesian, and Bantu families. Benchmark results using the Bandit model indicated that training on multilingual data yields significant generalizability to the model even in languages with low data availability. Even in languages with high data availability, the multilingual model often performs on par or better than dedicated models trained on monolingual CASS datasets.
ODAQ: Open Dataset of Audio Quality
Dec 30, 2023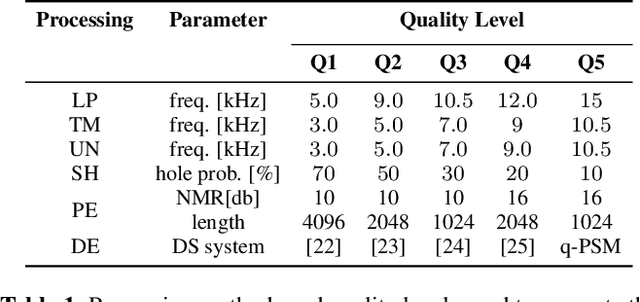
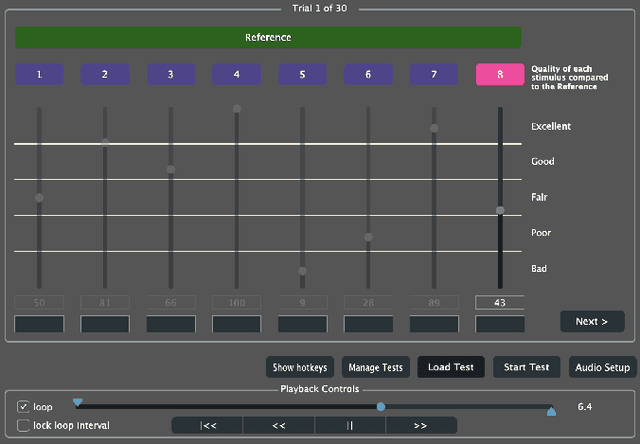
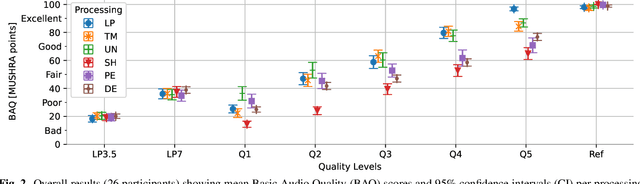
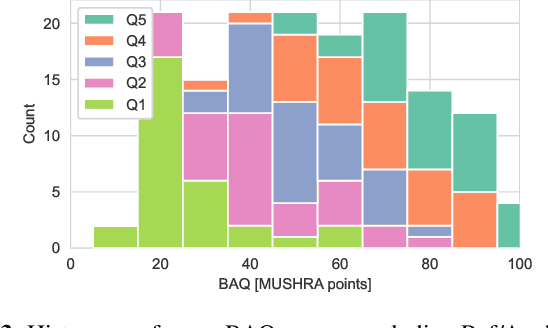
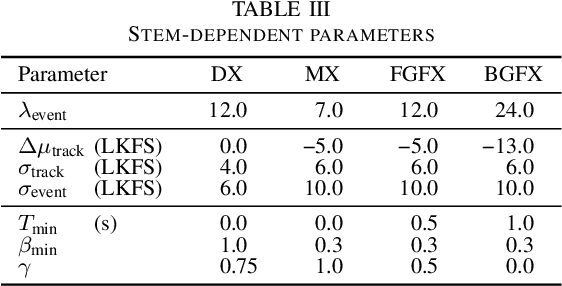
Research into the prediction and analysis of perceived audio quality is hampered by the scarcity of openly available datasets of audio signals accompanied by corresponding subjective quality scores. To address this problem, we present the Open Dataset of Audio Quality (ODAQ), a new dataset containing the results of a MUSHRA listening test conducted with expert listeners from 2 international laboratories. ODAQ contains 240 audio