 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTART: Improved Few-shot Text Classification Using Task-Adaptive Reference Transformation
Jun 03, 2023

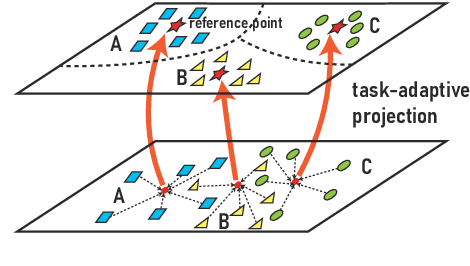
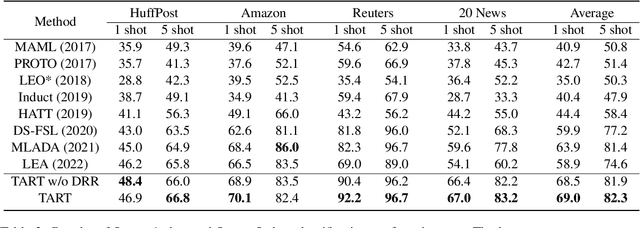
Meta-learning has emerged as a trending technique to tackle few-shot text classification and achieve state-of-the-art performance. However, the performance of existing approaches heavily depends on the inter-class variance of the support set. As a result, it can perform well on tasks when the semantics of sampled classes are distinct while failing to differentiate classes with similar semantics. In this paper, we propose a novel Task-Adaptive Reference Transformation (TART) network, aiming to enhance the generalization by transforming the class prototypes to per-class fixed reference points in task-adaptive metric spaces. To further maximize divergence between transformed prototypes in task-adaptive metric spaces, TART introduces a discriminative reference regularization among transformed prototypes. Extensive experiments are conducted on four benchmark datasets and our method demonstrates clear superiority over the state-of-the-art models in all the datasets. In particular, our model surpasses the state-of-the-art method by 7.4% and 5.4% in 1-shot and 5-shot classification on the 20 Newsgroups dataset, respectively.
Memetic algorithms for Spatial Partitioning problems
Aug 04, 2022

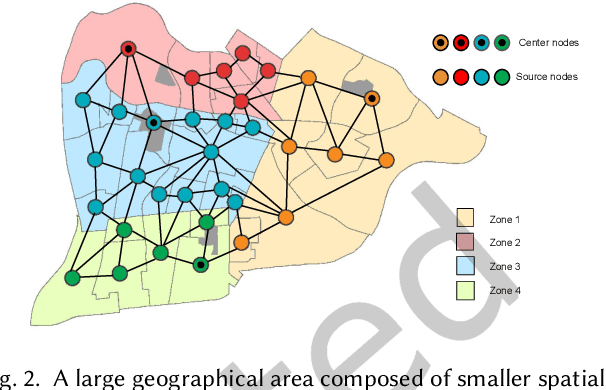
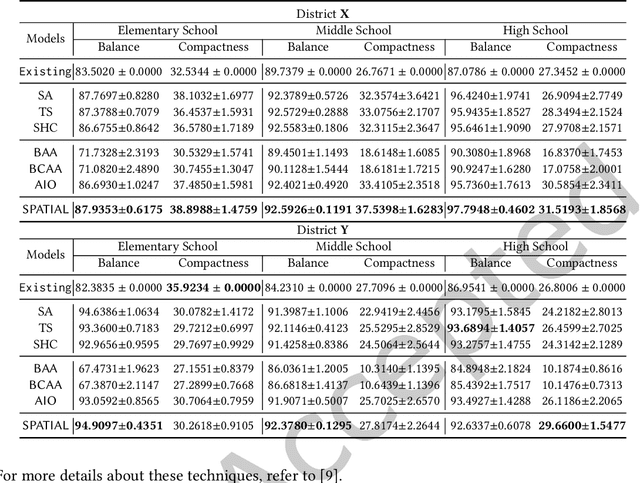
Spatial optimization problems (SOPs) are characterized by spatial relationships governing the decision variables, objectives, and/or constraint functions. In this article, we focus on a specific type of SOP called spatial partitioning, which is a combinatorial problem due to the presence of discrete spatial units. Exact optimization methods do not scale with the size of the problem, especially within practicable time limits. This motivated us to develop population-based metaheuristics for solving such SOPs. However, the search operators employed by these population-based methods are mostly designed for real-parameter continuous optimization problems. For adapting these methods to SOPs, we apply domain knowledge in designing spatially-aware search operators for efficiently searching through the discrete search space while preserving the spatial constraints. To this end, we put forward a simple yet effective algorithm called swarm-based spatial memetic algorithm (SPATIAL) and test it on the school (re)districting problem. Detailed experimental investigations are performed on real-world datasets to evaluate the performance of SPATIAL. Besides, ablation studies are performed to understand the role of the individual components of SPATIAL. Additionally, we discuss how SPATIAL~is helpful in the real-life planning process and its applicability to different scenarios and motivate future research directions.
