 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexLoc: Conditional Neural Networks for Zero-Shot Sensor Perspective Invariance in Object Localization with Distributed Multimodal Sensors
Jun 10, 2024



Localization is a critical technology for various applications ranging from navigation and surveillance to assisted living. Localization systems typically fuse information from sensors viewing the scene from different perspectives to estimate the target location while also employing multiple modalities for enhanced robustness and accuracy. Recently, such systems have employed end-to-end deep neural models trained on large datasets due to their superior performance and ability to handle data from diverse sensor modalities. However, such neural models are often trained on data collected from a particular set of sensor poses (i.e., locations and orientations). During real-world deployments, slight deviations from these sensor poses can result in extreme inaccuracies. To address this challenge, we introduce FlexLoc, which employs conditional neural networks to inject node perspective information to adapt the localization pipeline. Specifically, a small subset of model weights are derived from node poses at run time, enabling accurate generalization to unseen perspectives with minimal additional overhead. Our evaluations on a multimodal, multiview indoor tracking dataset showcase that FlexLoc improves the localization accuracy by almost 50% in the zero-shot case (no calibration data available) compared to the baselines. The source code of FlexLoc is available at https://github.com/nesl/FlexLoc.
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024



Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.
MisGAN: Learning from Incomplete Data with Generative Adversarial Networks
Feb 25, 2019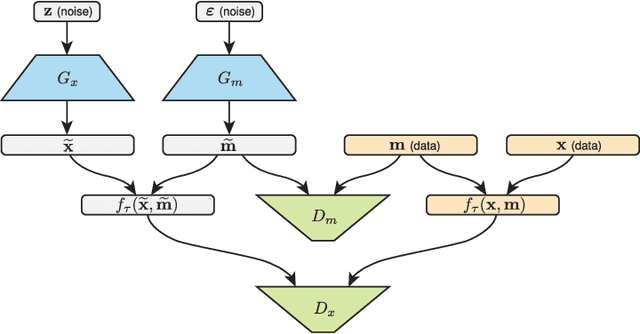
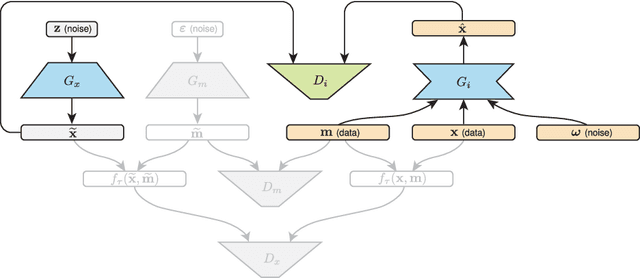


Generative adversarial networks (GANs) have been shown to provide an effective way to model complex distributions and have obtained impressive results on various challenging tasks. However, typical GANs require fully-observed data during training. In this paper, we present a GAN-based framework for learning from complex, high-dimensional incomplete data. The proposed framework learns a complete data generator along with a mask generator that models the missing data distribution. We further demonstrate how to impute missing data by equipping our framework with an adversarially trained imputer. We evaluate the proposed framework using a series of experiments with several types of missing data processes under the missing completely at random assumption.
Out-of-Sample Extension for Dimensionality Reduction of Noisy Time Series
Jul 29, 2017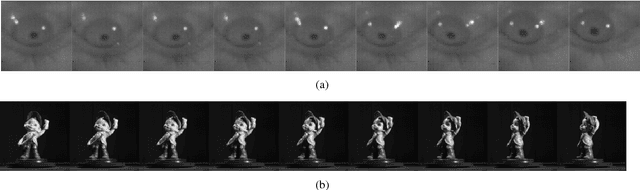

