 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Multi-Device Inference Acceleration for Transformer Models
May 25, 2025Transformer models power many AI applications but suffer from high inference latency, limiting their use in real-time settings. Multi-device inference can reduce latency by parallelizing computation. Yet, existing methods require high inter-device bandwidth, making them impractical for bandwidth-constrained environments. We propose ASTRA, a communication-efficient framework that accelerates Transformer inference through a novel integration of sequence parallelism and a Mixed-Precision Attention mechanism designed to minimize inter-device communication. ASTRA compresses non-local token embeddings via vector quantization and preserves task accuracy through two optimizations, Noise-Augmented Quantization and Distributed Class Tokens. Experiments on ViT and GPT2 across vision and NLP tasks show that ASTRA achieves up to 2.64X speedups over single-device inference and up to 15.25X speedups over state-of-the-art multi-device inferences, while operating under bandwidths as low as 10 Mbps. ASTRA is open-sourced at https://github.com/xl1990/Astra.
Aligned Vector Quantization for Edge-Cloud Collabrative Vision-Language Models
Nov 08, 2024



Vision Language Models (VLMs) are central to Visual Question Answering (VQA) systems and are typically deployed in the cloud due to their high computational demands. However, this cloud-only approach underutilizes edge computational resources and requires significant bandwidth for transmitting raw images. In this paper, we introduce an edge-cloud collaborative VQA system, called LLaVA-AlignedVQ, which features a novel Aligned Vector Quantization algorithm (AlignedVQ) that efficiently compress intermediate features without compromising accuracy to support partitioned execution. Our experiments demonstrate that LLaVA-AlignedVQ achieves approximately 1365x compression rate of intermediate features, reducing data transmission overhead by 96.8% compared to transmitting JPEG90-compressed images to the cloud. LLaVA-AlignedVQ achieves an inference speedup of 2-15x while maintaining high accuracy, remaining within -2.23% to +1.6% of the original model's accuracy performance across eight VQA datasets, compared to the cloud-only solution.
In-Situ Fine-Tuning of Wildlife Models in IoT-Enabled Camera Traps for Efficient Adaptation
Sep 12, 2024



Wildlife monitoring via camera traps has become an essential tool in ecology, but the deployment of machine learning models for on-device animal classification faces significant challenges due to domain shifts and resource constraints. This paper introduces WildFit, a novel approach that reconciles the conflicting goals of achieving high domain generalization performance and ensuring efficient inference for camera trap applications. WildFit leverages continuous background-aware model fine-tuning to deploy ML models tailored to the current location and time window, allowing it to maintain robust classification accuracy in the new environment without requiring significant computational resources. This is achieved by background-aware data synthesis, which generates training images representing the new domain by blending background images with animal images from the source domain. We further enhance fine-tuning effectiveness through background drift detection and class distribution drift detection, which optimize the quality of synthesized data and improve generalization performance. Our extensive evaluation across multiple camera trap datasets demonstrates that WildFit achieves significant improvements in classification accuracy and computational efficiency compared to traditional approaches.
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024



Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.
Efficient IoT Inference via Context-Awareness
Oct 29, 2023While existing strategies for optimizing deep learning-based classification models on low-power platforms assume the models are trained on all classes of interest, this paper posits that adopting context-awareness i.e. focusing solely on the likely classes in the current context, can substantially enhance performance in resource-constrained environments. We propose a new paradigm, CACTUS, for scalable and efficient context-aware classification where a micro-classifier recognizes a small set of classes relevant to the current context and, when context change happens, rapidly switches to another suitable micro-classifier. CACTUS has several innovations including optimizing the training cost of context-aware classifiers, enabling on-the-fly context-aware switching between classifiers, and selecting the best context-aware classifiers given limited resources. We show that CACTUS achieves significant benefits in accuracy, latency, and compute budget across a range of datasets and IoT platforms.