Sampling-based techniques for designing school boundaries
Jun 08, 2022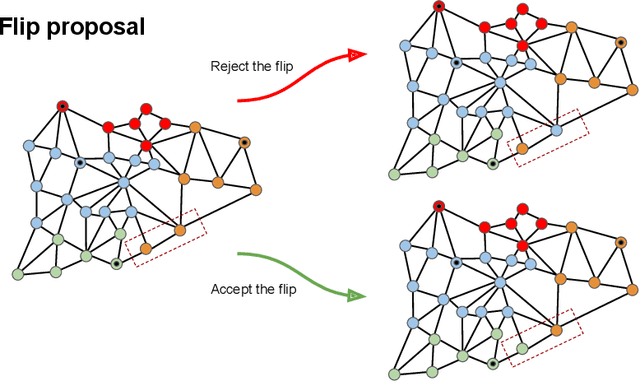
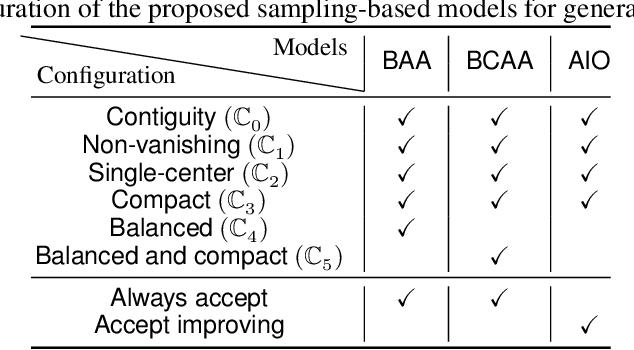
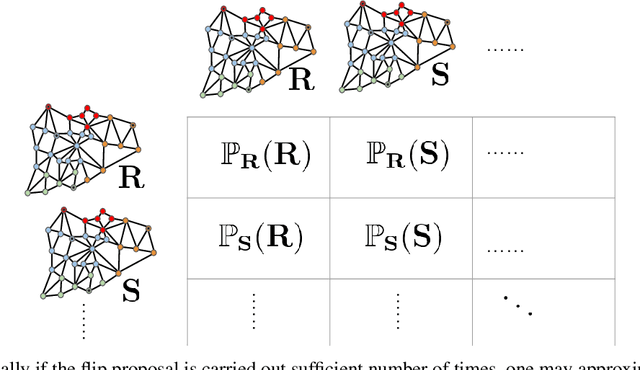

Recently, an increasing number of researchers, especially in the realm of political redistricting, have proposed sampling-based techniques to generate a subset of plans from the vast space of districting plans. These techniques have been increasingly adopted by U.S. courts of law and independent commissions as a tool for identifying partisan gerrymanders. Motivated by these recent developments, we develop a set of similar sampling techniques for designing school boundaries based on the flip proposal. Note that the flip proposal here refers to the change in the districting plan by a single assignment. These sampling-based techniques serve a dual purpose. They can be used as a baseline for comparing redistricting algorithms based on local search. Additionally, these techniques can help to infer the problem characteristics that may be further used for developing efficient redistricting methods. We empirically touch on both these aspects in regards to the problem of school redistricting.
