 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Refinement of E-commerce Search Ranking Based on Short-Term Activities of the Buyer
Dec 15, 2025In e-commerce shopping, aligning search results with a buyer's immediate needs and preferences presents a significant challenge, particularly in adapting search results throughout the buyer's shopping journey as they move from the initial stages of browsing to making a purchase decision or shift from one intent to another. This study presents a systematic approach to adapting e-commerce search results based on the current context. We start with basic methods and incrementally incorporate more contextual information and state-of-the-art techniques to improve the search outcomes. By applying this evolving contextual framework to items displayed on the search engine results page (SERP), we progressively align search outcomes more closely with the buyer's interests and current search intentions. Our findings demonstrate that this incremental enhancement, from simple heuristic autoregressive features to advanced sequence models, significantly improves ranker performance. The integration of contextual techniques enhances the performance of our production ranker, leading to improved search results in both offline and online A/B testing in terms of Mean Reciprocal Rank (MRR). Overall, the paper details iterative methodologies and their substantial contributions to search result contextualization on e-commerce platforms.
Scrutinizing Shipment Records To Thwart Illegal Timber Trade
Jul 31, 2022
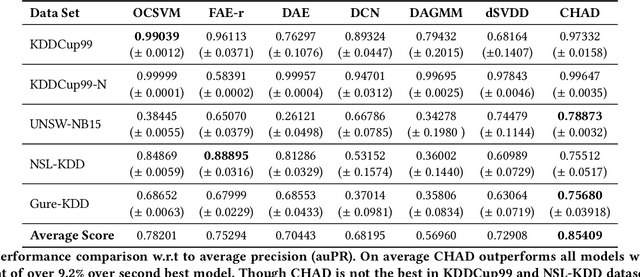
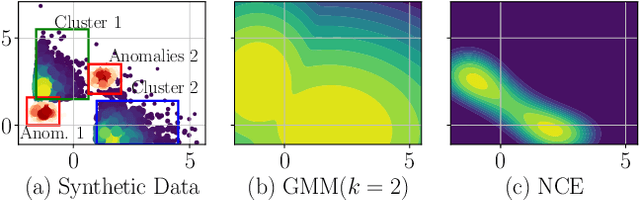
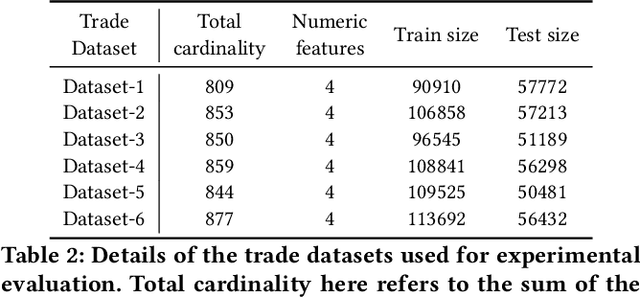
Timber and forest products made from wood, like furniture, are valuable commodities, and like the global trade of many highly-valued natural resources, face challenges of corruption, fraud, and illegal harvesting. These grey and black market activities in the wood and forest products sector are not limited to the countries where the wood was harvested, but extend throughout the global supply chain and have been tied to illicit financial flows, like trade-based money laundering, document fraud, species mislabeling, and other illegal activities. The task of finding such fraudulent activities using trade data, in the absence of ground truth, can be modelled as an unsupervised anomaly detection problem. However existing approaches suffer from certain shortcomings in their applicability towards large scale trade data. Trade data is heterogeneous, with both categorical and numerical attributes in a tabular format. The overall challenge lies in the complexity, volume and velocity of data, with large number of entities and lack of ground truth labels. To mitigate these, we propose a novel unsupervised anomaly detection -- Contrastive Learning based Heterogeneous Anomaly Detection (CHAD) that is generally applicable for large-scale heterogeneous tabular data. We demonstrate our model CHAD performs favorably against multiple comparable baselines for public benchmark datasets, and outperforms them in the case of trade data. More importantly we demonstrate our approach reduces assumptions and efforts required hyperparameter tuning, which is a key challenging aspect in an unsupervised training paradigm. Specifically, our overarching objective pertains to detecting suspicious timber shipments and patterns using Bill of Lading trade record data. Detecting anomalous transactions in shipment records can enable further investigation by government agencies and supply chain constituents.
