 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE and Diverse Generalization via Selective Disagreement
Sep 09, 2025Deep neural networks are notoriously sensitive to spurious correlations - where a model learns a shortcut that fails out-of-distribution. Existing work on spurious correlations has often focused on incomplete correlations,leveraging access to labeled instances that break the correlation. But in cases where the spurious correlations are complete, the correct generalization is fundamentally \textit{underspecified}. To resolve this underspecification, we propose learning a set of concepts that are consistent with training data but make distinct predictions on a subset of novel unlabeled inputs. Using a self-training approach that encourages \textit{confident} and \textit{selective} disagreement, our method ACE matches or outperforms existing methods on a suite of complete-spurious correlation benchmarks, while remaining robust to incomplete spurious correlations. ACE is also more configurable than prior approaches, allowing for straight-forward encoding of prior knowledge and principled unsupervised model selection. In an early application to language-model alignment, we find that ACE achieves competitive performance on the measurement tampering detection benchmark \textit{without} access to untrusted measurements. While still subject to important limitations, ACE represents significant progress towards overcoming underspecification.
Combining LLM decision and RL action selection to improve RL policy for adaptive interventions
Jan 13, 2025Reinforcement learning (RL) is increasingly being used in the healthcare domain, particularly for the development of personalized health adaptive interventions. Inspired by the success of Large Language Models (LLMs), we are interested in using LLMs to update the RL policy in real time, with the goal of accelerating personalization. We use the text-based user preference to influence the action selection on the fly, in order to immediately incorporate the user preference. We use the term "user preference" as a broad term to refer to a user personal preference, constraint, health status, or a statement expressing like or dislike, etc. Our novel approach is a hybrid method that combines the LLM response and the RL action selection to improve the RL policy. Given an LLM prompt that incorporates the user preference, the LLM acts as a filter in the typical RL action selection. We investigate different prompting strategies and action selection strategies. To evaluate our approach, we implement a simulation environment that generates the text-based user preferences and models the constraints that impact behavioral dynamics. We show that our approach is able to take into account the text-based user preferences, while improving the RL policy, thus improving personalization in adaptive intervention.
BOTS: Batch Bayesian Optimization of Extended Thompson Sampling for Severely Episode-Limited RL Settings
Nov 30, 2024



In settings where the application of reinforcement learning (RL) requires running real-world trials, including the optimization of adaptive health interventions, the number of episodes available for learning can be severely limited due to cost or time constraints. In this setting, the bias-variance trade-off of contextual bandit methods can be significantly better than that of more complex full RL methods. However, Thompson sampling bandits are limited to selecting actions based on distributions of immediate rewards. In this paper, we extend the linear Thompson sampling bandit to select actions based on a state-action utility function consisting of the Thompson sampler's estimate of the expected immediate reward combined with an action bias term. We use batch Bayesian optimization over episodes to learn the action bias terms with the goal of maximizing the expected return of the extended Thompson sampler. The proposed approach is able to learn optimal policies for a strictly broader class of Markov decision processes (MDPs) than standard Thompson sampling. Using an adaptive intervention simulation environment that captures key aspects of behavioral dynamics, we show that the proposed method can significantly out-perform standard Thompson sampling in terms of total return, while requiring significantly fewer episodes than standard value function and policy gradient methods.
StepCountJITAI: simulation environment for RL with application to physical activity adaptive intervention
Nov 01, 2024The use of reinforcement learning (RL) to learn policies for just-in-time adaptive interventions (JITAIs) is of significant interest in many behavioral intervention domains including improving levels of physical activity. In a messaging-based physical activity JITAI, a mobile health app is typically used to send messages to a participant to encourage engagement in physical activity. In this setting, RL methods can be used to learn what intervention options to provide to a participant in different contexts. However, deploying RL methods in real physical activity adaptive interventions comes with challenges: the cost and time constraints of real intervention studies result in limited data to learn adaptive intervention policies. Further, commonly used RL simulation environments have dynamics that are of limited relevance to physical activity adaptive interventions and thus shed little light on what RL methods may be optimal for this challenging application domain. In this paper, we introduce StepCountJITAI, an RL environment designed to foster research on RL methods that address the significant challenges of policy learning for adaptive behavioral interventions.
Temporally Multi-Scale Sparse Self-Attention for Physical Activity Data Imputation
Jun 27, 2024Wearable sensors enable health researchers to continuously collect data pertaining to the physiological state of individuals in real-world settings. However, such data can be subject to extensive missingness due to a complex combination of factors. In this work, we study the problem of imputation of missing step count data, one of the most ubiquitous forms of wearable sensor data. We construct a novel and large scale data set consisting of a training set with over 3 million hourly step count observations and a test set with over 2.5 million hourly step count observations. We propose a domain knowledge-informed sparse self-attention model for this task that captures the temporal multi-scale nature of step-count data. We assess the performance of the model relative to baselines and conduct ablation studies to verify our specific model designs.
