 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring LLMs for Scientific Information Extraction Using The SciEx Framework
Dec 10, 2025Large language models (LLMs) are increasingly touted as powerful tools for automating scientific information extraction. However, existing methods and tools often struggle with the realities of scientific literature: long-context documents, multi-modal content, and reconciling varied and inconsistent fine-grained information across multiple publications into standardized formats. These challenges are further compounded when the desired data schema or extraction ontology changes rapidly, making it difficult to re-architect or fine-tune existing systems. We present SciEx, a modular and composable framework that decouples key components including PDF parsing, multi-modal retrieval, extraction, and aggregation. This design streamlines on-demand data extraction while enabling extensibility and flexible integration of new models, prompting strategies, and reasoning mechanisms. We evaluate SciEx on datasets spanning three scientific topics for its ability to extract fine-grained information accurately and consistently. Our findings provide practical insights into both the strengths and limitations of current LLM-based pipelines.
Lessons from Deep Learning applied to Scholarly Information Extraction: What Works, What Doesn't, and Future Directions
Jul 08, 2022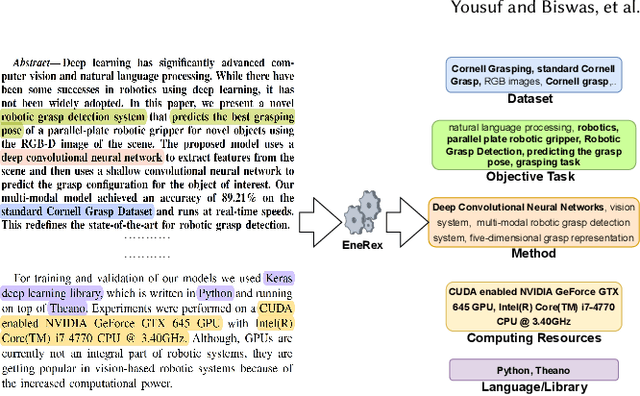

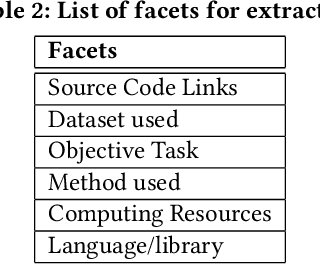
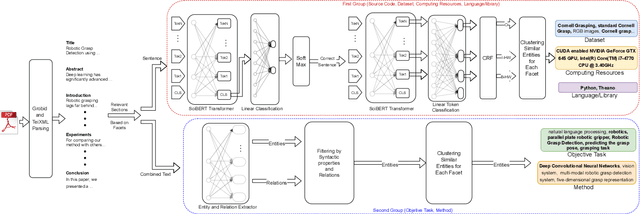
Understanding key insights from full-text scholarly articles is essential as it enables us to determine interesting trends, give insight into the research and development, and build knowledge graphs. However, some of the interesting key insights are only available when considering full-text. Although researchers have made significant progress in information extraction from short documents, extraction of scientific entities from full-text scholarly literature remains a challenging problem. This work presents an automated End-to-end Research Entity Extractor called EneRex to extract technical facets such as dataset usage, objective task, method from full-text scholarly research articles. Additionally, we extracted three novel facets, e.g., links to source code, computing resources, programming language/libraries from full-text articles. We demonstrate how EneRex is able to extract key insights and trends from a large-scale dataset in the domain of computer science. We further test our pipeline on multiple datasets and found that the EneRex improves upon a state of the art model. We highlight how the existing datasets are limited in their capacity and how EneRex may fit into an existing knowledge graph. We also present a detailed discussion with pointers for future research. Our code and data are publicly available at https://github.com/DiscoveryAnalyticsCenter/EneRex.
Patent Citation Dynamics Modeling via Multi-Attention Recurrent Networks
May 22, 2019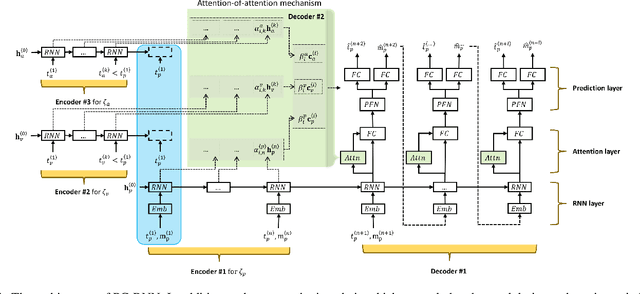
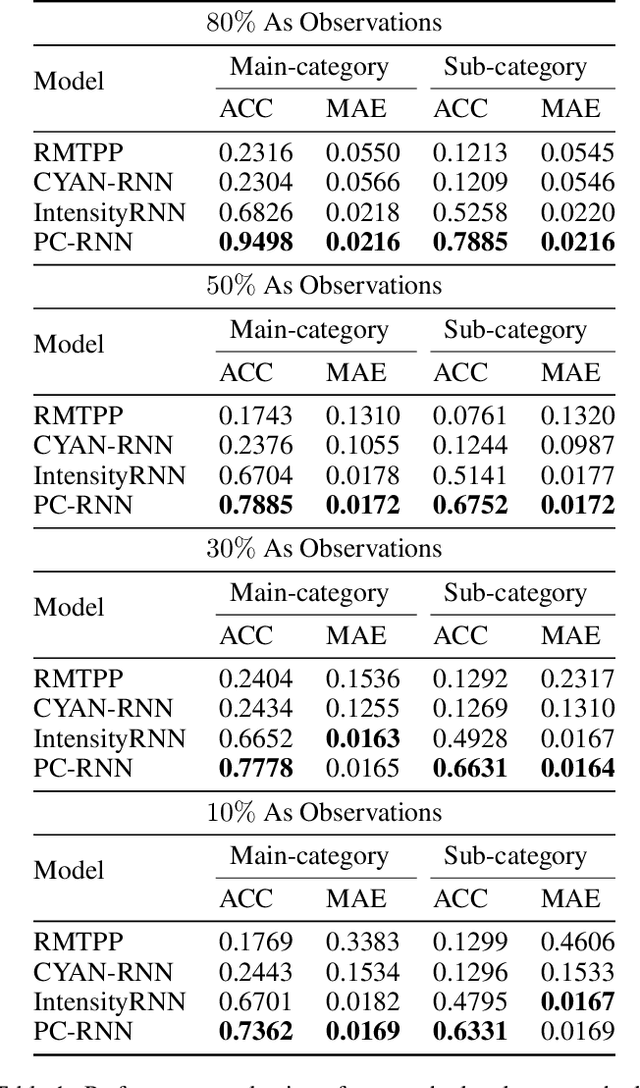
Modeling and forecasting forward citations to a patent is a central task for the discovery of emerging technologies and for measuring the pulse of inventive progress. Conventional methods for forecasting these forward citations cast the problem as analysis of temporal point processes which rely on the conditional intensity of previously received citations. Recent approaches model the conditional intensity as a chain of recurrent neural networks to capture memory dependency in hopes of reducing the restrictions of the parametric form of the intensity function. For the problem of patent citations, we observe that forecasting a patent's chain of citations benefits from not only the patent's history itself but also from the historical citations of assignees and inventors associated with that patent. In this paper, we propose a sequence-to-sequence model which employs an attention-of-attention mechanism to capture the dependencies of these multiple time sequences. Furthermore, the proposed model is able to forecast both the timestamp and the category of a patent's next citation. Extensive experiments on a large patent citation dataset collected from USPTO demonstrate that the proposed model outperforms state-of-the-art models at forward citation forecasting.