 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperBench: Standardizing and Scaling Synthetic Evaluation for Hyperspectral Super-Resolution
May 20, 2026Hyperspectral super-resolution (HSR) reconstructs a high-spatial-resolution hyperspectral image by fusing a low-resolution hyperspectral image (LR-HSI) with a high-resolution multispectral image (HR-MSI). In the absence of real-world paired data, HSR methods are evaluated almost exclusively on synthetic experiments derived from hyperspectral datasets through Wald's protocol. Despite the protocol's widespread adoption, its practical implementation varies markedly across research works, typically relying on a single (usually Gaussian) or very few point spread functions (PSFs), one or two spectral response functions (SRFs), and a couple of spatial downsampling factors. As a result, reported performance figures are difficult to compare across the literature, in addition to being often difficult to reproduce; furthermore, they may not generalize across realistic sensing conditions. We introduce HyperBench, a unified and extensible framework that standardizes synthetic experimentation for HSR. HyperBench supports diverse degradation configurations spanning ten PSFs, four SRFs derived from operational multispectral sensors, configurable spatial downsampling factors, and matched additive white Gaussian noise; its goal is to automate large-scale evaluation and structured logging. By decoupling model development from experimental design, the framework enables reproducible, apples-to-apples cross-method comparison with minimal friction. We use HyperBench to evaluate six recently proposed HSR methods across a 70-configuration sweep on four widely used hyperspectral scenes and observe that the inter-method PSNR spread widens from approximately 5 dB on the easiest PSF to over 13 dB on the hardest - a fragility that is structurally invisible to the prevailing single-configuration evaluation protocol. HyperBench code is available at https://github.com/ritikgshah/HyperBench .
Affine Subspace Models and Clustering for Patch-Based Image Denoising
Dec 08, 2025Image tile-based approaches are popular in many image processing applications such as denoising (e.g., non-local means). A key step in their use is grouping the images into clusters, which usually proceeds iteratively splitting the images into clusters and fitting a model for the images in each cluster. Linear subspaces have emerged as a suitable model for tile clusters; however, they are not well matched to images patches given that images are non-negative and thus not distributed around the origin in the tile vector space. We study the use of affine subspace models for the clusters to better match the geometric structure of the image tile vector space. We also present a simple denoising algorithm that relies on the affine subspace clustering model using least squares projection. We review several algorithmic approaches to solve the affine subspace clustering problem and show experimental results that highlight the performance improvements in clustering and denoising.
SpectraLift: Physics-Guided Spectral-Inversion Network for Self-Supervised Hyperspectral Image Super-Resolution
Jul 17, 2025



High-spatial-resolution hyperspectral images (HSI) are essential for applications such as remote sensing and medical imaging, yet HSI sensors inherently trade spatial detail for spectral richness. Fusing high-spatial-resolution multispectral images (HR-MSI) with low-spatial-resolution hyperspectral images (LR-HSI) is a promising route to recover fine spatial structures without sacrificing spectral fidelity. Most state-of-the-art methods for HSI-MSI fusion demand point spread function (PSF) calibration or ground truth high resolution HSI (HR-HSI), both of which are impractical to obtain in real world settings. We present SpectraLift, a fully self-supervised framework that fuses LR-HSI and HR-MSI inputs using only the MSI's Spectral Response Function (SRF). SpectraLift trains a lightweight per-pixel multi-layer perceptron (MLP) network using ($i$)~a synthetic low-spatial-resolution multispectral image (LR-MSI) obtained by applying the SRF to the LR-HSI as input, ($ii$)~the LR-HSI as the output, and ($iii$)~an $\ell_1$ spectral reconstruction loss between the estimated and true LR-HSI as the optimization objective. At inference, SpectraLift uses the trained network to map the HR-MSI pixel-wise into a HR-HSI estimate. SpectraLift converges in minutes, is agnostic to spatial blur and resolution, and outperforms state-of-the-art methods on PSNR, SAM, SSIM, and RMSE benchmarks.
