 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCoOP: Semantic Consistent Opinion Pooling for Uncertainty Quantification in Multiple Vision-Language Model Systems
Mar 25, 2026Combining multiple Vision-Language Models (VLMs) can enhance multimodal reasoning and robustness, but aggregating heterogeneous models' outputs amplifies uncertainty and increases the risk of hallucinations. We propose SCoOP (Semantic-Consistent Opinion Pooling), a training-free uncertainty quantification (UQ) framework multi-VLM systems through uncertainty-weighted linear opinion pooling. Unlike prior UQ methods designed for single models, SCoOP explicitly measures collective, system-level uncertainty across multiple VLMs, enabling effective hallucination detection and abstention for highly uncertain samples. On ScienceQA, SCoOP achieves an AUROC of 0.866 for hallucination detection, outperforming baselines (0.732-0.757) by approximately 10-13%. For abstention, it attains an AURAC of 0.907, exceeding baselines (0.818-0.840) by 7-9%. Despite these gains, SCoOP introduces only microsecond-level aggregation overhead relative to the baselines, which is trivial compared to typical VLM inference time (on the order of seconds). These results demonstrate that SCoOP provides an efficient and principled mechanism for uncertainty-aware aggregation, advancing the reliability of multimodal AI systems.
Advancing Model Refinement: Muon-Optimized Distillation and Quantization for LLM Deployment
Jan 14, 2026Large Language Models (LLMs) enable advanced natural language processing but face deployment challenges on resource-constrained edge devices due to high computational, memory, and energy demands. Optimizing these models requires addressing three key challenges: acquiring task-specific data, fine-tuning for performance, and compressing models to accelerate inference while reducing resource demands. We propose an integrated framework combining GPTQ-based quantization, low-rank adaptation (LoRA), and a specialized data distillation process to significantly reduce model size and complexity while preserving or enhancing task-specific performance. By leveraging data distillation, knowledge distillation via Kullback-Leibler divergence, Bayesian hyperparameter optimization, and the Muon optimizer, our pipeline achieves up to 2x memory compression (e.g., reducing a 6GB model to 3GB) and enables efficient inference for specialized tasks. Empirical results demonstrate superior performance on standard LLM benchmarks compared to GPTQ quantization alone, with the Muon optimizer notably enhancing fine-tuned models' resistance to accuracy decay during quantization.
ORCA: Agentic Reasoning For Hallucination and Adversarial Robustness in Vision-Language Models
Sep 18, 2025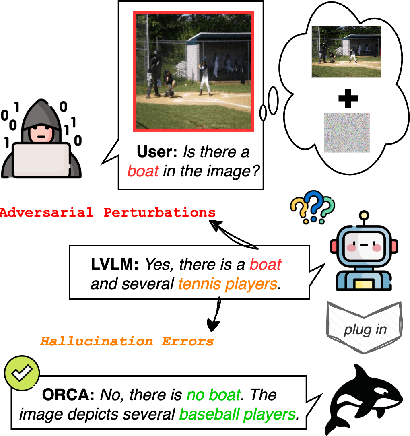



Large Vision-Language Models (LVLMs) exhibit strong multimodal capabilities but remain vulnerable to hallucinations from intrinsic errors and adversarial attacks from external exploitations, limiting their reliability in real-world applications. We present ORCA, an agentic reasoning framework that improves the factual accuracy and adversarial robustness of pretrained LVLMs through test-time structured inference reasoning with a suite of small vision models (less than 3B parameters). ORCA operates via an Observe--Reason--Critique--Act loop, querying multiple visual tools with evidential questions, validating cross-model inconsistencies, and refining predictions iteratively without access to model internals or retraining. ORCA also stores intermediate reasoning traces, which supports auditable decision-making. Though designed primarily to mitigate object-level hallucinations, ORCA also exhibits emergent adversarial robustness without requiring adversarial training or defense mechanisms. We evaluate ORCA across three settings: (1) clean images on hallucination benchmarks, (2) adversarially perturbed images without defense, and (3) adversarially perturbed images with defense applied. On the POPE hallucination benchmark, ORCA improves standalone LVLM performance by +3.64\% to +40.67\% across different subsets. Under adversarial perturbations on POPE, ORCA achieves an average accuracy gain of +20.11\% across LVLMs. When combined with defense techniques on adversarially perturbed AMBER images, ORCA further improves standalone LVLM performance, with gains ranging from +1.20\% to +48.00\% across evaluation metrics. These results demonstrate that ORCA offers a promising path toward building more reliable and robust multimodal systems.
