 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn-PPO: Turn-Level Advantage Estimation with PPO for Improved Multi-Turn RL in Agentic LLMs
Dec 18, 2025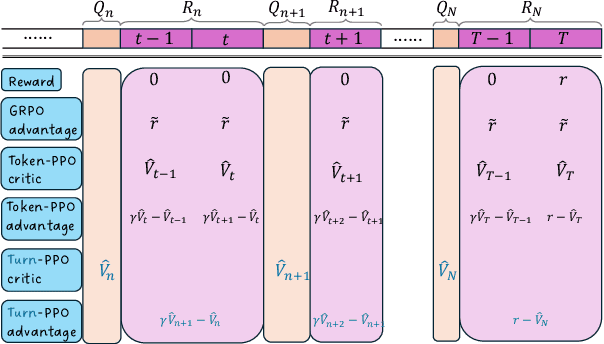

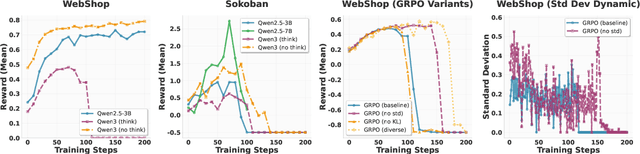
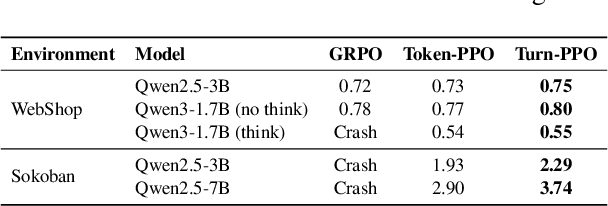
Reinforcement learning (RL) has re-emerged as a natural approach for training interactive LLM agents in real-world environments. However, directly applying the widely used Group Relative Policy Optimization (GRPO) algorithm to multi-turn tasks exposes notable limitations, particularly in scenarios requiring long-horizon reasoning. To address these challenges, we investigate more stable and effective advantage estimation strategies, especially for multi-turn settings. We first explore Proximal Policy Optimization (PPO) as an alternative and find it to be more robust than GRPO. To further enhance PPO in multi-turn scenarios, we introduce turn-PPO, a variant that operates on a turn-level MDP formulation, as opposed to the commonly used token-level MDP. Our results on the WebShop and Sokoban datasets demonstrate the effectiveness of turn-PPO, both with and without long reasoning components.
Impact of Parameter Sparsity on Stochastic Gradient MCMC Methods for Bayesian Deep Learning
Feb 08, 2022Bayesian methods hold significant promise for improving the uncertainty quantification ability and robustness of deep neural network models. Recent research has seen the investigation of a number of approximate Bayesian inference methods for deep neural networks, building on both the variational Bayesian and Markov chain Monte Carlo (MCMC) frameworks. A fundamental issue with MCMC methods is that the improvements they enable are obtained at the expense of increased computation time and model