Explainable Machine Learning for Scientific Insights and Discoveries
May 21, 2019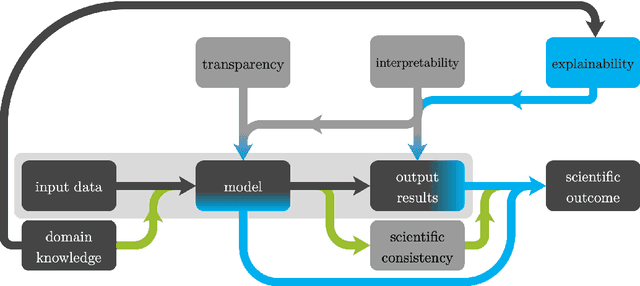
Machine learning methods have been remarkably successful for a wide range of application areas in the extraction of essential information from data. An exciting and relatively recent development is the uptake of machine learning in the natural sciences, where the major goal is to obtain novel scientific insights and discoveries from observational or simulated data. A prerequisite for obtaining a scientific outcome is domain knowledge, which is needed to gain explainability, but also to enhance scientific consistency. In this article we review explainable machine learning in view of applications in the natural sciences and discuss three core elements which we identified as relevant in this context: transparency, interpretability, and explainability. With respect to these core elements, we provide a survey of recent scientific works incorporating machine learning, and in particular to the way that explainable machine learning is used in their respective application areas.
Few-Shot Learning-Based Human Activity Recognition
Mar 25, 2019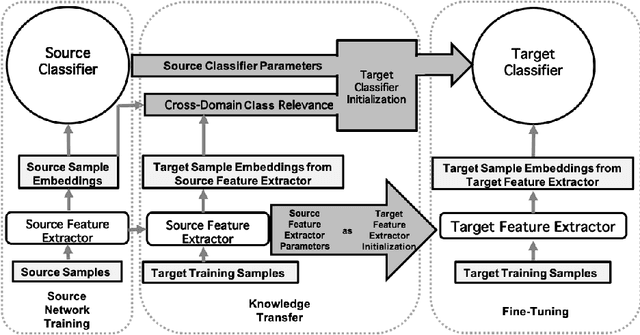
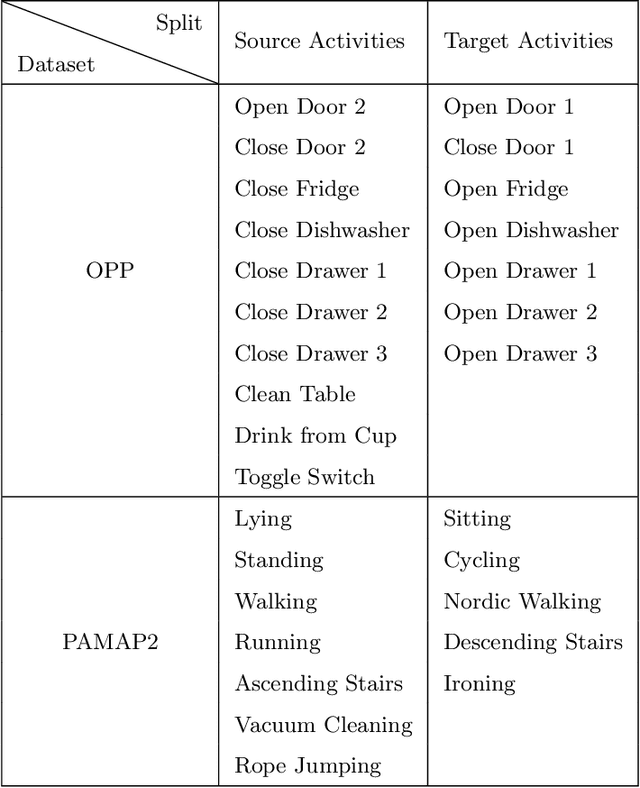
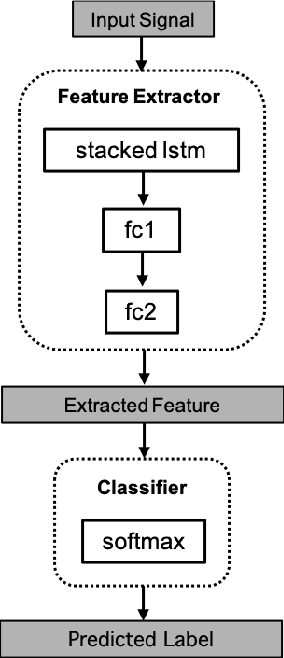
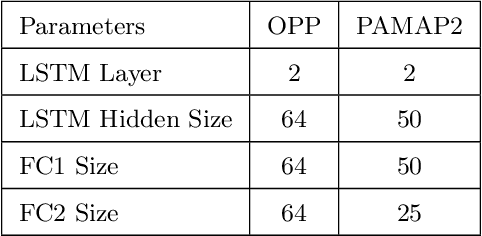
Few-shot learning is a technique to learn a model with a very small amount of labeled training data by transferring knowledge from relevant tasks. In this paper, we propose a few-shot learning method for wearable sensor based human activity recognition, a technique that seeks high-level human activity knowledge from low-level sensor inputs. Due to the high costs to obtain human generated activity data and the ubiquitous similarities between activity modes, it can be more efficient to borrow information from existing activity recognition models than to collect more data to train a new model from scratch when only a few data are available for model training. The proposed few-shot human activity recognition method leverages a deep learning model for feature extraction and classification while knowledge transfer is performed in the manner of model parameter transfer. In order to alleviate negative transfer, we propose a metric to measure cross-domain class-wise relevance so that knowledge of higher relevance is assigned larger weights during knowledge transfer. Promising results in extensive experiments show the advantages of the proposed approach.