Heteroskedastic Geospatial Tracking with Distributed Camera Networks
Jun 04, 2023Visual object tracking has seen significant progress in recent years. However, the vast majority of this work focuses on tracking objects within the image plane of a single camera and ignores the uncertainty associated with predicted object locations. In this work, we focus on the geospatial object tracking problem using data from a distributed camera network. The goal is to predict an object's track in geospatial coordinates along with uncertainty over the object's location while respecting communication constraints that prohibit centralizing raw image data. We present a novel single-object geospatial tracking data set that includes high-accuracy ground truth object locations and video data from a network of four cameras. We present a modeling framework for addressing this task including a novel backbone model and explore how uncertainty calibration and fine-tuning through a differentiable tracker affect performance.
Eulerian Phase-based Motion Magnification for High-Fidelity Vital Sign Estimation with Radar in Clinical Settings
Dec 03, 2022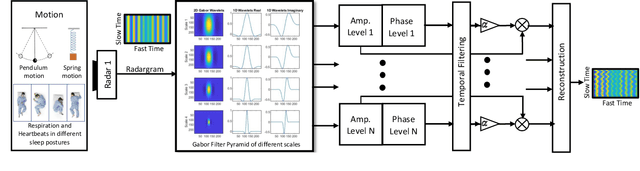
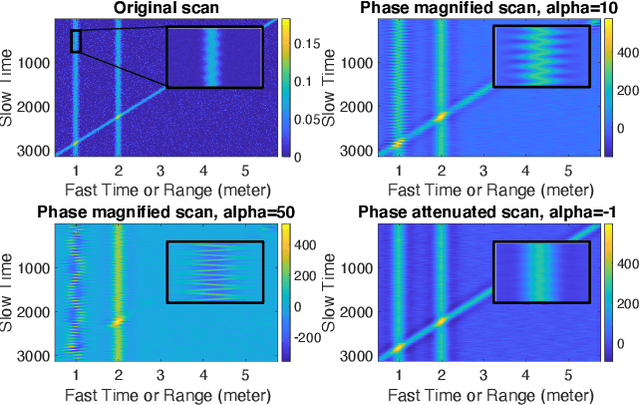
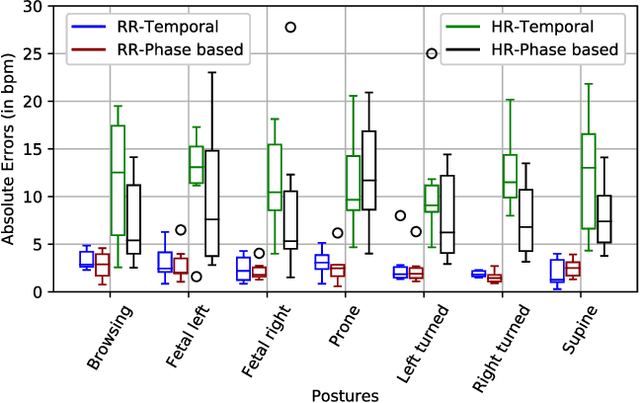
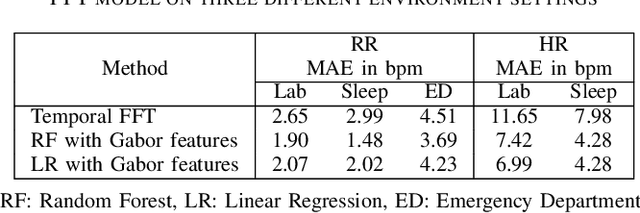
Efficient and accurate detection of subtle motion generated from small objects in noisy environments, as needed for vital sign monitoring, is challenging, but can be substantially improved with magnification. We developed a complex Gabor filter-based decomposition method to amplify phases at different spatial wavelength levels to magnify motion and extract 1D motion signals for fundamental frequency estimation. The phase-based complex Gabor filter outputs are processed and then used to train machine learning models that predict respiration and heart rate with greater accuracy. We show that our proposed technique performs better than the conventional temporal FFT-based method in clinical settings, such as sleep laboratories and emergency departments, as well for a variety of human postures.
