 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning to Guide Scientifically Relevant Categorization of Martian Terrain Images
Apr 21, 2022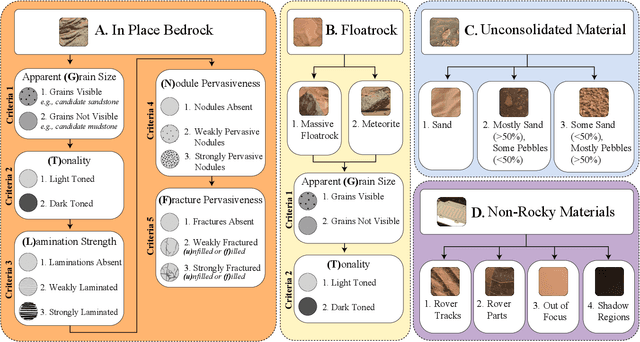

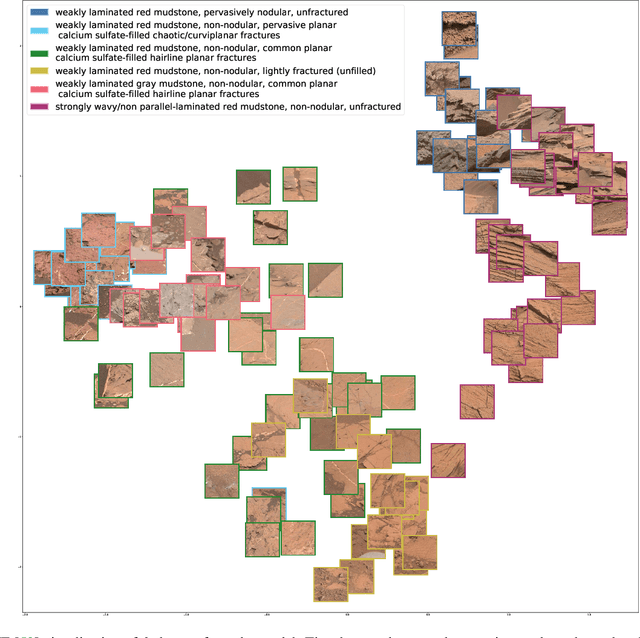

Automatic terrain recognition in Mars rover images is an important problem not just for navigation, but for scientists interested in studying rock types, and by extension, conditions of the ancient Martian paleoclimate and habitability. Existing approaches to label Martian terrain either involve the use of non-expert annotators producing taxonomies of limited granularity (e.g. soil, sand, bedrock, float rock, etc.), or rely on generic class discovery approaches that tend to produce perceptual classes such as rover parts and landscape, which are irrelevant to geologic analysis. Expert-labeled datasets containing granular geological/geomorphological terrain categories are rare or inaccessible to public, and sometimes require the extraction of relevant categorical information from complex annotations. In order to facilitate the creation of a dataset with detailed terrain categories, we present a self-supervised method that can cluster sedimentary textures in images captured from the Mast camera onboard the Curiosity rover (Mars Science Laboratory). We then present a qualitative analysis of these clusters and describe their geologic significance via the creation of a set of granular terrain categories. The precision and geologic validation of these automatically discovered clusters suggest that our methods are promising for the rapid classification of important geologic features and will therefore facilitate our long-term goal of producing a large, granular, and publicly available dataset for Mars terrain recognition.