samples and corresponding quality scores. Each audio sample is rated by 26 listeners. The audio samples are stereo audio signals sampled at 44.1 or 48 kHz and are processed by a total of 6 method classes, each operating at different quality levels. The processing method classes are designed to generate quality degradations possibly encountered during audio coding and source separation, and the quality levels for each method class span the entire quality range. The diversity of the processing methods, the large span of quality levels, the high sampling frequency, and the pool of international listeners make ODAQ particularly suited for further research into subjective and objective audio quality. The dataset is released with permissive licenses, and the software used to conduct the listening test is also made publicly available.
A Generalized Bandsplit Neural Network for Cinematic Audio Source Separation
Sep 07, 2023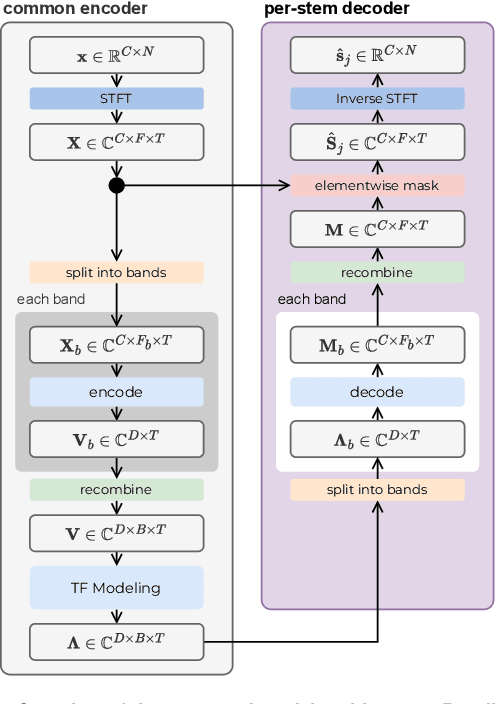
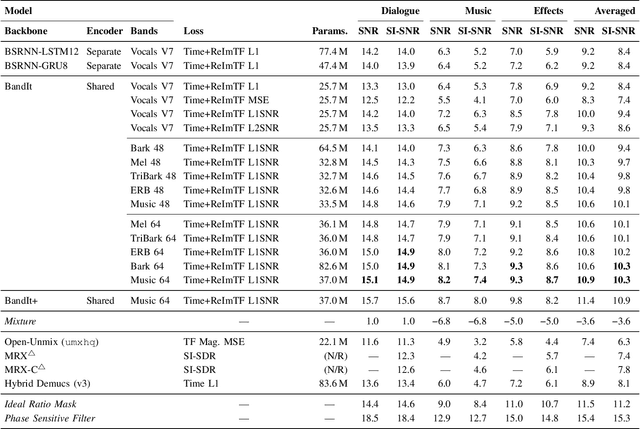
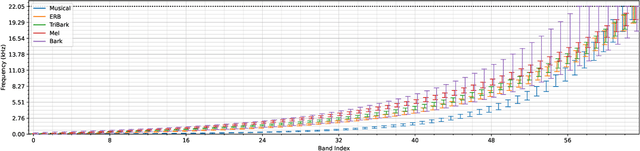

