 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOTGNN: Interpretable Graph Neural Networks for Multi-Omics Disease Classification
Aug 10, 2025



Integrating multi-omics data, such as DNA methylation, mRNA expression, and microRNA (miRNA) expression, offers a comprehensive view of the biological mechanisms underlying disease. However, the high dimensionality and complex interactions among omics layers present major challenges for predictive modeling. We propose Multi-Omics integration with Tree-generated Graph Neural Network (MOTGNN), a novel and interpretable framework for binary disease classification. MOTGNN employs eXtreme Gradient Boosting (XGBoost) to perform omics-specific supervised graph construction, followed by modality-specific Graph Neural Networks (GNNs) for hierarchical representation learning, and a deep feedforward network for cross-omics integration. On three real-world disease datasets, MOTGNN outperforms state-of-the-art baselines by 5-10% in accuracy, ROC-AUC, and F1-score, and remains robust to severe class imbalance (e.g., 87.2% vs. 33.4% F1 on imbalanced data). The model maintains computational efficiency through sparse graphs (2.1-2.8 edges per node) and provides built-in interpretability, revealing both top-ranked biomarkers and the relative contributions of each omics modality. These results highlight MOTGNN's potential to improve both predictive accuracy and interpretability in multi-omics disease modeling.
Filter-And-Refine: A MLLM Based Cascade System for Industrial-Scale Video Content Moderation
Jul 23, 2025Effective content moderation is essential for video platforms to safeguard user experience and uphold community standards. While traditional video classification models effectively handle well-defined moderation tasks, they struggle with complicated scenarios such as implicit harmful content and contextual ambiguity. Multimodal large language models (MLLMs) offer a promising solution to these limitations with their superior cross-modal reasoning and contextual understanding. However, two key challenges hinder their industrial adoption. First, the high computational cost of MLLMs makes full-scale deployment impractical. Second, adapting generative models for discriminative classification remains an open research problem. In this paper, we first introduce an efficient method to transform a generative MLLM into a multimodal classifier using minimal discriminative training data. To enable industry-scale deployment, we then propose a router-ranking cascade system that integrates MLLMs with a lightweight router model. Offline experiments demonstrate that our MLLM-based approach improves F1 score by 66.50% over traditional classifiers while requiring only 2% of the fine-tuning data. Online evaluations show that our system increases automatic content moderation volume by 41%, while the cascading deployment reduces computational cost to only 1.5% of direct full-scale deployment.
Network Interdiction Goes Neural
May 26, 2024Network interdiction problems are combinatorial optimization problems involving two players: one aims to solve an optimization problem on a network, while the other seeks to modify the network to thwart the first player's objectives. Such problems typically emerge in an attacker-defender context, encompassing areas such as military operations, disease spread analysis, and communication network management. The primary bottleneck in network interdiction arises from the high time complexity of using conventional exact solvers and the challenges associated with devising efficient heuristic solvers. GNNs, recognized as a cutting-edge methodology, have shown significant effectiveness in addressing single-level CO problems on graphs, such as the traveling salesman problem, graph matching, and graph edit distance. Nevertheless, network interdiction presents a bi-level optimization challenge, which current GNNs find difficult to manage. To address this gap, we represent network interdiction problems as Mixed-Integer Linear Programming (MILP) instances, then apply a multipartite GNN with sufficient representational capacity to learn these formulations. This approach ensures that our neural network is more compatible with the mathematical algorithms designed to solve network interdiction problems, resulting in improved generalization. Through two distinct tasks, we demonstrate that our proposed method outperforms theoretical baseline models and provides advantages over traditional exact solvers.
