 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI on AI: Exploring the Utility of GPT as an Expert Annotator of AI Publications
Mar 14, 2024Identifying scientific publications that are within a dynamic field of research often requires costly annotation by subject-matter experts. Resources like widely-accepted classification criteria or field taxonomies are unavailable for a domain like artificial intelligence (AI), which spans emerging topics and technologies. We address these challenges by inferring a functional definition of AI research from existing expert labels, and then evaluating state-of-the-art chatbot models on the task of expert data annotation. Using the arXiv publication database as ground-truth, we experiment with prompt engineering for GPT chatbot models to identify an alternative, automated expert annotation pipeline that assigns AI labels with 94% accuracy. For comparison, we fine-tune SPECTER, a transformer language model pre-trained on scientific publications, that achieves 96% accuracy (only 2% higher than GPT) on classifying AI publications. Our results indicate that with effective prompt engineering, chatbots can be used as reliable data annotators even where subject-area expertise is required. To evaluate the utility of chatbot-annotated datasets on downstream classification tasks, we train a new classifier on GPT-labeled data and compare its performance to the arXiv-trained model. The classifier trained on GPT-labeled data outperforms the arXiv-trained model by nine percentage points, achieving 82% accuracy.
Lessons from Deep Learning applied to Scholarly Information Extraction: What Works, What Doesn't, and Future Directions
Jul 08, 2022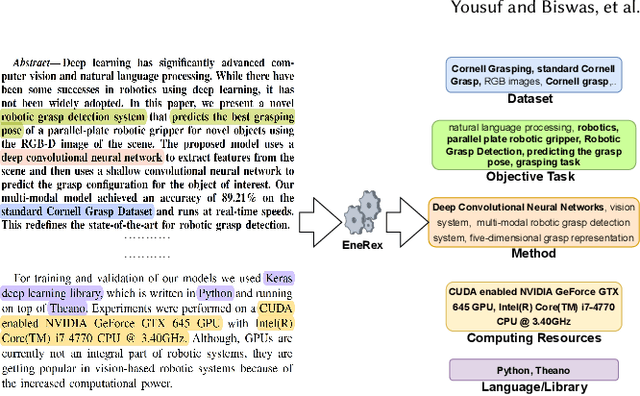

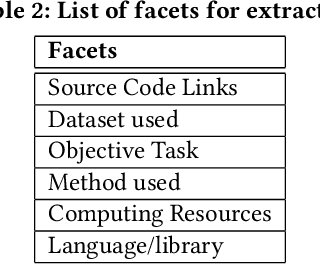
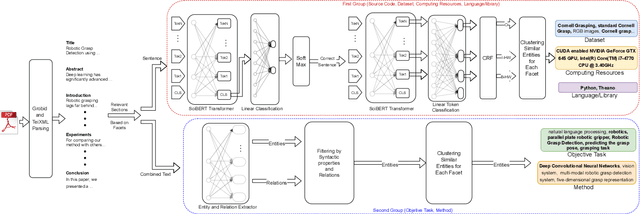
Understanding key insights from full-text scholarly articles is essential as it enables us to determine interesting trends, give insight into the research and development, and build knowledge graphs. However, some of the interesting key insights are only available when considering full-text. Although researchers have made significant progress in information extraction from short documents, extraction of scientific entities from full-text scholarly literature remains a challenging problem. This work presents an automated End-to-end Research Entity Extractor called EneRex to extract technical facets such as dataset usage, objective task, method from full-text scholarly research articles. Additionally, we extracted three novel facets, e.g., links to source code, computing resources, programming language/libraries from full-text articles. We demonstrate how EneRex is able to extract key insights and trends from a large-scale dataset in the domain of computer science. We further test our pipeline on multiple datasets and found that the EneRex improves upon a state of the art model. We highlight how the existing datasets are limited in their capacity and how EneRex may fit into an existing knowledge graph. We also present a detailed discussion with pointers for future research. Our code and data are publicly available at https://github.com/DiscoveryAnalyticsCenter/EneRex.