 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemetic algorithms for Spatial Partitioning problems
Aug 04, 2022

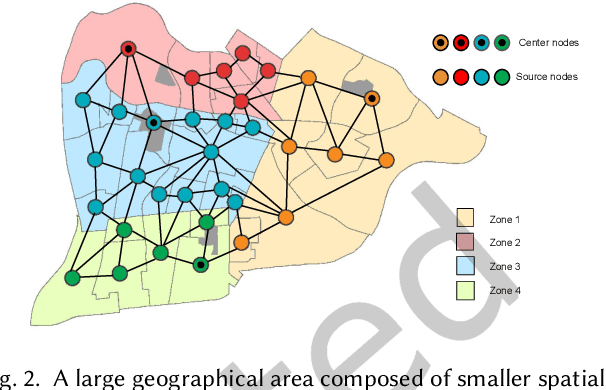
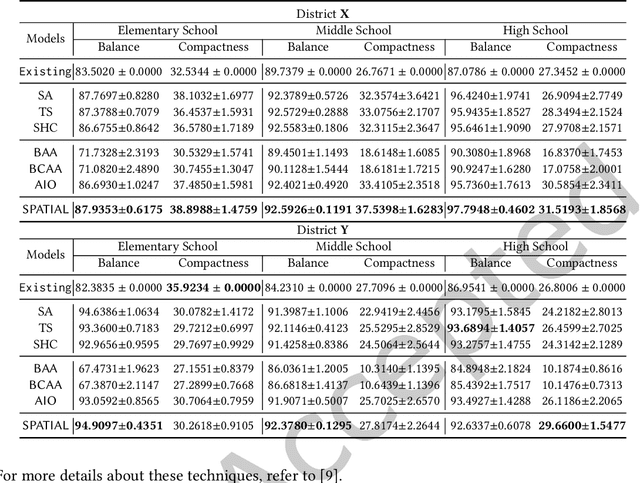
Spatial optimization problems (SOPs) are characterized by spatial relationships governing the decision variables, objectives, and/or constraint functions. In this article, we focus on a specific type of SOP called spatial partitioning, which is a combinatorial problem due to the presence of discrete spatial units. Exact optimization methods do not scale with the size of the problem, especially within practicable time limits. This motivated us to develop population-based metaheuristics for solving such SOPs. However, the search operators employed by these population-based methods are mostly designed for real-parameter continuous optimization problems. For adapting these methods to SOPs, we apply domain knowledge in designing spatially-aware search operators for efficiently searching through the discrete search space while preserving the spatial constraints. To this end, we put forward a simple yet effective algorithm called swarm-based spatial memetic algorithm (SPATIAL) and test it on the school (re)districting problem. Detailed experimental investigations are performed on real-world datasets to evaluate the performance of SPATIAL. Besides, ablation studies are performed to understand the role of the individual components of SPATIAL. Additionally, we discuss how SPATIAL~is helpful in the real-life planning process and its applicability to different scenarios and motivate future research directions.
Lessons from Deep Learning applied to Scholarly Information Extraction: What Works, What Doesn't, and Future Directions
Jul 08, 2022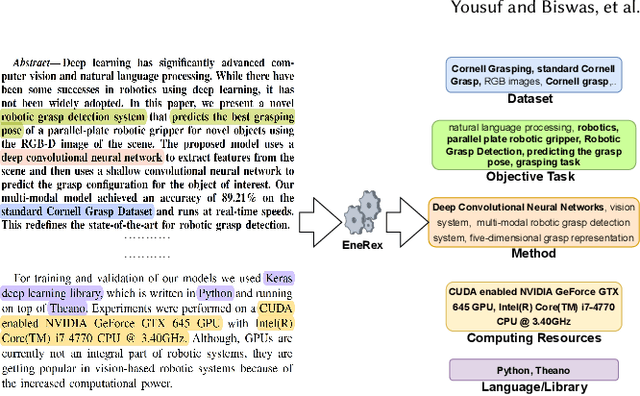