Bayesian-Guided Generation of Synthetic Microbiomes with Minimized Pathogenicity
Apr 29, 2024
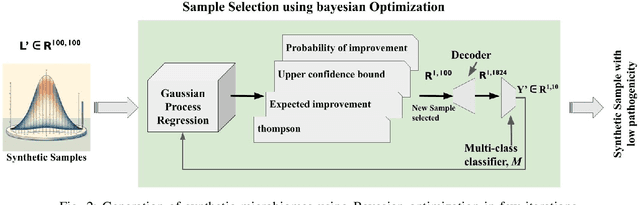
Synthetic microbiomes offer new possibilities for modulating microbiota, to address the barriers in multidtug resistance (MDR) research. We present a Bayesian optimization approach to enable efficient searching over the space of synthetic microbiome variants to identify candidates predictive of reduced MDR. Microbiome datasets were encoded into a low-dimensional latent space using autoencoders. Sampling from this space allowed generation of synthetic microbiome signatures. Bayesian optimization was then implemented to select variants for biological screening to maximize identification of designs with restricted MDR pathogens based on minimal samples. Four acquisition functions were evaluated: expected improvement, upper confidence bound, Thompson sampling, and probability of improvement. Based on each strategy, synthetic samples were prioritized according to their MDR detection. Expected improvement, upper confidence bound, and probability of improvement consistently produced synthetic microbiome candidates with significantly fewer searches than Thompson sampling. By combining deep latent space mapping and Bayesian learning for efficient guided screening, this study demonstrated the feasibility of creating bespoke synthetic microbiomes with customized MDR profiles.
Multiple-Source Localization from a Single-Snapshot Observation Using Graph Bayesian Optimization
Mar 25, 2024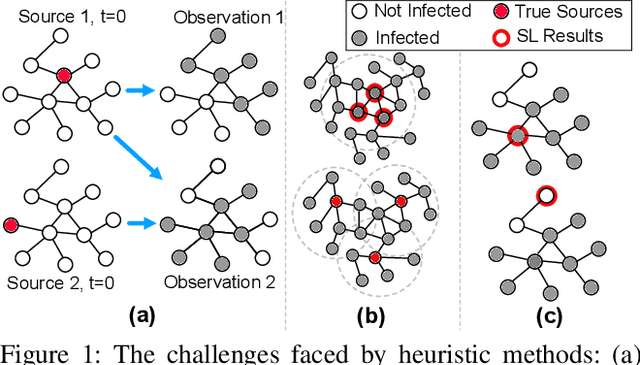
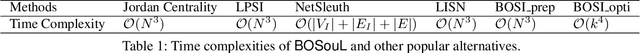
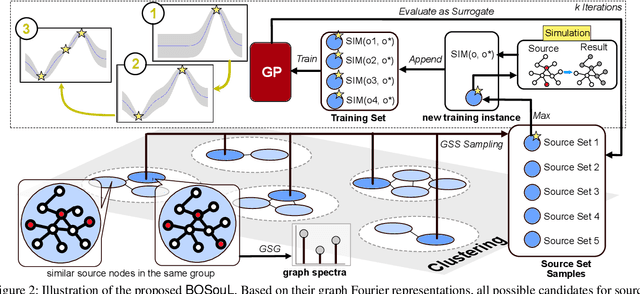
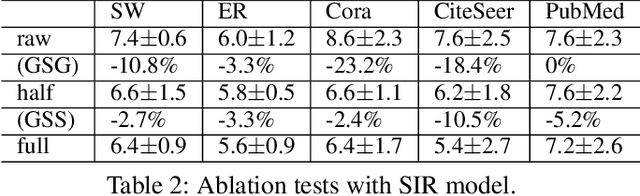
Due to the significance of its various applications, source localization has garnered considerable attention as one of the most important means to confront diffusion hazards. Multi-source localization from a single-snapshot observation is especially relevant due to its prevalence. However, the inherent complexities of this problem, such as limited information, interactions among sources, and dependence on diffusion models, pose challenges to resolution. Current methods typically utilize heuristics and greedy selection, and they are usually bonded with one diffusion model. Consequently, their effectiveness is constrained. To address these limitations, we propose a simulation-based method termed BOSouL. Bayesian optimization (BO) is adopted to approximate the results for its sample efficiency. A surrogate function models uncertainty from the limited information. It takes sets of nodes as the input instead of individual nodes. BOSouL can incorporate any diffusion model in the data acquisition process through simulations. Empirical studies demonstrate that its performance is robust across graph structures and diffusion models. The code is available at https://github.com/XGraph-Team/BOSouL.