Lessons from Deep Learning applied to Scholarly Information Extraction: What Works, What Doesn't, and Future Directions
Jul 08, 2022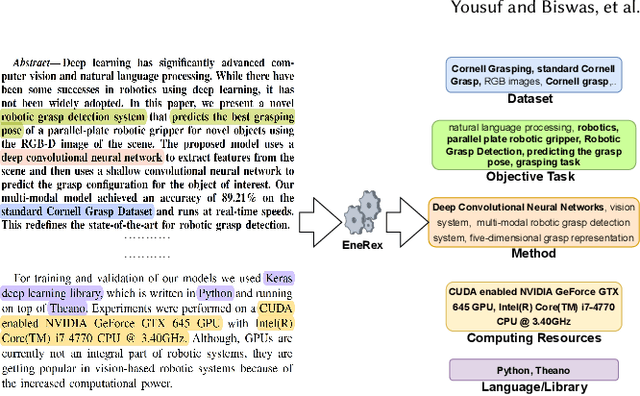

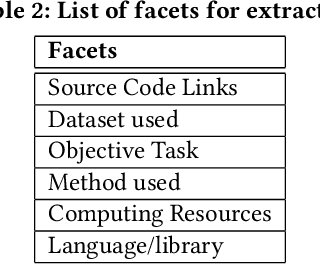
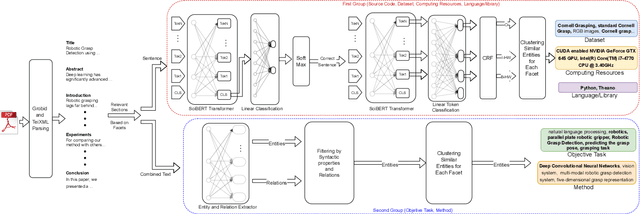
Understanding key insights from full-text scholarly articles is essential as it enables us to determine interesting trends, give insight into the research and development, and build knowledge graphs. However, some of the interesting key insights are only available when considering full-text. Although researchers have made significant progress in information extraction from short documents, extraction of scientific entities from full-text scholarly literature remains a challenging problem. This work presents an automated End-to-end Research Entity Extractor called EneRex to extract technical facets such as dataset usage, objective task, method from full-text scholarly research articles. Additionally, we extracted three novel facets, e.g., links to source code, computing resources, programming language/libraries from full-text articles. We demonstrate how EneRex is able to extract key insights and trends from a large-scale dataset in the domain of computer science. We further test our pipeline on multiple datasets and found that the EneRex improves upon a state of the art model. We highlight how the existing datasets are limited in their capacity and how EneRex may fit into an existing knowledge graph. We also present a detailed discussion with pointers for future research. Our code and data are publicly available at https://github.com/DiscoveryAnalyticsCenter/EneRex.
Detecting Anomalies Through Contrast in Heterogeneous Data
Apr 02, 2021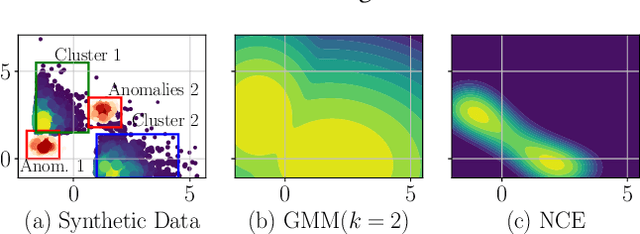
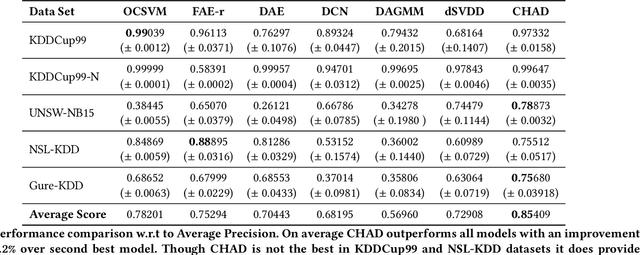
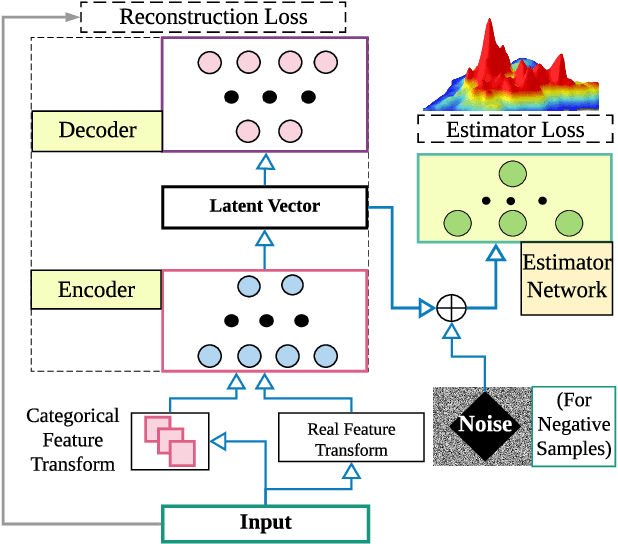
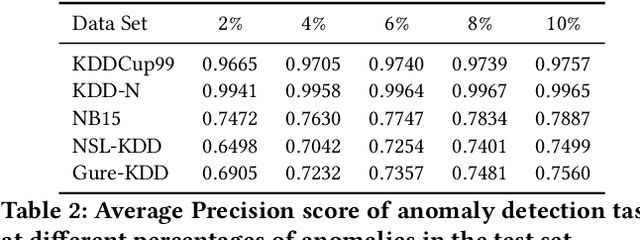
Detecting anomalies has been a fundamental approach in detecting potentially fraudulent activities. Tasked with detection of illegal timber trade that threatens ecosystems and economies and association with other illegal activities, we formulate our problem as one of anomaly detection. Among other challenges annotations are unavailable for our large-scale trade data with heterogeneous features (categorical and continuous), that can assist in building automated systems to detect fraudulent transactions. Modelling the task as unsupervised anomaly detection, we propose a novel model Contrastive Learning based Heterogeneous Anomaly Detector to address shortcomings of prior models. Our model uses an asymmetric autoencoder that can effectively handle large arity categorical variables, but avoids assumptions about structure of data in low-dimensional latent space and is robust to changes to hyper-parameters. The likelihood of data is approximated through an estimator network, which is jointly trained with the autoencoder,using negative sampling. Further the details and intuition for an effective negative sample generation approach for heterogeneous data are outlined. We provide a qualitative study to showcase the effectiveness of our model in detecting anomalies in timber trade.