Autoencoder Based Sample Selection for Self-Taught Learning
Aug 05, 2018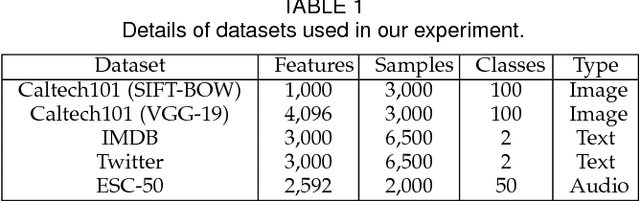
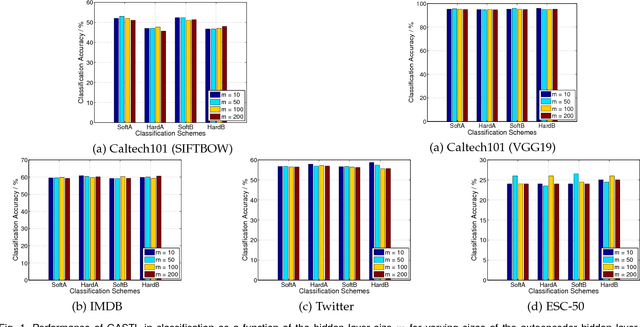
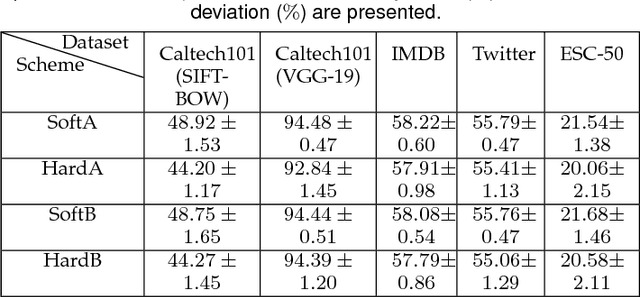
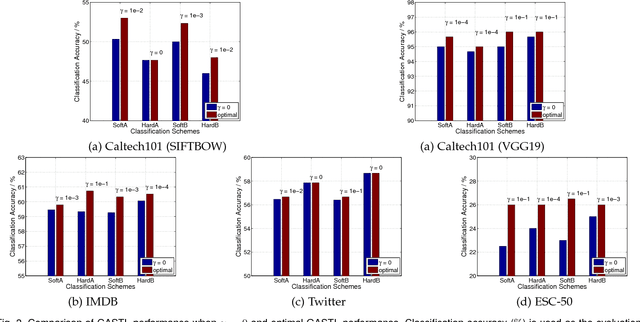
Self-taught learning is a technique that uses a large number of unlabeled data as source samples to improve the task performance on target samples. Compared with other transfer learning techniques, self-taught learning can be applied to a broader set of scenarios due to the loose restrictions on source data. However, knowledge transferred from source samples that are not sufficiently related to the target domain may negatively influence the target learner, which is referred to as negative transfer. In this paper, we propose a metric for the relevance between a source sample and target samples. To be more specific, both source and target samples are reconstructed through a single-layer autoencoder with a linear relationship between source samples and target samples simultaneously enforced. An l_{2,1}-norm sparsity constraint is imposed on the transformation matrix to identify source samples relevant to the target domain. Source domain samples that are deemed relevant are assigned pseudo-labels reflecting their relevance to target domain samples, and are combined with target samples in order to provide an expanded training set for classifier training. Local data structures are also preserved during source sample selection through spectral graph analysis. Promising results in extensive experiments show the advantages of the proposed approach.