Graph Bayesian Optimization for Multiplex Influence Maximization
Mar 25, 2024



Influence maximization (IM) is the problem of identifying a limited number of initial influential users within a social network to maximize the number of influenced users. However, previous research has mostly focused on individual information propagation, neglecting the simultaneous and interactive dissemination of multiple information items. In reality, when users encounter a piece of information, such as a smartphone product, they often associate it with related products in their minds, such as earphones or computers from the same brand. Additionally, information platforms frequently recommend related content to users, amplifying this cascading effect and leading to multiplex influence diffusion. This paper first formulates the Multiplex Influence Maximization (Multi-IM) problem using multiplex diffusion models with an information association mechanism. In this problem, the seed set is a combination of influential users and information. To effectively manage the combinatorial complexity, we propose Graph Bayesian Optimization for Multi-IM (GBIM). The multiplex diffusion process is thoroughly investigated using a highly effective global kernelized attention message-passing module. This module, in conjunction with Bayesian linear regression (BLR), produces a scalable surrogate model. A data acquisition module incorporating the exploration-exploitation trade-off is developed to optimize the seed set further. Extensive experiments on synthetic and real-world datasets have proven our proposed framework effective. The code is available at https://github.com/zirui-yuan/GBIM.
Towards Interpreting Multi-Objective Feature Associations
Feb 28, 2024
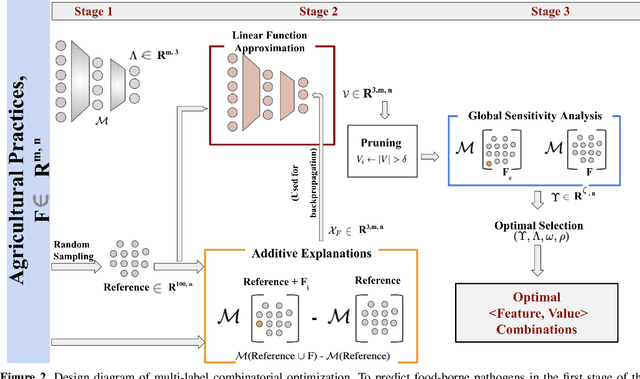

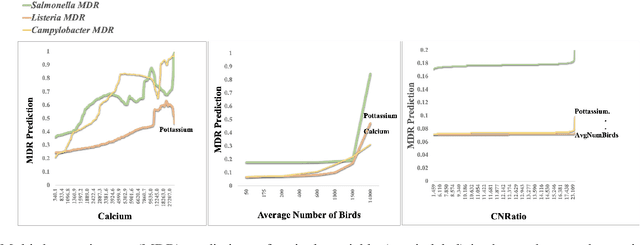
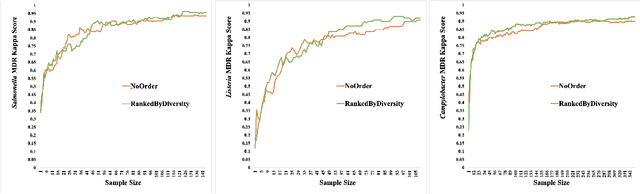
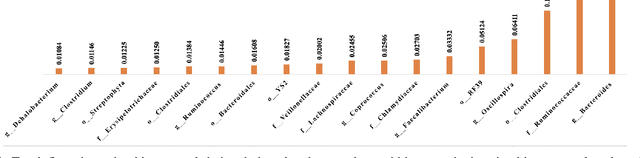
Understanding how multiple features are associated and contribute to a specific objective is as important as understanding how each feature contributes to a particular outcome. Interpretability of a single feature in a prediction may be handled in multiple ways; however, in a multi-objective prediction, it is difficult to obtain interpretability of a combination of feature values. To address this issue, we propose an objective specific feature interaction design using multi-labels to find the optimal combination of features in agricultural settings. One of the novel aspects of this design is the identification of a method that integrates feature explanations with global sensitivity analysis in order to ensure combinatorial optimization in multi-objective settings. We have demonstrated in our preliminary experiments that an approximate combination of feature values can be found to achieve the desired outcome using two agricultural datasets: one with pre-harvest poultry farm practices for multi-drug resistance presence, and one with post-harvest poultry farm practices for food-borne pathogens. In our combinatorial optimization approach, all three pathogens are taken into consideration simultaneously to account for the interaction between conditions that favor different types of pathogen growth. These results indicate that explanation-based approaches are capable of identifying combinations of features that reduce pathogen presence in fewer iterations than a baseline.