Automated Urban Planning for Reimagining City Configuration via Adversarial Learning: Quantification, Generation, and Evaluation
Dec 26, 2021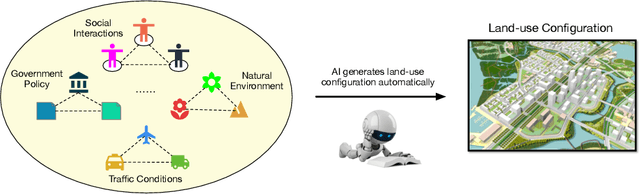
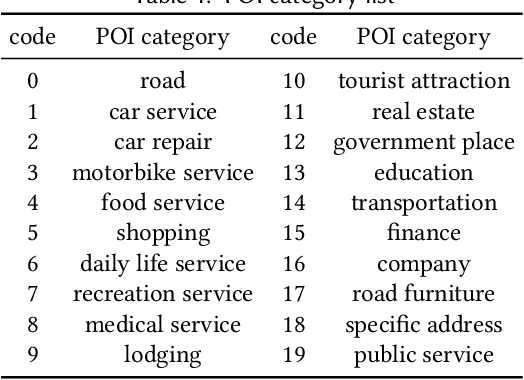
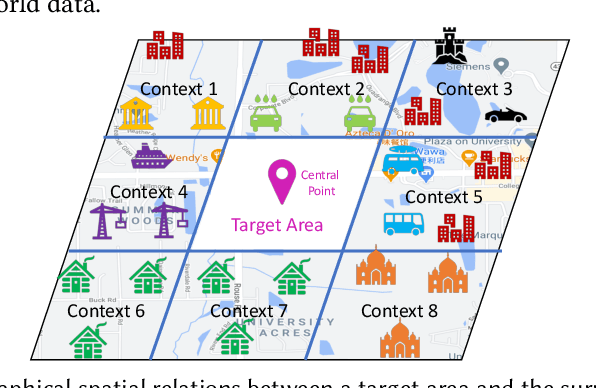
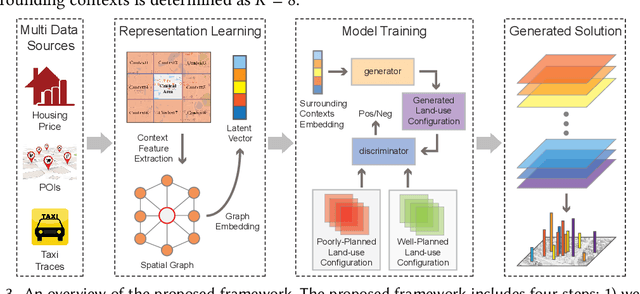
Urban planning refers to the efforts of designing land-use configurations given a region. However, to obtain effective urban plans, urban experts have to spend much time and effort analyzing sophisticated planning constraints based on domain knowledge and personal experiences. To alleviate the heavy burden of them and produce consistent urban plans, we want to ask that can AI accelerate the urban planning process, so that human planners only adjust generated configurations for specific needs? The recent advance of deep generative models provides a possible answer, which inspires us to automate urban planning from an adversarial learning perspective. However, three major challenges arise: 1) how to define a quantitative land-use configuration? 2) how to automate configuration planning? 3) how to evaluate the quality of a generated configuration? In this paper, we systematically address the three challenges. Specifically, 1) We define a land-use configuration as a longitude-latitude-channel tensor. 2) We formulate the automated urban planning problem into a task of deep generative learning. The objective is to generate a configuration tensor given the surrounding contexts of a target region. 3) We provide quantitative evaluation metrics and conduct extensive experiments to demonstrate the effectiveness of our framework.
Deep diffusion-based forecasting of COVID-19 by incorporating network-level mobility information
Nov 09, 2021



Modeling the spatiotemporal nature of the spread of infectious diseases can provide useful intuition in understanding the time-varying aspect of the disease spread and the underlying complex spatial dependency observed in people's mobility patterns. Besides, the county level multiple related time series information can be leveraged to make a forecast on an individual time series. Adding to this challenge is the fact that real-time data often deviates from the unimodal Gaussian distribution assumption and may show some complex mixed patterns. Motivated by this, we develop a deep learning-based time-series model for probabilistic forecasting called Auto-regressive Mixed Density Dynamic Diffusion Network(ARM3Dnet), which considers both people's mobility and disease spread as a diffusion process on a dynamic directed graph. The Gaussian Mixture Model layer is implemented to consider the multimodal nature of the real-time data while learning from multiple related time series. We show that our model, when trained with the best combination of dynamic covariate features and mixture components, can outperform both traditional statistical and deep learning models in forecasting the number of Covid-19 deaths and cases at the county level in the United States.