Graph Autoencoder-Based Unsupervised Feature Selection with Broad and Local Data Structure Preservation
Apr 21, 2018
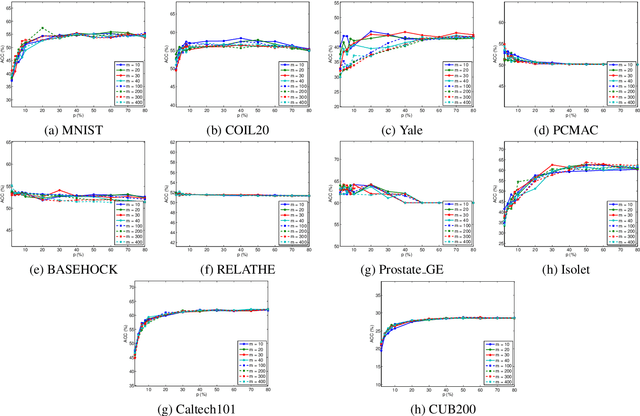

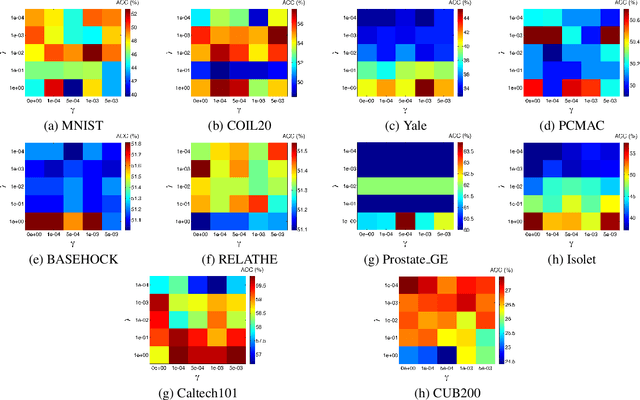
Feature selection is a dimensionality reduction technique that selects a subset of representative features from high dimensional data by eliminating irrelevant and redundant features. Recently, feature selection combined with sparse learning has attracted significant attention due to its outstanding performance compared with traditional feature selection methods that ignores correlation between features. These works first map data onto a low-dimensional subspace and then select features by posing a sparsity constraint on the transformation matrix. However, they are restricted by design to linear data transformation, a potential drawback given that the underlying correlation structures of data are often non-linear. To leverage a more sophisticated embedding, we propose an autoencoder-based unsupervised feature selection approach that leverages a single-layer autoencoder for a joint framework of feature selection and manifold learning. More specifically, we enforce column sparsity on the weight matrix connecting the input layer and the hidden layer, as in previous work. Additionally, we include spectral graph analysis on the projected data into the learning process to achieve local data geometry preservation from the original data space to the low-dimensional feature space. Extensive experiments are conducted on image, audio, text, and biological data. The promising experimental results validate the superiority of the proposed method.