Retrieval-Based Reconstruction For Time-series Contrastive Learning
Nov 01, 2023The success of self-supervised contrastive learning hinges on identifying positive data pairs that, when pushed together in embedding space, encode useful information for subsequent downstream tasks. However, in time-series, this is challenging because creating positive pairs via augmentations may break the original semantic meaning. We hypothesize that if we can retrieve information from one subsequence to successfully reconstruct another subsequence, then they should form a positive pair. Harnessing this intuition, we introduce our novel approach: REtrieval-BAsed Reconstruction (REBAR) contrastive learning. First, we utilize a convolutional cross-attention architecture to calculate the REBAR error between two different time-series. Then, through validation experiments, we show that the REBAR error is a predictor of mutual class membership, justifying its usage as a positive/negative labeler. Finally, once integrated into a contrastive learning framework, our REBAR method can learn an embedding that achieves state-of-the-art performance on downstream tasks across various modalities.
Heteroskedastic Geospatial Tracking with Distributed Camera Networks
Jun 04, 2023Visual object tracking has seen significant progress in recent years. However, the vast majority of this work focuses on tracking objects within the image plane of a single camera and ignores the uncertainty associated with predicted object locations. In this work, we focus on the geospatial object tracking problem using data from a distributed camera network. The goal is to predict an object's track in geospatial coordinates along with uncertainty over the object's location while respecting communication constraints that prohibit centralizing raw image data. We present a novel single-object geospatial tracking data set that includes high-accuracy ground truth object locations and video data from a network of four cameras. We present a modeling framework for addressing this task including a novel backbone model and explore how uncertainty calibration and fine-tuning through a differentiable tracker affect performance.
Assessing the Impact of Context Inference Error and Partial Observability on RL Methods for Just-In-Time Adaptive Interventions
May 17, 2023Just-in-Time Adaptive Interventions (JITAIs) are a class of personalized health interventions developed within the behavioral science community. JITAIs aim to provide the right type and amount of support by iteratively selecting a sequence of intervention options from a pre-defined set of components in response to each individual's time varying state. In this work, we explore the application of reinforcement learning methods to the problem of learning intervention option selection policies. We study the effect of context inference error and partial observability on the ability to learn effective policies. Our results show that the propagation of uncertainty from context inferences is critical to improving intervention efficacy as context uncertainty increases, while policy gradient algorithms can provide remarkable robustness to partially observed behavioral state information.
BayesLDM: A Domain-Specific Language for Probabilistic Modeling of Longitudinal Data
Sep 12, 2022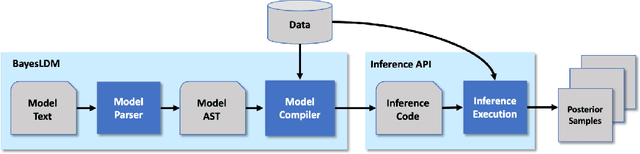
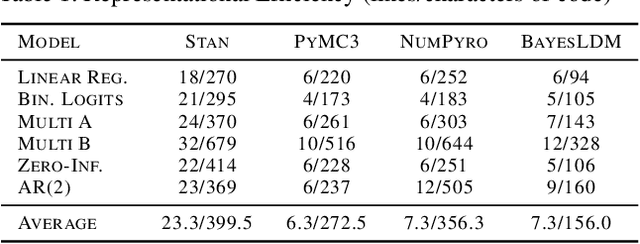
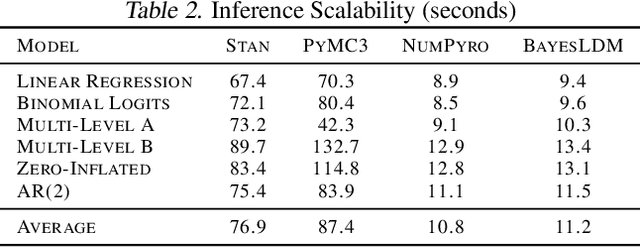
In this paper we present BayesLDM, a system for Bayesian longitudinal data modeling consisting of a high-level modeling language with specific features for modeling complex multivariate time series data coupled with a compiler that can produce optimized probabilistic program code for performing inference in the specified model. BayesLDM supports modeling of Bayesian network models with a specific focus on the efficient, declarative specification of dynamic Bayesian Networks (DBNs). The BayesLDM compiler combines a model specification with inspection of available data and outputs code for performing Bayesian inference for unknown model parameters while simultaneously handling missing data. These capabilities have the potential to significantly accelerate iterative modeling workflows in domains that involve the analysis of complex longitudinal data by abstracting away the process of producing computationally efficient probabilistic inference code. We describe the BayesLDM system components, evaluate the efficiency of representation and inference optimizations and provide an illustrative example of the application of the system to analyzing heterogeneous and partially observed mobile health data.
Impact of Parameter Sparsity on Stochastic Gradient MCMC Methods for Bayesian Deep Learning
Feb 08, 2022Bayesian methods hold significant promise for improving the uncertainty quantification ability and robustness of deep neural network models. Recent research has seen the investigation of a number of approximate Bayesian inference methods for deep neural networks, building on both the variational Bayesian and Markov chain Monte Carlo (MCMC) frameworks. A fundamental issue with MCMC methods is that the improvements they enable are obtained at the expense of increased computation time and model storage costs. In this paper, we investigate the potential of sparse network structures to flexibly trade-off model storage costs and inference run time against predictive performance and uncertainty quantification ability. We use stochastic gradient MCMC methods as the core Bayesian inference method and consider a variety of approaches for selecting sparse network structures. Surprisingly, our results show that certain classes of randomly selected substructures can perform as well as substructures derived from state-of-the-art iterative pruning methods while drastically reducing model training times.