* 8 pages
Bridging the Gap between Spatial and Spectral Domains: A Unified Framework for Graph Neural Networks
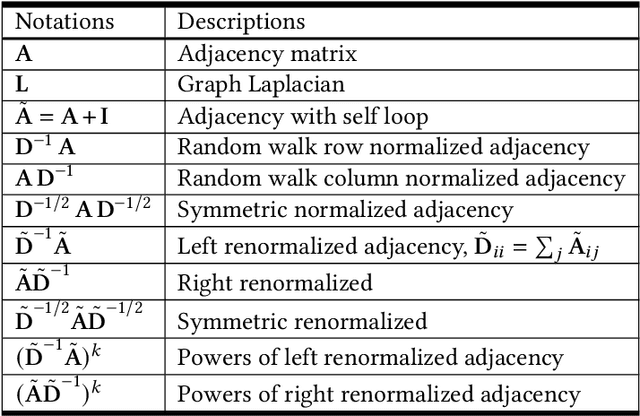
Aug 07, 2021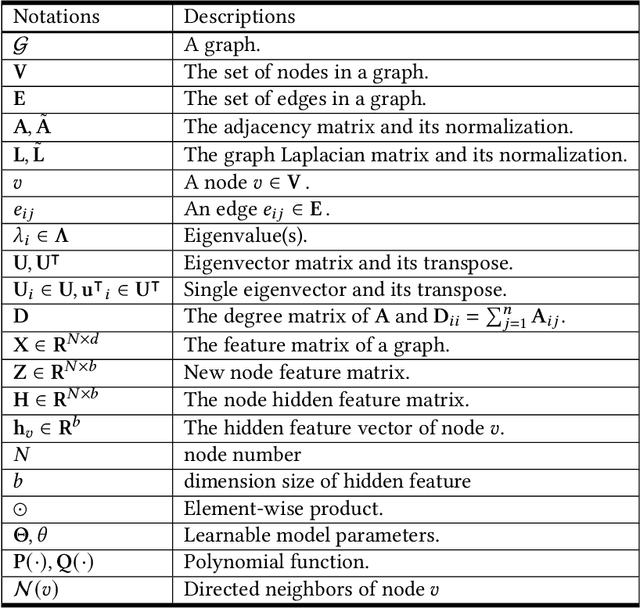

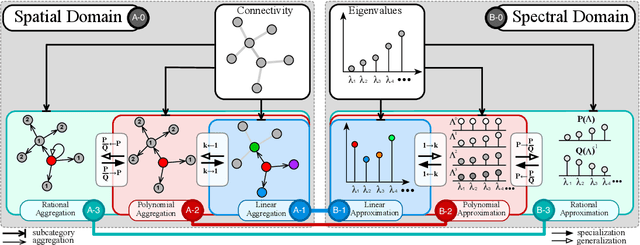
Deep learning's performance has been extensively recognized recently. Graph neural networks (GNNs) are designed to deal with graph-structural data that classical deep learning does not easily manage. Since most GNNs were created using distinct theories, direct comparisons are impossible. Prior research has primarily concentrated on categorizing existing models, with little attention paid to their intrinsic connections. The purpose of this study is to establish a unified framework that integrates GNNs based on spectral graph and approximation theory. The framework incorporates a strong integration between spatial- and spectral-based GNNs while tightly associating approaches that exist within each respective domain.