Learning Radiative Transfer Models for Climate Change Applications in Imaging Spectroscopy
Jun 08, 2019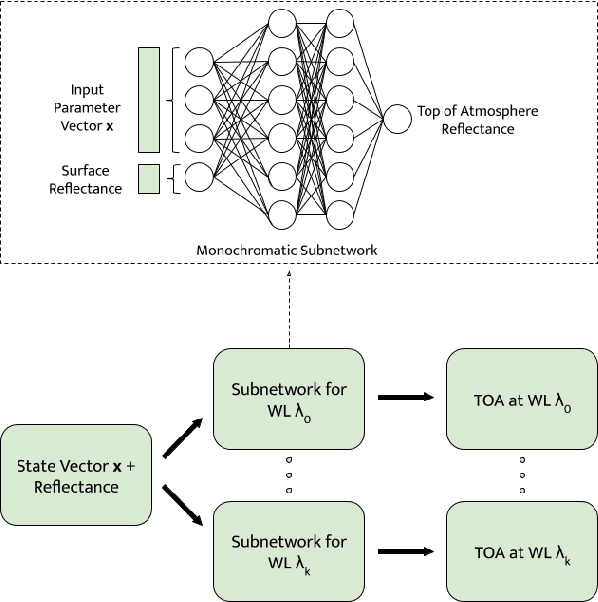
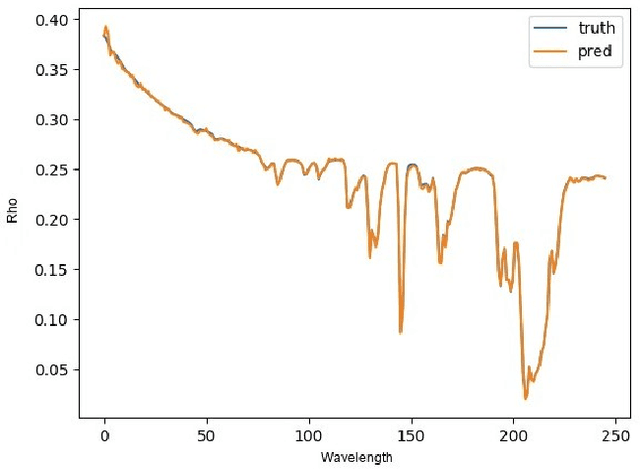
According to a recent investigation, an estimated 33-50% of the world's coral reefs have undergone degradation, believed to be as a result of climate change. A strong driver of climate change and the subsequent environmental impact are greenhouse gases such as methane. However, the exact relation climate change has to the environmental condition cannot be easily established. Remote sensing methods are increasingly being used to quantify and draw connections between rapidly changing climatic conditions and environmental impact. A crucial part of this analysis is processing spectroscopy data using radiative transfer models (RTMs) which is a computationally expensive process and limits their use with high volume imaging spectrometers. This work presents an algorithm that can efficiently emulate RTMs using neural networks leading to a multifold speedup in processing time, and yielding multiple downstream benefits.
Inverting Variational Autoencoders for Improved Generative Accuracy
Aug 24, 2017


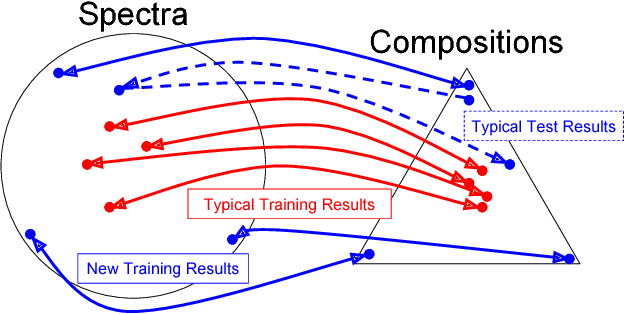
Recent advances in semi-supervised learning with deep generative models have shown promise in generalizing from small labeled datasets ($\mathbf{x},\mathbf{y}$) to large unlabeled ones ($\mathbf{x}$). In the case where the codomain has known structure, a large unfeatured dataset ($\mathbf{y}$) is potentially available. We develop a parameter-efficient, deep semi-supervised generative model for the purpose of exploiting this untapped data source. Empirical results show improved performance in disentangling latent variable semantics as well as improved discriminative prediction on Martian spectroscopic and handwritten digit domains.