Deep Sensitivity Analysis for Objective-Oriented Combinatorial Optimization
Feb 28, 2024Pathogen control is a critical aspect of modern poultry farming, providing important benefits for both public health and productivity. Effective poultry management measures to reduce pathogen levels in poultry flocks promote food safety by lowering risks of food-borne illnesses. They also support animal health and welfare by preventing infectious diseases that can rapidly spread and impact flock growth, egg production, and overall health. This study frames the search for optimal management practices that minimize the presence of multiple pathogens as a combinatorial optimization problem. Specifically, we model the various possible combinations of management settings as a solution space that can be efficiently explored to identify configurations that optimally reduce pathogen levels. This design incorporates a neural network feedback-based method that combines feature explanations with global sensitivity analysis to ensure combinatorial optimization in multiobjective settings. Our preliminary experiments have promising results when applied to two real-world agricultural datasets. While further validation is still needed, these early experimental findings demonstrate the potential of the model to derive targeted feature interactions that adaptively optimize pathogen control under varying real-world constraints.
XFlow: Benchmarking Flow Behaviors over Graphs
Aug 07, 2023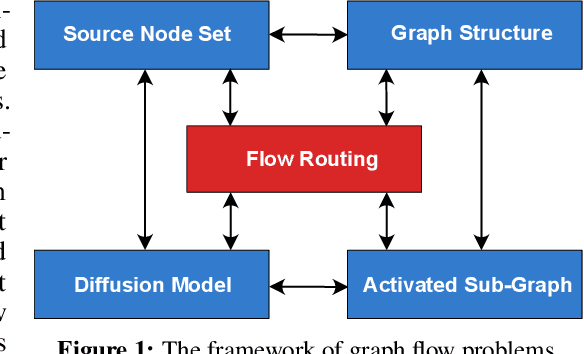
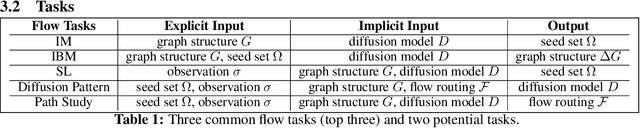
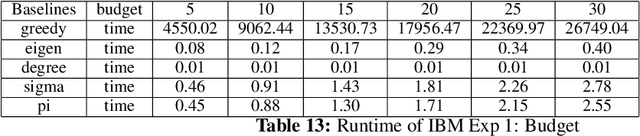
The occurrence of diffusion on a graph is a prevalent and significant phenomenon, as evidenced by the spread of rumors, influenza-like viruses, smart grid failures, and similar events. Comprehending the behaviors of flow is a formidable task, due to the intricate interplay between the distribution of seeds that initiate flow propagation, the propagation model, and the topology of the graph. The study of networks encompasses a diverse range of academic disciplines, including mathematics, physics, social science, and computer science. This interdisciplinary nature of network research is characterized by a high degree