storage costs. In this paper, we investigate the potential of sparse network structures to flexibly trade-off model storage costs and inference run time against predictive performance and uncertainty quantification ability. We use stochastic gradient MCMC methods as the core Bayesian inference method and consider a variety of approaches for selecting sparse network structures. Surprisingly, our results show that certain classes of randomly selected substructures can perform as well as substructures derived from state-of-the-art iterative pruning methods while drastically reducing model training times.
Challenges and Opportunities in Approximate Bayesian Deep Learning for Intelligent IoT Systems
Dec 03, 2021Approximate Bayesian deep learning methods hold significant promise for addressing several issues that occur when deploying deep learning components in intelligent systems, including mitigating the occurrence of over-confident errors and providing enhanced robustness to out of distribution examples. However, the computational requirements of existing approximate Bayesian inference methods can make them ill-suited for deployment in intelligent IoT systems that include lower-powered edge devices. In this paper, we present a range of approximate Bayesian inference methods for supervised deep learning and highlight the challenges and opportunities when applying these methods on current edge hardware. We highlight several potential solutions to decreasing model storage requirements and improving computational scalability, including model pruning and distillation methods.
Post-hoc loss-calibration for Bayesian neural networks
Jun 13, 2021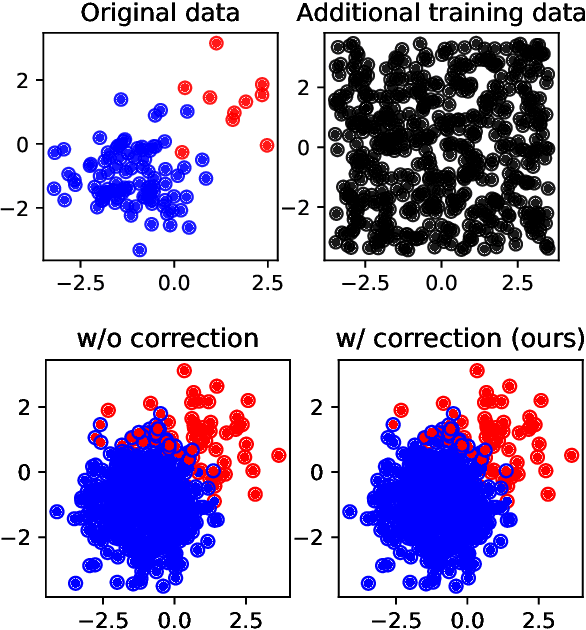
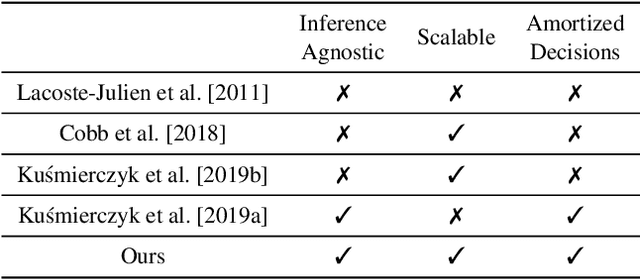
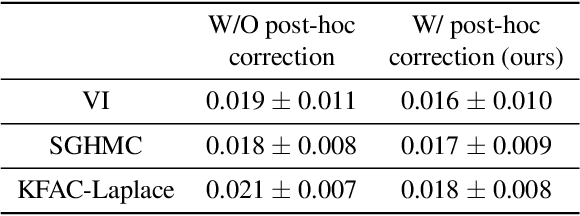