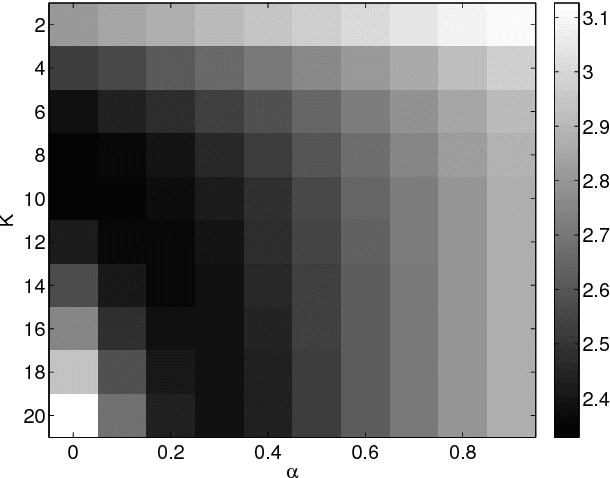
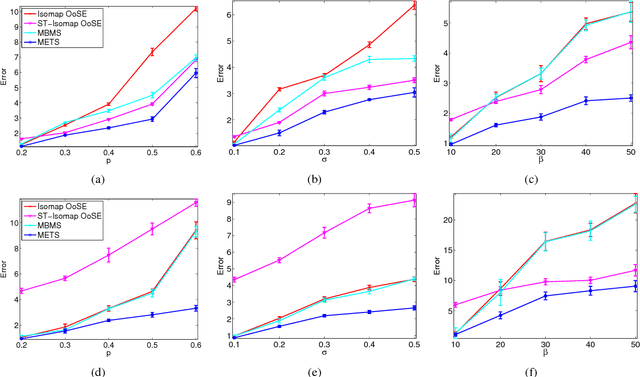
This paper proposes an out-of-sample extension framework for a global manifold learning algorithm (Isomap) that uses temporal information in out-of-sample points in order to make the embedding more robust to noise and artifacts. Given a set of noise-free training data and its embedding, the proposed framework extends the embedding for a noisy time series. This is achieved by adding a spatio-temporal compactness term to the optimization objective of the embedding. To the best of our knowledge, this is the first method for out-of-sample extension of manifold embeddings that leverages timing information available for the extension set. Experimental results demonstrate that our out-of-sample extension algorithm renders a more robust and accurate embedding of sequentially ordered image data in the presence of various noise and artifacts when compared to other timing-aware embeddings. Additionally, we show that an out-of-sample extension framework based on the proposed algorithm outperforms the state of the art in eye-gaze estimation.
A scalable end-to-end Gaussian process adapter for irregularly sampled time series classification
Oct 28, 2016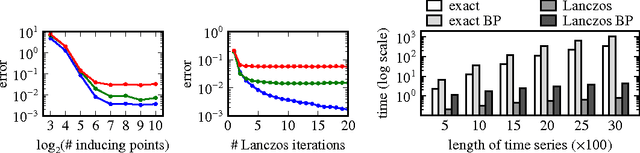

We present a general framework for classification of sparse and irregularly-sampled time series. The properties of such time series can result in substantial uncertainty about the values of the underlying temporal processes, while making the data difficult to deal with using standard classification methods that assume fixed-dimensional feature spaces. To address these challenges, we propose an uncertainty-aware classification framework based on a special computational layer we refer to as the Gaussian process adapter that can connect irregularly sampled time series data to any black-box classifier learnable using gradient descent. We show how to scale up the required computations based on combining the structured kernel interpolation framework and the Lanczos approximation method, and how to discriminatively train the Gaussian process adapter in combination with a number of classifiers end-to-end using backpropagation.
Learning Shallow Detection Cascades for Wearable Sensor-Based Mobile Health Applications
Jul 13, 2016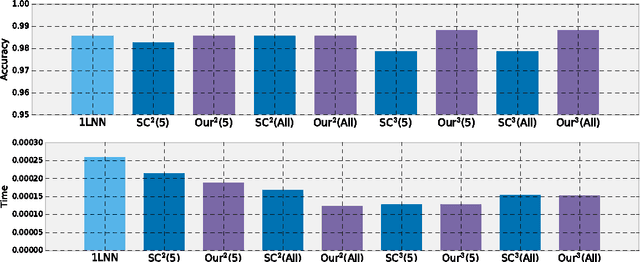
The field of mobile health aims to leverage recent advances in wearable on-body sensing technology and smart phone computing capabilities to develop systems that can monitor health states and deliver just-in-time adaptive interventions. However, existing work has largely focused on analyzing collected data in the off-line setting. In this paper, we propose a novel approach to learning shallow detection cascades developed explicitly for use in a real-time wearable-phone or wearable-phone-cloud systems. We apply our approach to the problem of cigarette smoking detection from a combination of wrist-worn actigraphy data and respiration chest band data using two and three stage cascades.
Active Collaborative Filtering
Oct 19, 2012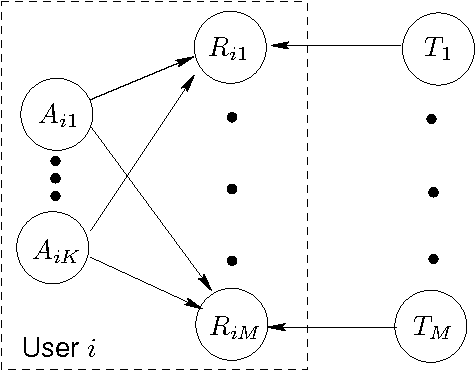