Out-of-Sample Extension for Dimensionality Reduction of Noisy Time Series
Jul 29, 2017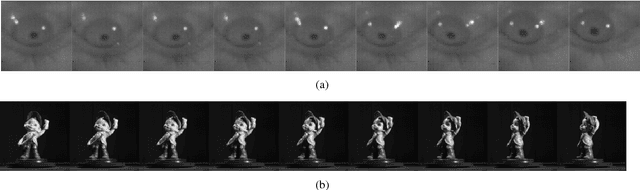

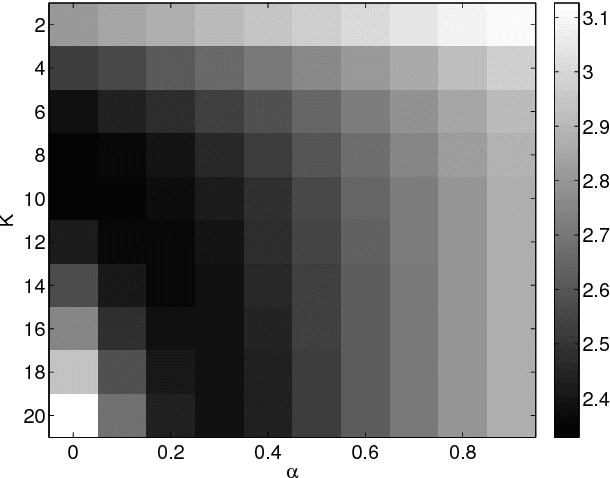
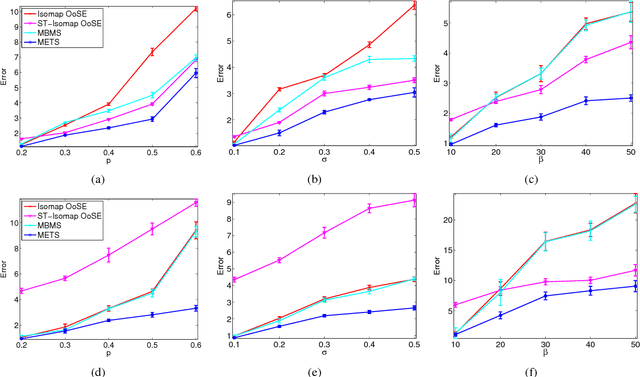
This paper proposes an out-of-sample extension framework for a global manifold learning algorithm (Isomap) that uses temporal information in out-of-sample points in order to make the embedding more robust to noise and artifacts. Given a set of noise-free training data and its embedding, the proposed framework extends the embedding for a noisy time series. This is achieved by adding a spatio-temporal compactness term to the optimization objective of the embedding. To the best of our knowledge, this is the first method for out-of-sample extension of manifold embeddings that leverages timing information available for the extension set. Experimental results demonstrate that our out-of-sample extension algorithm renders a more robust and accurate embedding of sequentially ordered image data in the presence of various noise and artifacts when compared to other timing-aware embeddings. Additionally, we show that an out-of-sample extension framework based on the proposed algorithm outperforms the state of the art in eye-gaze estimation.
Semi-Supervised Endmember Identification In Nonlinear Spectral Mixtures Via Semantic Representation
Jan 03, 2017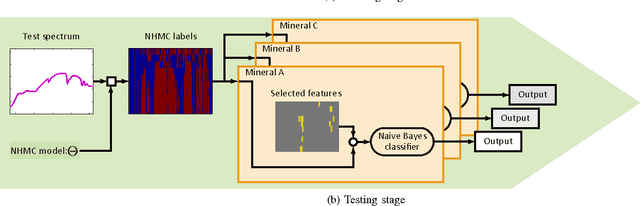
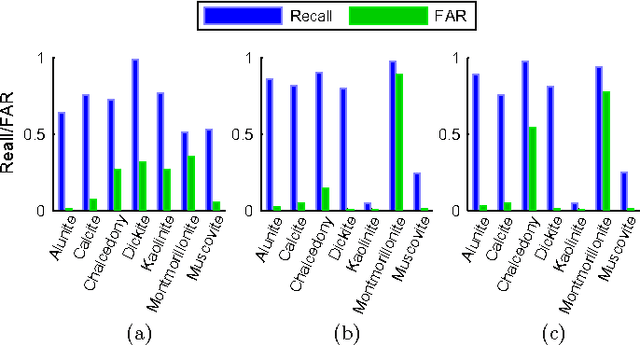
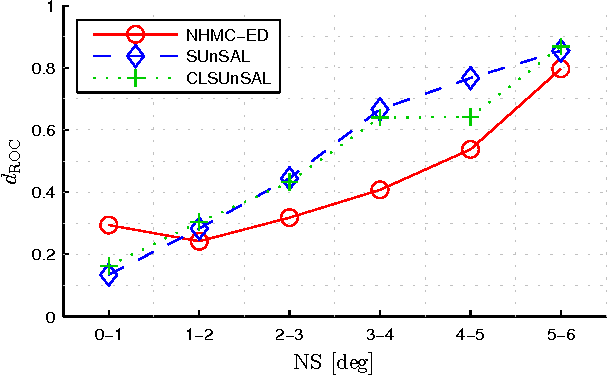
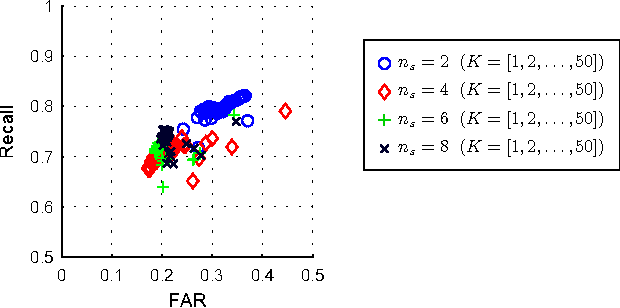
This paper proposes a new hyperspectral unmixing method for nonlinearly mixed hyperspectral data using a semantic representation in a semi-supervised fashion, assuming the availability of a spectral reference library. Existing semi-supervised unmixing algorithms select members from an endmember library that are present at each of the pixels; most such methods assume a linear mixing model. However, those methods will fail in the presence of nonlinear mixing among the observed spectra. To address this issue, we develop an endmember selection method using a recently proposed semantic spectral representation obtained via non-homogeneous hidden Markov chain (NHMC) model for a wavelet transform of the spectra. The semantic representation can encode spectrally discriminative features for any observed spectrum and, therefore, our proposed method can perform endmember selection without any assumption on the mixing model. Experimental results show that in the presence of sufficiently nonlinear mixing our proposed method outperforms dictionary-based sparse unmixing approaches based on linear models.