Few-Shot Semantic Segmentation Augmented with Image-Level Weak Annotations
Jul 03, 2020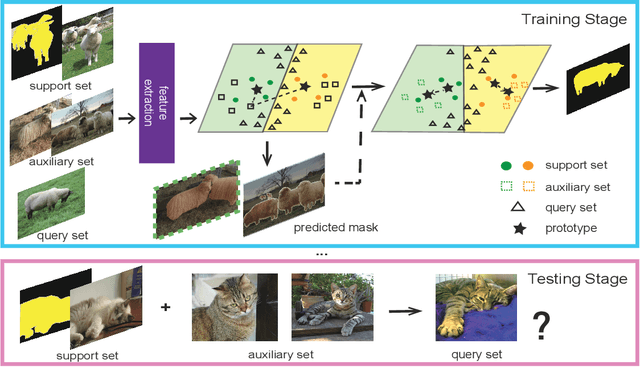
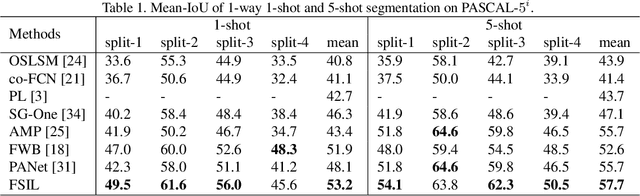
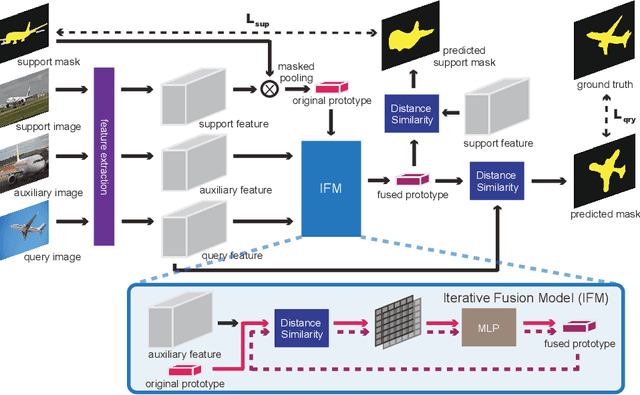

Despite the great progress made by deep neural networks in the semantic segmentation task, traditional neural network-based methods typically suffer from a shortage of large amounts of pixel-level annotations. Recent progress in few-shot semantic segmentation tackles the issue by utilizing only a few pixel-level annotated examples. However, these few-shot approaches cannot easily be applied to utilize image-level weak annotations, which can easily be obtained and considerably improve performance in the semantic segmentation task. In this paper, we advance the few-shot segmentation paradigm towards a scenario where image-level annotations are available to help the training process of a few pixel-level annotations. Specifically, we propose a new framework to learn the class prototype representation in the metric space by integrating image-level annotations. Furthermore, a soft masked average pooling strategy is designed to handle distractions in image-level annotations. Extensive empirical results on PASCAL-5i show that our method can achieve 5.1% and 8.2% increases of mIoU score for one-shot settings with pixel-level and scribble annotations, respectively.
Bridging the Gap between Spatial and Spectral Domains: A Survey on Graph Neural Networks
Mar 01, 2020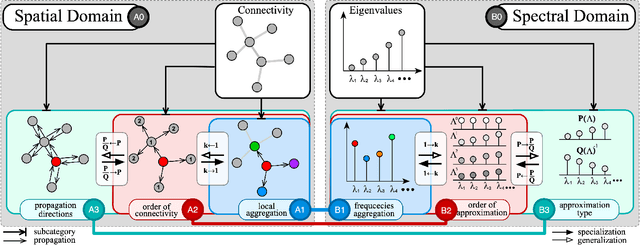
The success of deep learning has been widely recognized in many machine learning tasks during the last decades, ranging from image classification and speech recognition to natural language understanding. As an extension of deep learning, Graph neural networks (GNNs) are designed to solve the non-Euclidean problems on graph-structured data which can hardly be handled by general deep learning techniques. Existing GNNs under various mechanisms, such as random walk, PageRank, graph convolution, and heat diffusion, are designed for different types of graphs and problems, which makes it difficult to compare them directly. Previous GNN surveys focus on categorizing current models into independent groups, lacking analysis regarding their internal connection. This paper proposes a unified framework and provides a novel perspective that can widely fit existing GNNs into our framework methodologically. Specifically, we survey and categorize existing GNN models into the spatial and spectral domains, and reveal connections among subcategories in each domain. Further analysis establishes a strong link across the spatial and spectral domains.