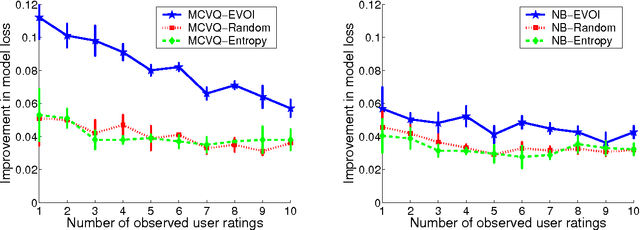
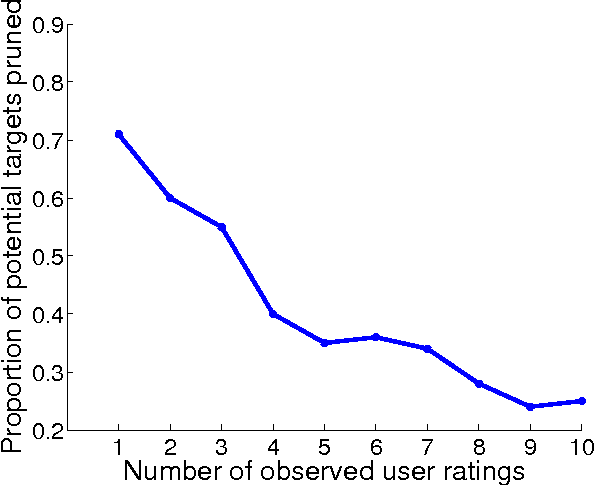
Collaborative filtering (CF) allows the preferences of multiple users to be pooled to make recommendations regarding unseen products. We consider in this paper the problem of online and interactive CF: given the current ratings associated with a user, what queries (new ratings) would most improve the quality of the recommendations made? We cast this terms of expected value of information (EVOI); but the online computational cost of computing optimal queries is prohibitive. We show how offline prototyping and computation of bounds on EVOI can be used to dramatically reduce the required online computation. The framework we develop is general, but we focus on derivations and empirical study in the specific case of the multiple-cause vector quantization model.
Collaborative Filtering and the Missing at Random Assumption
Jun 20, 2012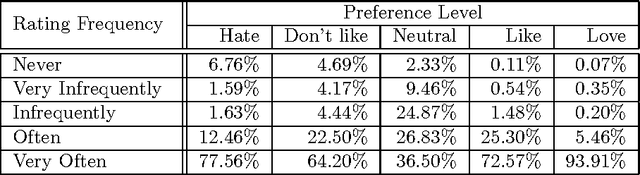
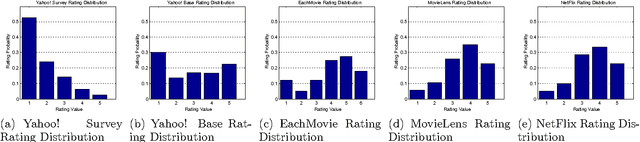
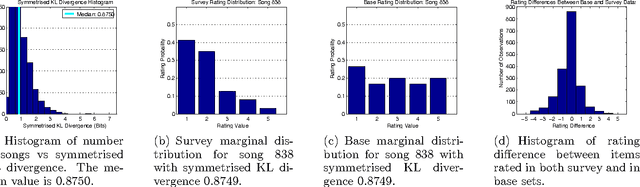