of specialization and compartmentalization, and the cooperation facilitated by them is inadequate. From a machine learning standpoint, there is a deficiency in a cohesive platform for assessing algorithms across various domains. One of the primary obstacles to current research in this field is the absence of a comprehensive curated benchmark suite to study the flow behaviors under network scenarios. To address this disparity, we propose the implementation of a novel benchmark suite that encompasses a variety of tasks, baseline models, graph datasets, and evaluation tools. In addition, we present a comprehensive analytical framework that offers a generalized approach to numerous flow-related tasks across diverse domains, serving as a blueprint and roadmap. Drawing upon the outcomes of our empirical investigation, we analyze the advantages and disadvantages of current foundational models, and we underscore potential avenues for further study. The datasets, code, and baseline models have been made available for the public at: https://github.com/XGraphing/XFlow
Deep representation learning: Fundamentals, Perspectives, Applications, and Open Challenges
Nov 27, 2022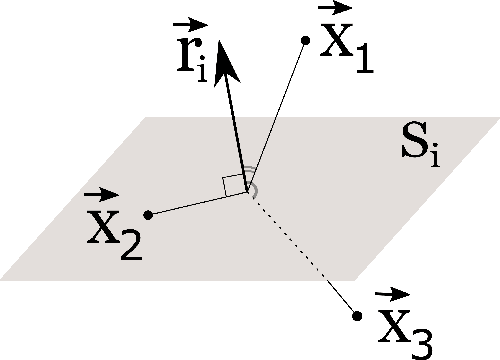
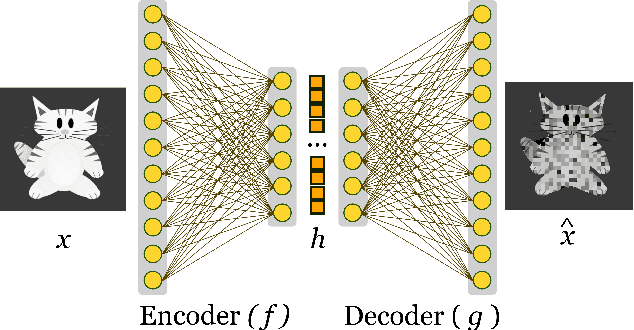
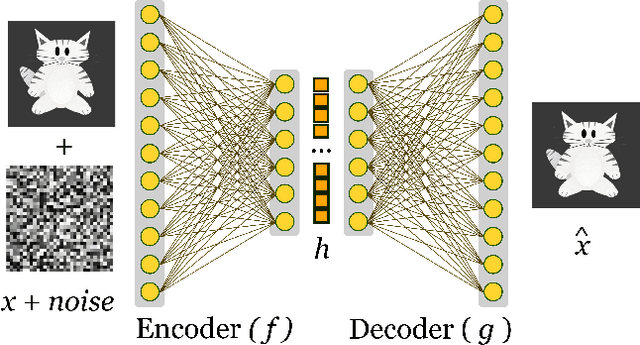
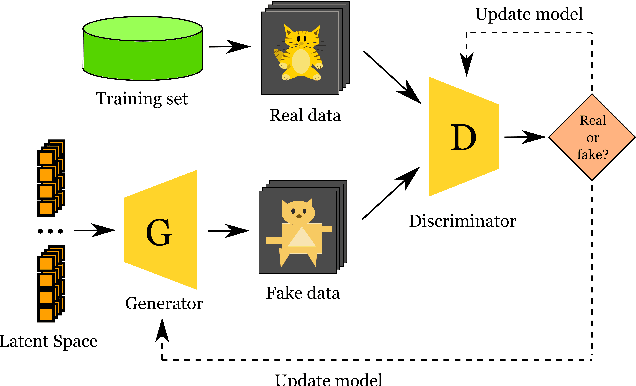
Machine Learning algorithms have had a profound impact on the field of computer science over the past few decades. These algorithms performance is greatly influenced by the representations that are derived from the data in the learning process. The representations learned in a successful learning process should be concise, discrete, meaningful, and able to be applied across a variety of tasks. A recent effort has been directed toward developing Deep Learning models, which have proven to be particularly effective at capturing high-dimensional, non-linear, and multi-modal characteristics. In this work, we discuss the principles and developments that have been made in the process of learning representations, and converting them into desirable applications. In addition, for each framework or model, the key issues and open challenges, as well as the advantages, are examined.