Neurosymbolic Artificial Intelligence for Robust Network Intrusion Detection: From Scratch to Transfer Learning
Jun 04, 2025Network Intrusion Detection Systems (NIDS) play a vital role in protecting digital infrastructures against increasingly sophisticated cyber threats. In this paper, we extend ODXU, a Neurosymbolic AI (NSAI) framework that integrates deep embedded clustering for feature extraction, symbolic reasoning using XGBoost, and comprehensive uncertainty quantification (UQ) to enhance robustness, interpretability, and generalization in NIDS. The extended ODXU incorporates score-based methods (e.g., Confidence Scoring, Shannon Entropy) and metamodel-based techniques, including SHAP values and Information Gain, to assess the reliability of predictions. Experimental results on the CIC-IDS-2017 dataset show that ODXU outperforms traditional neural models across six evaluation metrics, including classification accuracy and false omission rate. While transfer learning has seen widespread adoption in fields such as computer vision and natural language processing, its potential in cybersecurity has not been thoroughly explored. To bridge this gap, we develop a transfer learning strategy that enables the reuse of a pre-trained ODXU model on a different dataset. Our ablation study on ACI-IoT-2023 demonstrates that the optimal transfer configuration involves reusing the pre-trained autoencoder, retraining the clustering module, and fine-tuning the XGBoost classifier, and outperforms traditional neural models when trained with as few as 16,000 samples (approximately 50% of the training data). Additionally, results show that metamodel-based UQ methods consistently outperform score-based approaches on both datasets.
Hydra: An Agentic Reasoning Approach for Enhancing Adversarial Robustness and Mitigating Hallucinations in Vision-Language Models
Apr 19, 2025



To develop trustworthy Vision-Language Models (VLMs), it is essential to address adversarial robustness and hallucination mitigation, both of which impact factual accuracy in high-stakes applications such as defense and healthcare. Existing methods primarily focus on either adversarial defense or hallucination post-hoc correction, leaving a gap in unified robustness strategies. We introduce \textbf{Hydra}, an adaptive agentic framework that enhances plug-in VLMs through iterative reasoning, structured critiques, and cross-model verification, improving both resilience to adversarial perturbations and intrinsic model errors. Hydra employs an Action-Critique Loop, where it retrieves and critiques visual information, leveraging Chain-of-Thought (CoT) and In-Context Learning (ICL) techniques to refine outputs dynamically. Unlike static post-hoc correction methods, Hydra adapts to both adversarial manipulations and intrinsic model errors, making it robust to malicious perturbations and hallucination-related inaccuracies. We evaluate Hydra on four VLMs, three hallucination benchmarks, two adversarial attack strategies, and two adversarial defense methods, assessing performance on both clean and adversarial inputs. Results show that Hydra surpasses plug-in VLMs and state-of-the-art (SOTA) dehallucination methods, even without explicit adversarial defenses, demonstrating enhanced robustness and factual consistency. By bridging adversarial resistance and hallucination mitigation, Hydra provides a scalable, training-free solution for improving the reliability of VLMs in real-world applications.
On Accelerating Edge AI: Optimizing Resource-Constrained Environments
Jan 25, 2025Resource-constrained edge deployments demand AI solutions that balance high performance with stringent compute, memory, and energy limitations. In this survey, we present a comprehensive overview of the primary strategies for accelerating deep learning models under such constraints. First, we examine model compression techniques-pruning, quantization, tensor decomposition, and knowledge distillation-that streamline large models into smaller, faster, and more efficient variants. Next, we explore Neural Architecture Search (NAS), a class of automated methods that discover architectures inherently optimized for particular tasks and hardware budgets. We then discuss compiler and deployment frameworks, such as TVM, TensorRT, and OpenVINO, which provide hardware-tailored optimizations at inference time. By integrating these three pillars into unified pipelines, practitioners can achieve multi-objective goals, including latency reduction, memory savings, and energy efficiency-all while maintaining competitive accuracy. We also highlight emerging frontiers in hierarchical NAS, neurosymbolic approaches, and advanced distillation tailored to large language models, underscoring open challenges like pre-training pruning for massive networks. Our survey offers practical insights, identifies current research gaps, and outlines promising directions for building scalable, platform-independent frameworks to accelerate deep learning models at the edge.
A Synergistic Approach In Network Intrusion Detection By Neurosymbolic AI
Jun 03, 2024The prevailing approaches in Network Intrusion Detection Systems (NIDS) are often hampered by issues such as high resource consumption, significant computational demands, and poor interpretability. Furthermore, these systems generally struggle to identify novel, rapidly changing cyber threats. This paper delves into the potential of incorporating Neurosymbolic Artificial Intelligence (NSAI) into NIDS, combining deep learning's data-driven strengths with symbolic AI's logical reasoning to tackle the dynamic challenges in cybersecurity, which also includes detailed NSAI techniques introduction for cyber professionals to explore the potential strengths of NSAI in NIDS. The inclusion of NSAI in NIDS marks potential advancements in both the detection and interpretation of intricate network threats, benefiting from the robust pattern recognition of neural networks and the interpretive prowess of symbolic reasoning. By analyzing network traffic data types and machine learning architectures, we illustrate NSAI's distinctive capability to offer more profound insights into network behavior, thereby improving both detection performance and the adaptability of the system. This merging of technologies not only enhances the functionality of traditional NIDS but also sets the stage for future developments in building more resilient, interpretable, and dynamic defense mechanisms against advanced cyber threats. The continued progress in this area is poised to transform NIDS into a system that is both responsive to known threats and anticipatory of emerging, unseen ones.