Rating prediction is an important application, and a popular research topic in collaborative filtering. However, both the validity of learning algorithms, and the validity of standard testing procedures rest on the assumption that missing ratings are missing at random (MAR). In this paper we present the results of a user study in which we collect a random sample of ratings from current users of an online radio service. An analysis of the rating data collected in the study shows that the sample of random ratings has markedly different properties than ratings of user-selected songs. When asked to report on their own rating behaviour, a large number of users indicate they believe their opinion of a song does affect whether they choose to rate that song, a violation of the MAR condition. Finally, we present experimental results showing that incorporating an explicit model of the missing data mechanism can lead to significant improvements in prediction performance on the random sample of ratings.
Group Sparse Priors for Covariance Estimation
May 09, 2012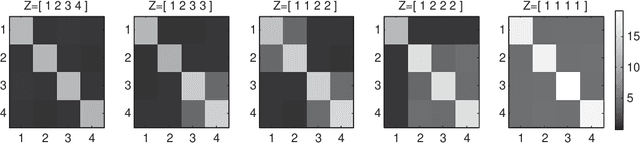
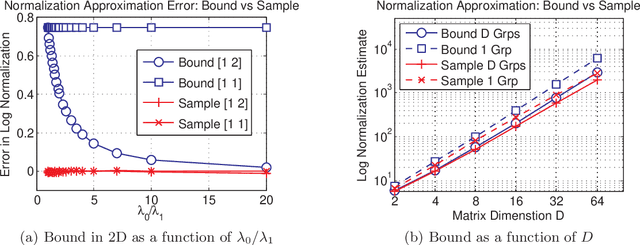
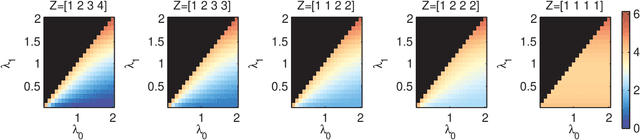
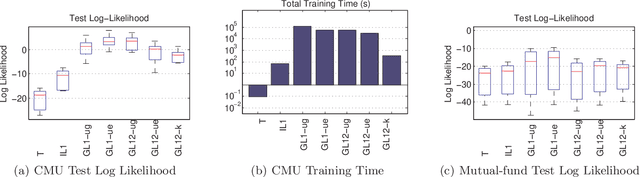
Recently it has become popular to learn sparse Gaussian graphical models (GGMs) by imposing l1 or group l1,2 penalties on the elements of the precision matrix. Thispenalized likelihood approach results in a tractable convex optimization problem. In this paper, we reinterpret these results as performing MAP estimation under a novel prior which we call the group l1 and l1,2 positivedefinite matrix distributions. This enables us to build a hierarchical model in which the l1 regularization terms vary depending on which group the entries are assigned to, which in turn allows us to learn block structured sparse GGMs with unknown group assignments. Exact inference in this hierarchical model is intractable, due to the need to compute the normalization constant of these matrix distributions. However, we derive upper bounds on the partition functions, which lets us use fast variational inference (optimizing a lower bound on the joint posterior). We show that on two real world data sets (motion capture and financial data), our method which infers the block structure outperforms a method that uses a fixed block structure, which in turn outperforms baseline methods that ignore block structure.
Asymptotic Efficiency of Deterministic Estimators for Discrete Energy-Based Models: Ratio Matching and Pseudolikelihood
Feb 14, 2012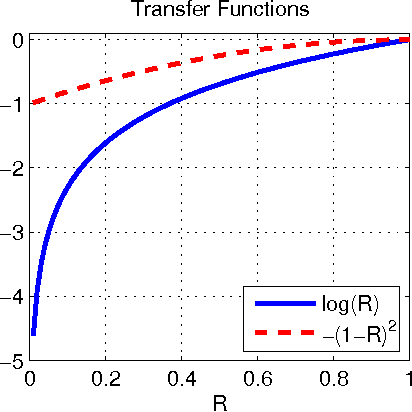
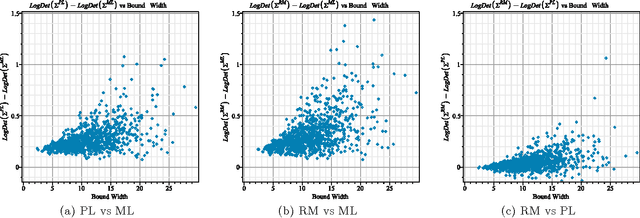
Standard maximum likelihood estimation cannot be applied to discrete energy-based models in the general case because the computation of exact model probabilities is intractable. Recent research has seen the proposal of several new estimators designed specifically to overcome this intractability, but virtually nothing is known about their theoretical properties. In this paper, we present a generalized estimator that unifies many of the classical and recently proposed estimators. We use results from the standard asymptotic theory for M-estimators to derive a generic expression for the asymptotic covariance matrix of our generalized estimator. We apply these results to study the relative statistical efficiency of classical pseudolikelihood and the recently-proposed ratio matching estimator.