Bayesian decision theory provides an elegant framework for acting optimally under uncertainty when tractable posterior distributions are available. Modern Bayesian models, however, typically involve intractable posteriors that are approximated with, potentially crude, surrogates. This difficulty has engendered loss-calibrated techniques that aim to learn posterior approximations that favor high-utility decisions. In this paper, focusing on Bayesian neural networks, we develop methods for correcting approximate posterior predictive distributions encouraging them to prefer high-utility decisions. In contrast to previous work, our approach is agnostic to the choice of the approximate inference algorithm, allows for efficient test time decision making through amortization, and empirically produces higher quality decisions. We demonstrate the effectiveness of our approach through controlled experiments spanning a diversity of tasks and datasets.
URSABench: Comprehensive Benchmarking of Approximate Bayesian Inference Methods for Deep Neural Networks
Jul 08, 2020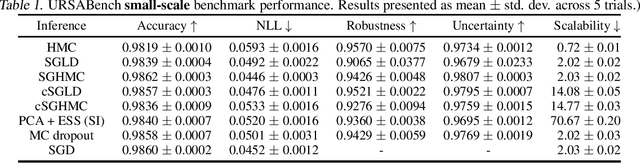



While deep learning methods continue to improve in predictive accuracy on a wide range of application domains, significant issues remain with other aspects of their performance including their ability to quantify uncertainty and their robustness. Recent advances in approximate Bayesian inference hold significant promise for addressing these concerns, but the computational scalability of these methods can be problematic when applied to large-scale models. In this paper, we describe initial work on the development ofURSABench(the Uncertainty, Robustness, Scalability, and Accu-racy Benchmark), an open-source suite of bench-marking tools for comprehensive assessment of approximate Bayesian inference methods with a focus on deep learning-based classification tasks
Generalized Bayesian Posterior Expectation Distillation for Deep Neural Networks
May 16, 2020
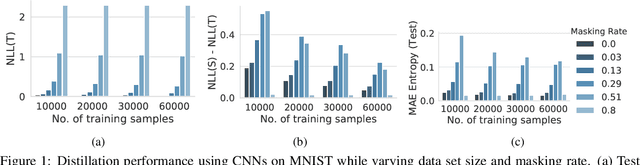


In this paper, we present a general framework for distilling expectations with respect to the Bayesian posterior distribution of a deep neural network classifier, extending prior work on the Bayesian Dark Knowledge framework. The proposed framework takes as input "teacher" and student model architectures and a general posterior expectation of interest. The distillation method performs an online compression of the selected posterior expectation using iteratively generated Monte Carlo samples. We focus on the posterior predictive distribution and expected entropy as distillation targets. We investigate several aspects of this framework including the impact of uncertainty and the choice of student model architecture. We study methods for student model architecture search from a speed-storage-accuracy perspective and evaluate down-stream tasks leveraging entropy distillation including uncertainty ranking and out-of-distribution detection.
Assessing the Adversarial Robustness of Monte Carlo and Distillation Methods for Deep Bayesian Neural Network Classification
Feb 07, 2020
In this paper, we consider the problem of assessing the adversarial robustness of deep neural network models under both Markov chain Monte Carlo (MCMC) and Bayesian Dark Knowledge (BDK) inference approximations. We characterize the robustness of each method to two types of adversarial attacks: the fast gradient sign method (FGSM) and projected gradient descent (PGD). We show that full MCMC-based inference has excellent robustness, significantly outperforming standard point estimation-based learning. On the other hand, BDK provides marginal improvements. As an additional contribution, we present a storage-efficient approach to computing adversarial examples for large Monte Carlo ensembles using both the FGSM and PGD attacks.
Assessing the Robustness of Bayesian Dark Knowledge to Posterior Uncertainty
Jun 10, 2019

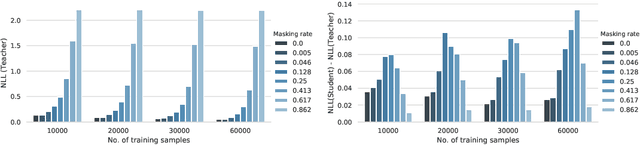
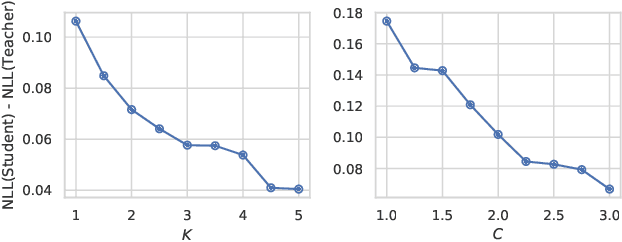
Bayesian Dark Knowledge is a method for compressing the posterior predictive distribution of a neural network model into a more compact form. Specifically, the method attempts to compress a Monte Carlo approximation to the parameter posterior into a single network representing the posterior predictive distribution. Further, the authors show that this approach is successful in the classification setting using a student network whose architecture matches that of a single network in the teacher ensemble. In this work, we examine the robustness of Bayesian Dark Knowledge to higher levels of posterior uncertainty. We show that using a student network that matches the teacher architecture may fail to yield acceptable performance. We study an approach to close the resulting performance gap by increasing student model capacity.