Enhancing object detection robustness: A synthetic and natural perturbation approach
Apr 20, 2023



Robustness against real-world distribution shifts is crucial for the successful deployment of object detection models in practical applications. In this paper, we address the problem of assessing and enhancing the robustness of object detection models against natural perturbations, such as varying lighting conditions, blur, and brightness. We analyze four state-of-the-art deep neural network models, Detr-ResNet-101, Detr-ResNet-50, YOLOv4, and YOLOv4-tiny, using the COCO 2017 dataset and ExDark dataset. By simulating synthetic perturbations with the AugLy package, we systematically explore the optimal level of synthetic perturbation required to improve the models robustness through data augmentation techniques. Our comprehensive ablation study meticulously evaluates the impact of synthetic perturbations on object detection models performance against real-world distribution shifts, establishing a tangible connection between synthetic augmentation and real-world robustness. Our findings not only substantiate the effectiveness of synthetic perturbations in improving model robustness, but also provide valuable insights for researchers and practitioners in developing more robust and reliable object detection models tailored for real-world applications.
Impact of Parameter Sparsity on Stochastic Gradient MCMC Methods for Bayesian Deep Learning
Feb 08, 2022Bayesian methods hold significant promise for improving the uncertainty quantification ability and robustness of deep neural network models. Recent research has seen the investigation of a number of approximate Bayesian inference methods for deep neural networks, building on both the variational Bayesian and Markov chain Monte Carlo (MCMC) frameworks. A fundamental issue with MCMC methods is that the improvements they enable are obtained at the expense of increased computation time and model storage costs. In this paper, we investigate the potential of sparse network structures to flexibly trade-off model storage costs and inference run time against predictive performance and uncertainty quantification ability. We use stochastic gradient MCMC methods as the core Bayesian inference method and consider a variety of approaches for selecting sparse network structures. Surprisingly, our results show that certain classes of randomly selected substructures can perform as well as substructures derived from state-of-the-art iterative pruning methods while drastically reducing model training times.
EDITS: Modeling and Mitigating Data Bias for Graph Neural Networks
Aug 11, 2021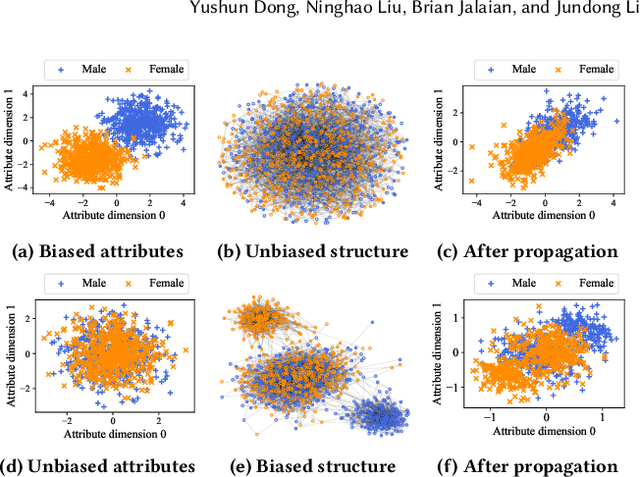
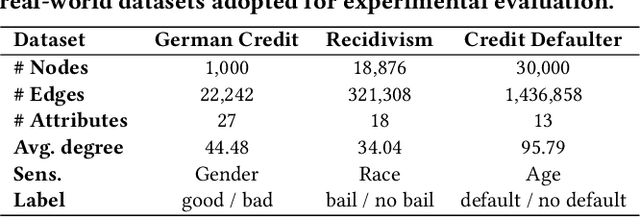
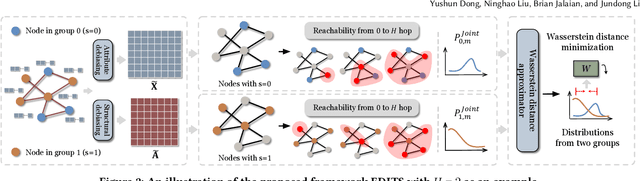

Graph Neural Networks (GNNs) have recently demonstrated superior capability of tackling graph analytical problems in various applications. Nevertheless, with the wide-spreading practice of GNNs in high-stake decision-making processes, there is an increasing societal concern that GNNs could make discriminatory decisions that may be illegal towards certain demographic groups. Although some explorations have been made towards developing fair GNNs, existing approaches are tailored for a specific GNN model. However, in practical scenarios, myriads of GNN variants have been proposed for different tasks, and it is costly to train and fine-tune existing debiasing models for different GNNs. Also, bias in a trained model could originate from training data, while how to mitigate bias in the graph data is usually overlooked. In this work, different from existing work, we first propose novel definitions and metrics to measure the bias in an attributed network, which leads to the optimization objective to mitigate bias. Based on the optimization objective, we develop a framework named EDITS to mitigate the bias in attributed networks while preserving useful information. EDITS works in a model-agnostic manner, which means that it is independent of the specific GNNs applied for downstream tasks. Extensive experiments on both synthetic and real-world datasets demonstrate the validity of the proposed bias metrics and the superiority of EDITS on both bias mitigation and utility maintenance. Open-source implementation: https://github.com/yushundong/EDITS.