 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScrutinizing Shipment Records To Thwart Illegal Timber Trade
Jul 31, 2022
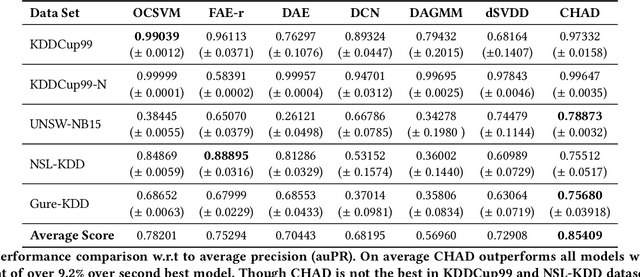
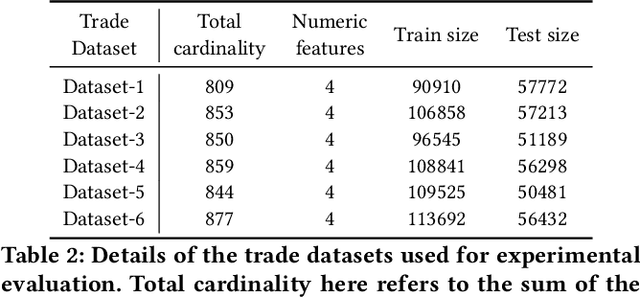
Timber and forest products made from wood, like furniture, are valuable commodities, and like the global trade of many highly-valued natural resources, face challenges of corruption, fraud, and illegal harvesting. These grey and black market activities in the wood and forest products sector are not limited to the countries where the wood was harvested, but extend throughout the global supply chain and have been tied to illicit financial flows, like trade-based money laundering, document fraud, species mislabeling, and other illegal activities. The task of finding such fraudulent activities using trade data, in the absence of ground truth, can be modelled as an unsupervised anomaly detection problem. However existing approaches suffer from certain shortcomings in their applicability towards large scale trade data. Trade data is heterogeneous, with both categorical and numerical attributes in a tabular format. The overall challenge lies in the complexity, volume and velocity of data, with large number of entities and lack of ground truth labels. To mitigate these, we propose a novel unsupervised anomaly detection -- Contrastive Learning based Heterogeneous Anomaly Detection (CHAD) that is generally applicable for large-scale heterogeneous tabular data. We demonstrate our model CHAD performs favorably against multiple comparable baselines for public benchmark datasets, and outperforms them in the case of trade data. More importantly we demonstrate our approach reduces assumptions and efforts required hyperparameter tuning, which is a key challenging aspect in an unsupervised training paradigm. Specifically, our overarching objective pertains to detecting suspicious timber shipments and patterns using Bill of Lading trade record data. Detecting anomalous transactions in shipment records can enable further investigation by government agencies and supply chain constituents.
Framing Algorithmic Recourse for Anomaly Detection
Jun 29, 2022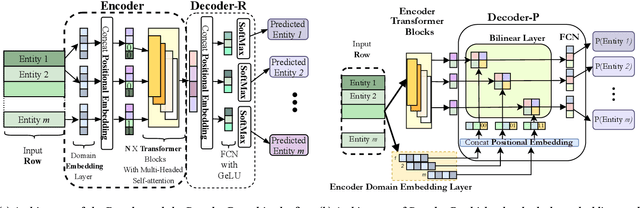
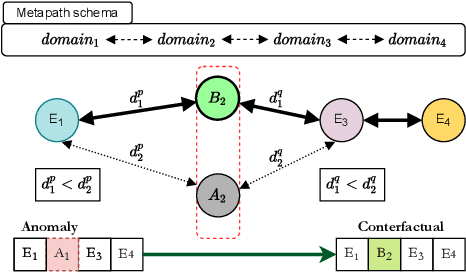
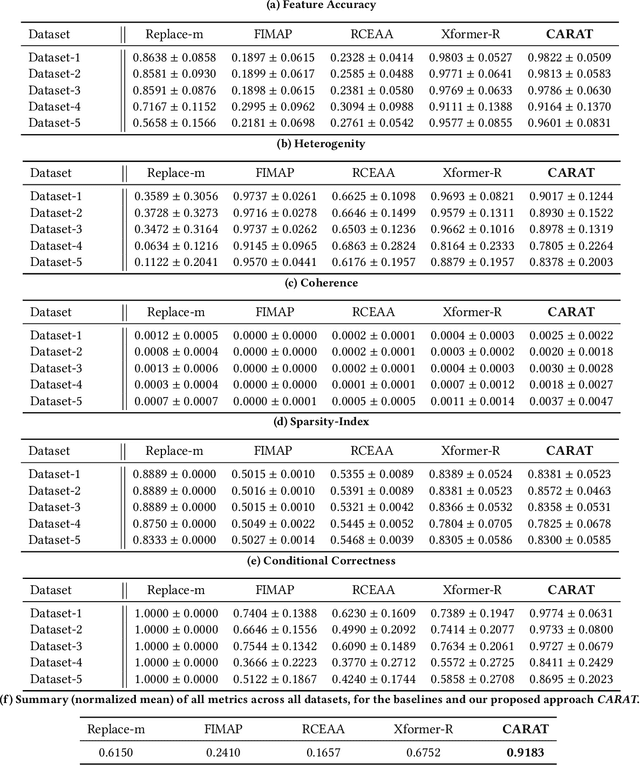
The problem of algorithmic recourse has been explored for supervised machine learning models, to provide more interpretable, transparent and robust outcomes from decision support systems. An unexplored area is that of algorithmic recourse for anomaly detection, specifically for tabular data with only discrete feature values. Here the problem is to present a set of counterfactuals that are deemed normal by the underlying anomaly detection model so that applications can utilize this information for explanation purposes or to recommend countermeasures. We present an approach -- Context preserving Algorithmic Recourse for Anomalies in Tabular data (CARAT), that is effective, scalable, and agnostic to the underlying anomaly detection model. CARAT uses a transformer based encoder-decoder model to explain an anomaly by finding features with low likelihood. Subsequently semantically coherent counterfactuals are generated by modifying the highlighted features, using the overall context of features in the anomalous instance(s). Extensive experiments help demonstrate the efficacy of CARAT.