PhyMask: Robust Sensing of Brain Activity and Physiological Signals During Sleep with an All-textile Eye Mask
Jun 13, 2021

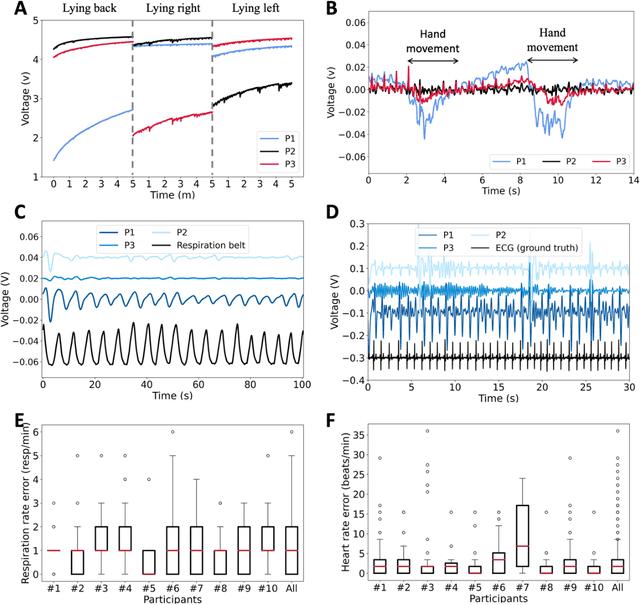
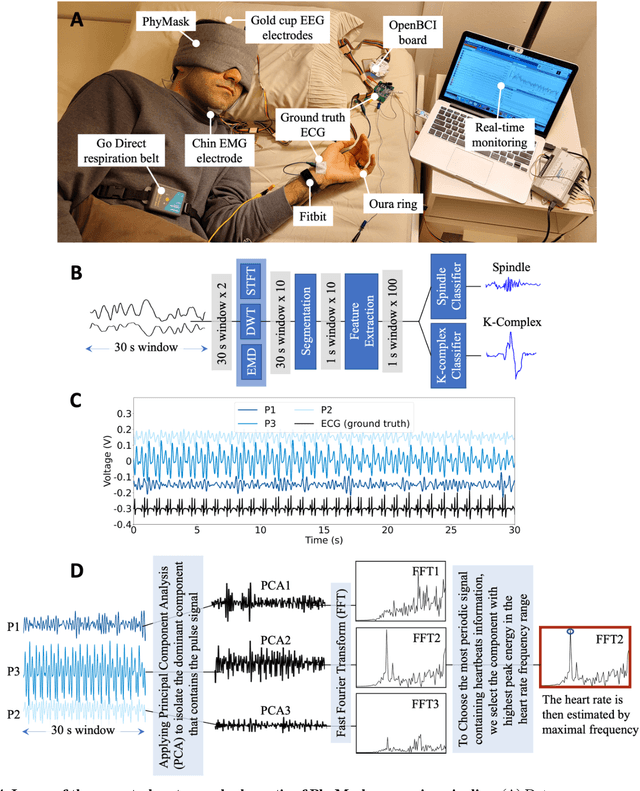
Clinical-grade wearable sleep monitoring is a challenging problem since it requires concurrently monitoring brain activity, eye movement, muscle activity, cardio-respiratory features and gross body movements. This requires multiple sensors to be worn at different locations as well as uncomfortable adhesives and discrete electronic components to be placed on the head. As a result, existing wearables either compromise comfort or compromise accuracy in tracking sleep variables. We propose PhyMask, an all-textile sleep monitoring solution that is practical and comfortable for continuous use and that acquires all signals of interest to sleep solely using comfortable textile sensors placed on the head. We show that PhyMask can be used to accurately measure sleep stages and advanced sleep markers such as spindles and k-complexes robustly in the real-world setting. We validate PhyMask against polysomnography and show that it significantly outperforms two commercially-available sleep tracking wearables, Fitbit and Oura Ring.