Mitigating Uncertainty in Document Classification
Jul 17, 2019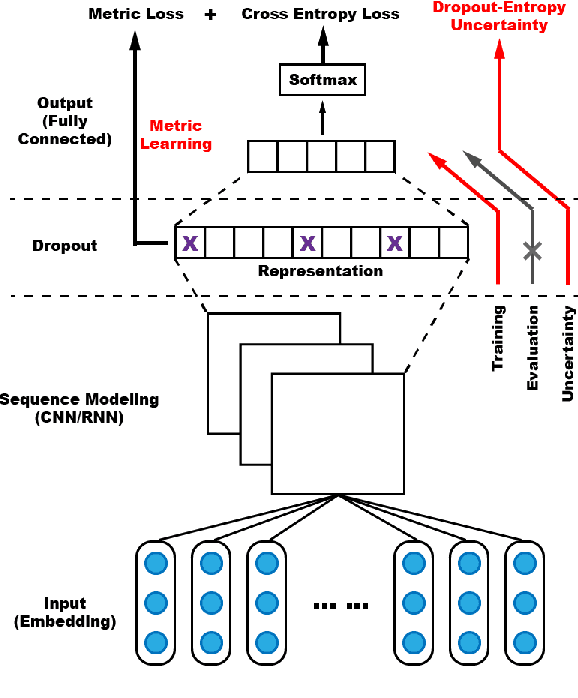
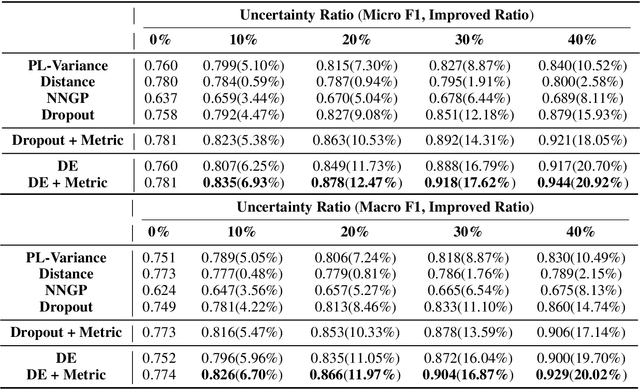
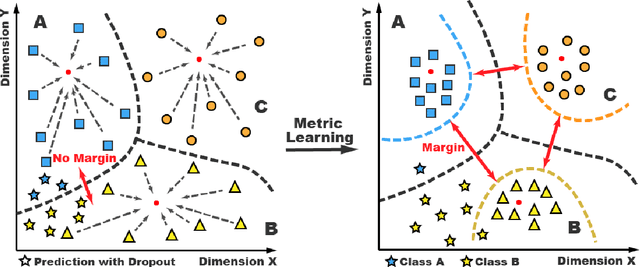
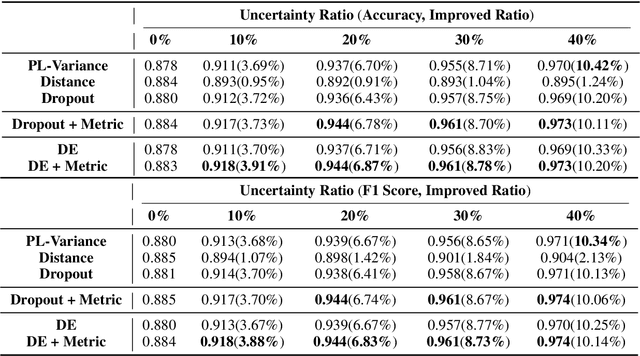
The uncertainty measurement of classifiers' predictions is especially important in applications such as medical diagnoses that need to ensure limited human resources can focus on the most uncertain predictions returned by machine learning models. However, few existing uncertainty models attempt to improve overall prediction accuracy where human resources are involved in the text classification task. In this paper, we propose a novel neural-network-based model that applies a new dropout-entropy method for uncertainty measurement. We also design a metric learning method on feature representations, which can boost the performance of dropout-based uncertainty methods with smaller prediction variance in accurate prediction trials. Extensive experiments on real-world data sets demonstrate that our method can achieve a considerable improvement in overall prediction accuracy compared to existing approaches. In particular, our model improved the accuracy from 0.78 to 0.92 when 30\% of the most uncertain predictions were handed over to human experts in "20NewsGroup" data.