Detecting Anomalies Through Contrast in Heterogeneous Data
Apr 02, 2021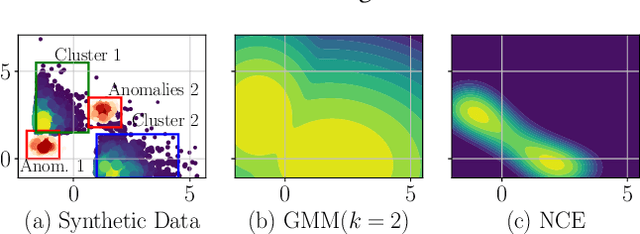
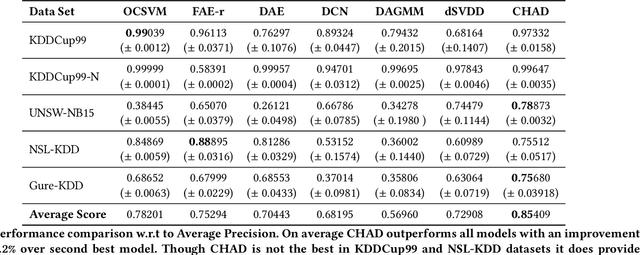
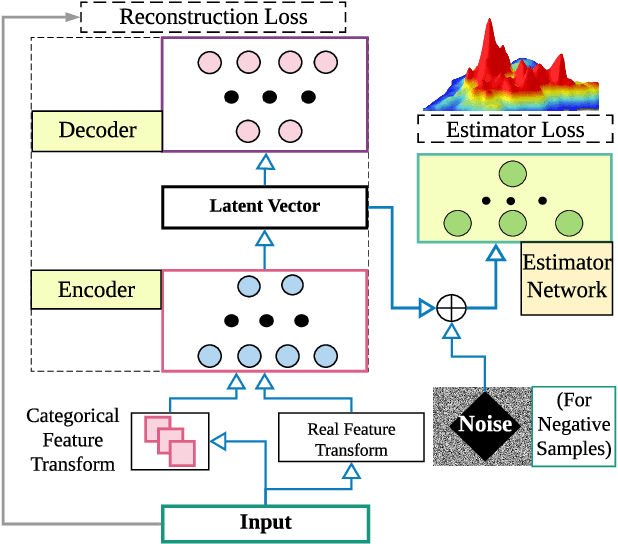
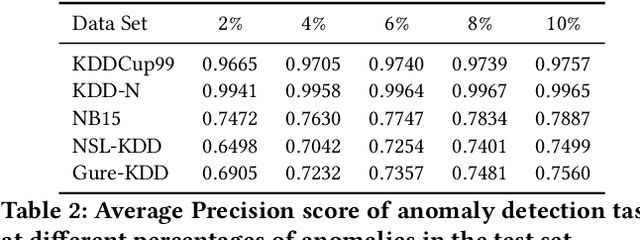
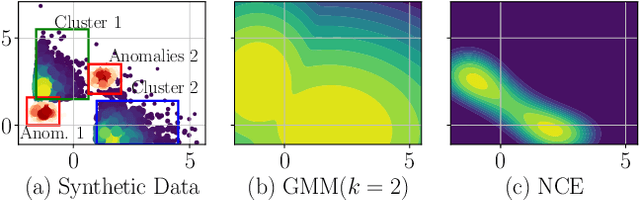
Detecting anomalies has been a fundamental approach in detecting potentially fraudulent activities. Tasked with detection of illegal timber trade that threatens ecosystems and economies and association with other illegal activities, we formulate our problem as one of anomaly detection. Among other challenges annotations are unavailable for our large-scale trade data with heterogeneous features (categorical and continuous), that can assist in building automated systems to detect fraudulent transactions. Modelling the task as unsupervised anomaly detection, we propose a novel model Contrastive Learning based Heterogeneous Anomaly Detector to address shortcomings of prior models. Our model uses an asymmetric autoencoder that can effectively handle large arity categorical variables, but avoids assumptions about structure of data in low-dimensional latent space and is robust to changes to hyper-parameters. The likelihood of data is approximated through an estimator network, which is jointly trained with the autoencoder,using negative sampling. Further the details and intuition for an effective negative sample generation approach for heterogeneous data are outlined. We provide a qualitative study to showcase the effectiveness of our model in detecting anomalies in timber trade.
Small Survey Event Detection
Nov 09, 2020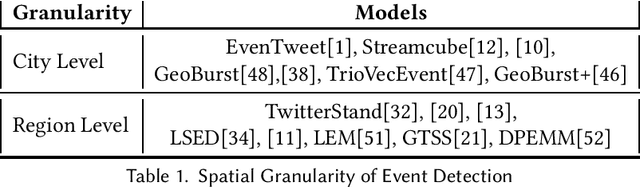
A small survey on event detection using Twitter. This work first defines the problem statement, and then summarizes and collates the different research works towards solving the problem.