Cinematic audio source separation is a relatively new subtask of audio source separation, with the aim of extracting the dialogue stem, the music stem, and the effects stem from their mixture. In this work, we developed a model generalizing the Bandsplit RNN for any complete or overcomplete partitions of the frequency axis. Psycho-acoustically motivated frequency scales were used to inform the band definitions which are now defined with redundancy for more reliable feature extraction. A loss function motivated by the signal-to-noise ratio and the sparsity-promoting property of the 1-norm was proposed. We additionally exploit the information-sharing property of a common-encoder setup to reduce computational complexity during both training and inference, improve separation performance for hard-to-generalize classes of sounds, and allow flexibility during inference time with easily detachable decoders. Our best model sets the state of the art on the Divide and Remaster dataset with performance above the ideal ratio mask for the dialogue stem.
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Apr 12, 2023

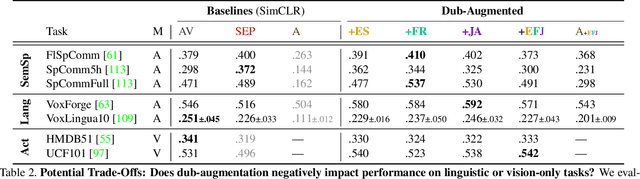

Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech content, similarly to the same video. Our results show that dub-augmented training improves performance on a range of auditory and audiovisual tasks, without significantly affecting linguistic task performance overall. We additionally compare this approach to a strong baseline where we remove speech before pretraining, and find that dub-augmented training is more effective, including for paralinguistic and audiovisual tasks where speech removal leads to worse performance. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance.
AVASpeech-SMAD: A Strongly Labelled Speech and Music Activity Detection Dataset with Label Co-Occurrence
Nov 02, 2021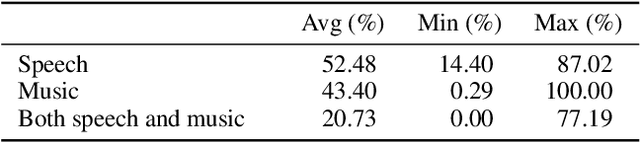
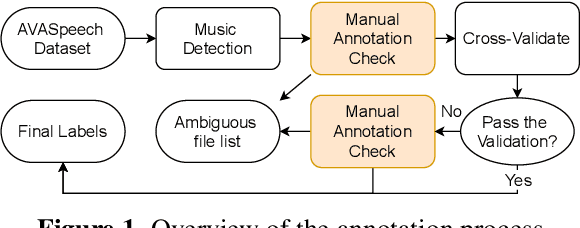

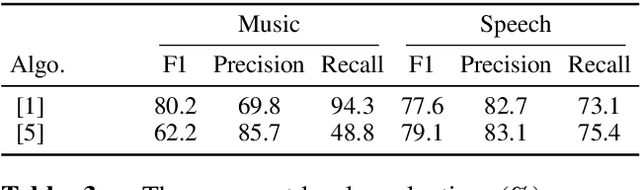
We propose a dataset, AVASpeech-SMAD, to assist speech and music activity detection research. With frame-level music labels, the proposed dataset extends the existing AVASpeech dataset, which originally consists of 45 hours of audio and speech activity labels. To the best of our knowledge, the proposed AVASpeech-SMAD is the first open-source dataset that features strong polyphonic labels for both music and speech. The dataset was manually annotated and verified via an iterative cross-checking process. A simple automatic examination was also implemented to further improve the quality of the labels. Evaluation results from two state-of-the-art SMAD systems are also provided as a benchmark for future reference.
Orientation-aware Vehicle Re-identification with Semantics-guided Part Attention Network
Aug 26, 2020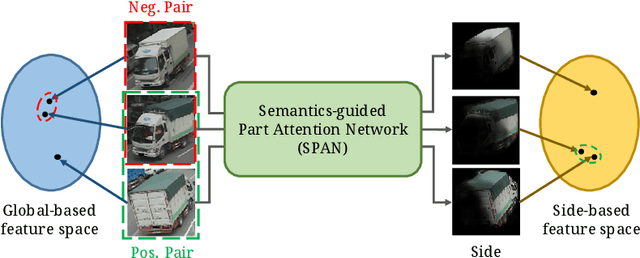


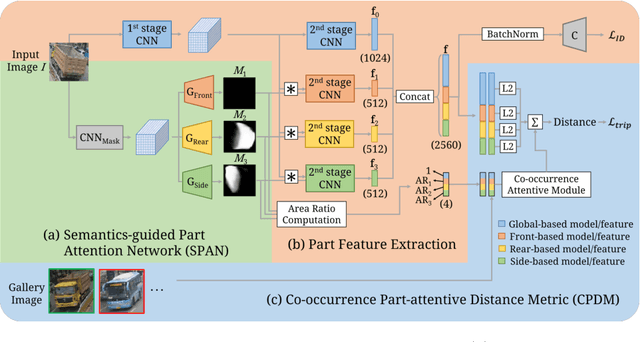
Vehicle re-identification (re-ID) focuses on matching images of the same vehicle across different cameras. It is fundamentally challenging because differences between vehicles are sometimes subtle. While several studies incorporate spatial-attention mechanisms to help vehicle re-ID, they often require expensive keypoint labels or suffer from noisy attention mask if not trained with expensive labels. In this work, we propose a dedicated Semantics-guided Part Attention Network (SPAN) to robustly predict part attention masks for different views of vehicles given only image-level semantic labels during training. With the help of part attention masks, we can extract discriminative features in each part separately. Then we introduce Co-occurrence Part-attentive Distance Metric (CPDM) which places greater emphasis on co-occurrence vehicle parts when evaluating the feature distance of two images. Extensive experiments validate the effectiveness of the proposed method and show that our framework outperforms the state-of-the-art approaches.