Perfect Recovery Conditions For Non-Negative Sparse Modeling
Sep 20, 2016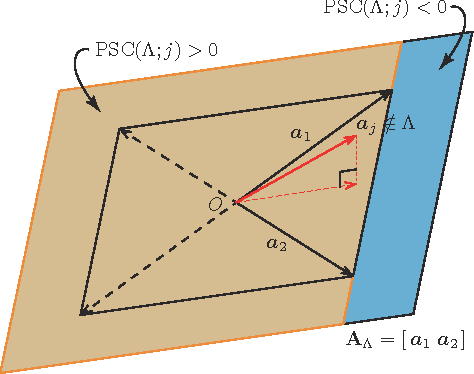
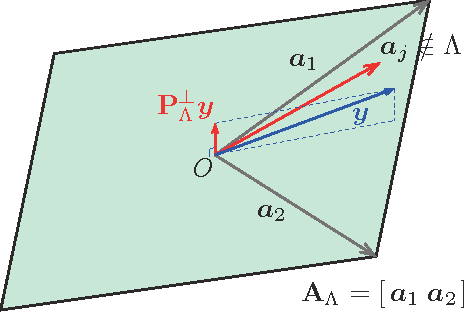

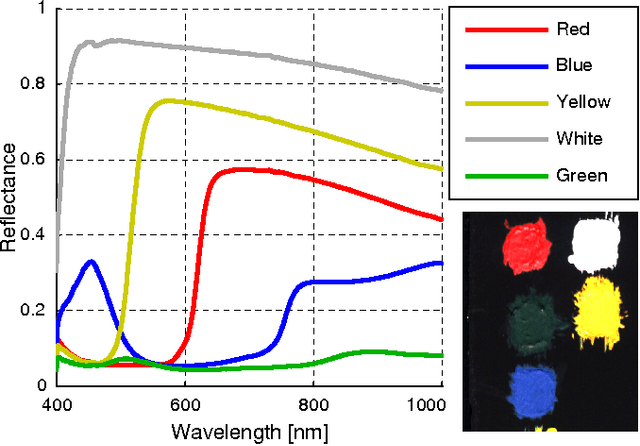
Sparse modeling has been widely and successfully used in many applications such as computer vision, machine learning, and pattern recognition. Accompanied with those applications, significant research has studied the theoretical limits and algorithm design for convex relaxations in sparse modeling. However, theoretical analyses on non-negative versions of sparse modeling are limited in the literature either to a noiseless setting or a scenario with a specific statistical noise model such as Gaussian noise. This paper studies the performance of non-negative sparse modeling in a more general scenario where the observed signals have an unknown arbitrary distortion, especially focusing on non-negativity constrained and L1-penalized least squares, and gives an exact bound for which this problem can recover the correct signal elements. We pose two conditions to guarantee the correct signal recovery: minimum coefficient condition (MCC) and nonlinearity vs. subset coherence condition (NSCC). The former defines the minimum weight for each of the correct atoms present in the signal and the latter defines the tolerable deviation from the linear model relative to the positive subset coherence (PSC), a novel type of "coherence" metric. We provide rigorous performance guarantees based on these conditions and experimentally verify their precise predictive power in a hyperspectral data unmixing application.