Hierarchical Quickest Change Detection via Surrogates
Mar 31, 2016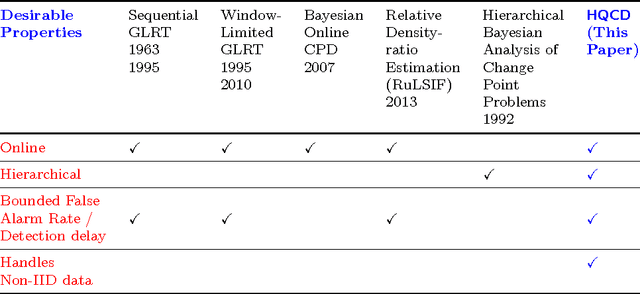
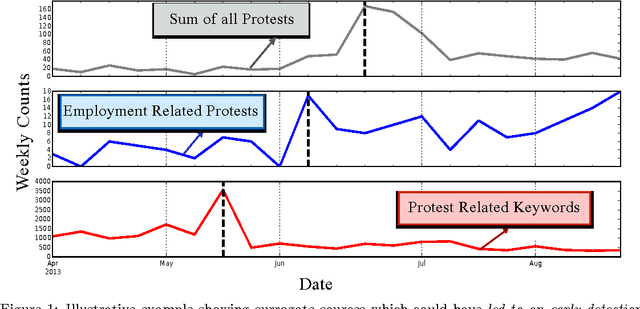
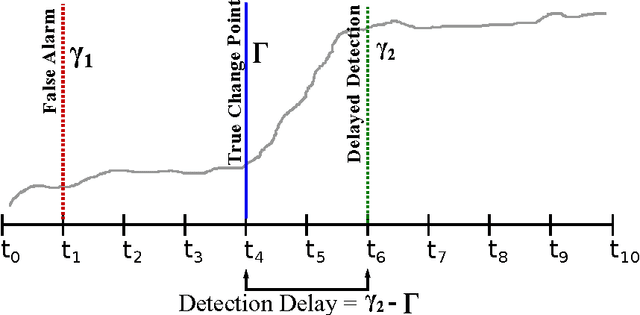
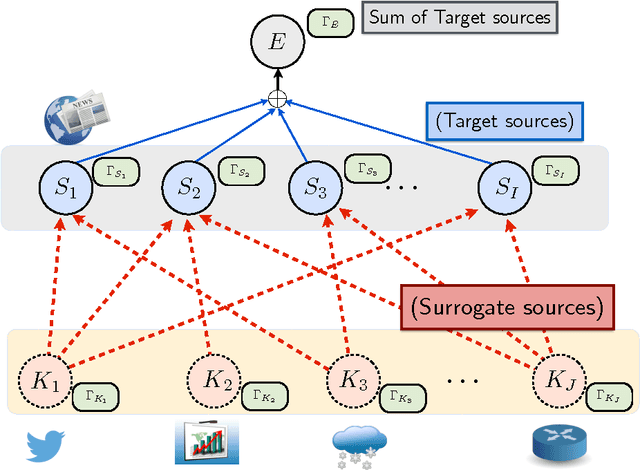
Change detection (CD) in time series data is a critical problem as it reveal changes in the underlying generative processes driving the time series. Despite having received significant attention, one important unexplored aspect is how to efficiently utilize additional correlated information to improve the detection and the understanding of changepoints. We propose hierarchical quickest change detection (HQCD), a framework that formalizes the process of incorporating additional correlated sources for early changepoint detection. The core ideas behind HQCD are rooted in the theory of quickest detection and HQCD can be regarded as its novel generalization to a hierarchical setting. The sources are classified into targets and surrogates, and HQCD leverages this structure to systematically assimilate observed data to update changepoint statistics across layers. The decision on actual changepoints are provided by minimizing the delay while still maintaining reliability bounds. In addition, HQCD also uncovers interesting relations between changes at targets from changes across surrogates. We validate HQCD for reliability and performance against several state-of-the-art methods for both synthetic dataset (known changepoints) and several real-life examples (unknown changepoints). Our experiments indicate that we gain significant robustness without loss of detection delay through HQCD. Our real-life experiments also showcase the usefulness of the hierarchical setting by connecting the surrogate sources (such as Twitter chatter) to target sources (such as Employment related protests that ultimately lead to major uprisings).