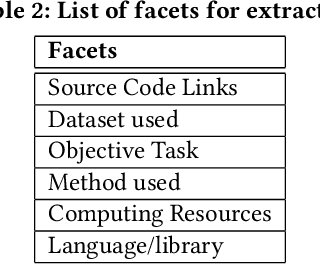
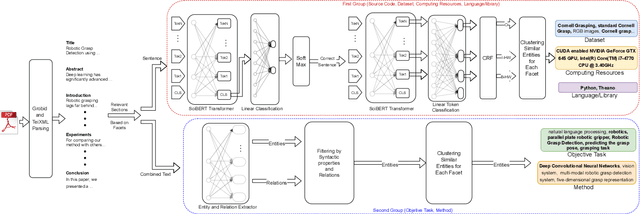
Understanding key insights from full-text scholarly articles is essential as it enables us to determine interesting trends, give insight into the research and development, and build knowledge graphs. However, some of the interesting key insights are only available when considering full-text. Although researchers have made significant progress in information extraction from short documents, extraction of scientific entities from full-text scholarly literature remains a challenging problem. This work presents an automated End-to-end Research Entity Extractor called EneRex to extract technical facets such as dataset usage, objective task, method from full-text scholarly research articles. Additionally, we extracted three novel facets, e.g., links to source code, computing resources, programming language/libraries from full-text articles. We demonstrate how EneRex is able to extract key insights and trends from a large-scale dataset in the domain of computer science. We further test our pipeline on multiple datasets and found that the EneRex improves upon a state of the art model. We highlight how the existing datasets are limited in their capacity and how EneRex may fit into an existing knowledge graph. We also present a detailed discussion with pointers for future research. Our code and data are publicly available at https://github.com/DiscoveryAnalyticsCenter/EneRex.
Sampling-based techniques for designing school boundaries
Jun 08, 2022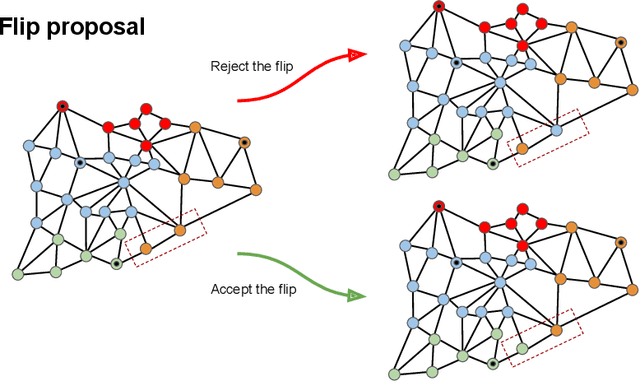
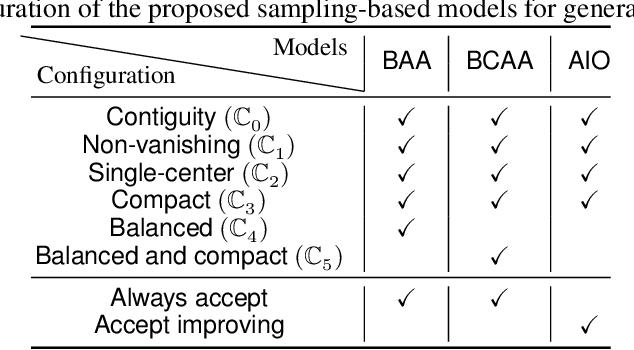

Recently, an increasing number of researchers, especially in the realm of political redistricting, have proposed sampling-based techniques to generate a subset of plans from the vast space of districting plans. These techniques have been increasingly adopted by U.S. courts of law and independent commissions as a tool for identifying partisan gerrymanders. Motivated by these recent developments, we develop a set of similar sampling techniques for designing school boundaries based on the flip proposal. Note that the flip proposal here refers to the change in the districting plan by a single assignment. These sampling-based techniques serve a dual purpose. They can be used as a baseline for comparing redistricting algorithms based on local search. Additionally, these techniques can help to infer the problem characteristics that may be further used for developing efficient redistricting methods. We empirically touch on both these aspects in regards to the problem of school redistricting.
Deep diffusion-based forecasting of COVID-19 by incorporating network-level mobility information
Nov 09, 2021



Modeling the spatiotemporal nature of the spread of infectious diseases can provide useful intuition in understanding the time-varying aspect of the disease spread and the underlying complex spatial dependency observed in people's mobility patterns. Besides, the county level multiple related time series information can be leveraged to make a forecast on an individual time series. Adding to this challenge is the fact that real-time data often deviates from the unimodal Gaussian distribution assumption and may show some complex mixed patterns. Motivated by this, we develop a deep learning-based time-series model for probabilistic forecasting called Auto-regressive Mixed Density Dynamic Diffusion Network(ARM3Dnet), which considers both people's mobility and disease spread as a diffusion process on a dynamic directed graph. The Gaussian Mixture Model layer is implemented to consider the multimodal nature of the real-time data while learning from multiple related time series. We show that our model, when trained with the best combination of dynamic covariate features and mixture components, can outperform both traditional statistical and deep learning models in forecasting the number of Covid-19 deaths and cases at the county level in the United States.
* 8 pages
Better call Surrogates: A hybrid Evolutionary Algorithm for Hyperparameter optimization
Dec 11, 2020
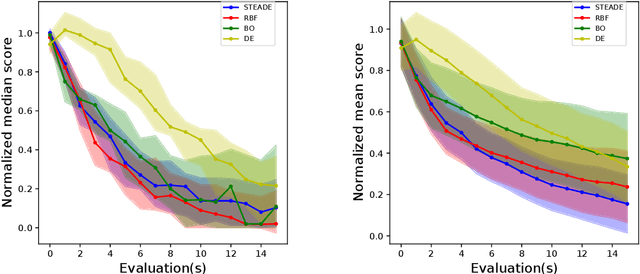
In this paper, we propose a surrogate-assisted evolutionary algorithm (EA) for hyperparameter optimization of machine learning (ML) models. The proposed STEADE model initially estimates the objective function landscape using RadialBasis Function interpolation, and then transfers the knowledge to an EA technique called Differential Evolution that is used to evolve new solutions guided by a Bayesian optimization framework. We empirically evaluate our model on the hyperparameter optimization problems as a part of the black box optimization challenge at NeurIPS 2020 and demonstrate the improvement brought about by STEADE over the vanilla EA.