On Clustering and Embedding Mixture Manifolds using a Low Rank Neighborhood Approach
Aug 12, 2017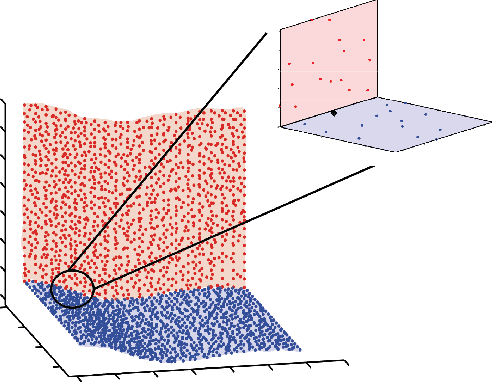
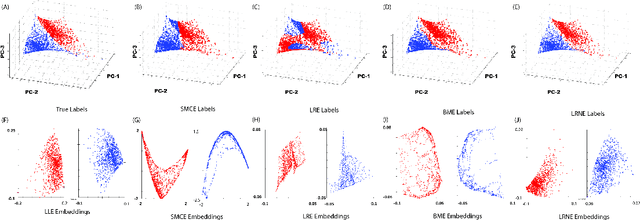
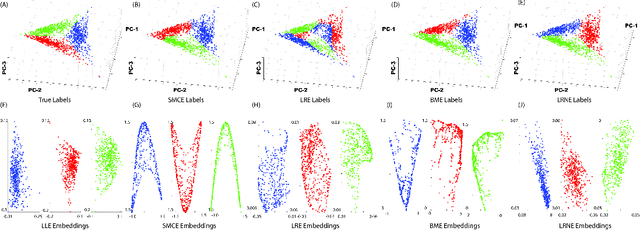

Samples from intimate (non-linear) mixtures are generally modeled as being drawn from a smooth manifold. Scenarios where the data contains multiple intimate mixtures with some constituent materials in common can be thought of as manifolds which share a boundary. Two important steps in the processing of such data are (i) to identify (cluster) the different mixture-manifolds present in the data and (ii) to eliminate the non-linearities present the data by mapping each mixture-manifold into some low-dimensional euclidean space (embedding). Manifold clustering and embedding techniques appear to be an ideal tool for this task, but the present state-of-the-art algorithms perform poorly for hyperspectral data, particularly in the embedding task. We propose a novel reconstruction-based algorithm for improved clustering and embedding of mixture-manifolds. The algorithms attempts to reconstruct each target-point as an affine combination of its nearest neighbors with an additional rank penalty on the neighborhood to ensure that only neighbors on the same manifold as the target-point are used in the reconstruction. The reconstruction matrix generated by using this technique is block-diagonal and can be used for clustering (using spectral clustering) and embedding. The improved performance of the algorithms vis-a-vis its competitors is exhibited on a variety of simulated and real mixture datasets.
Semi-Supervised Endmember Identification In Nonlinear Spectral Mixtures Via Semantic Representation
Jan 03, 2017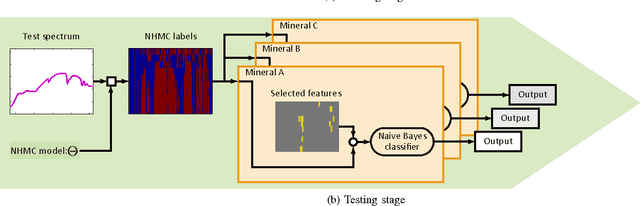
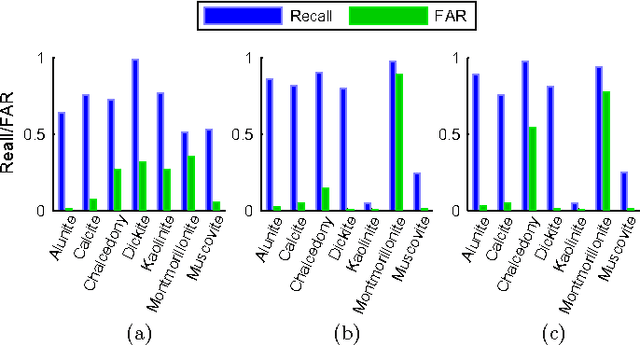
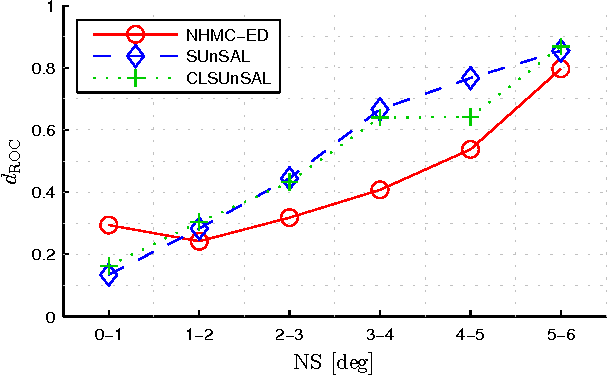
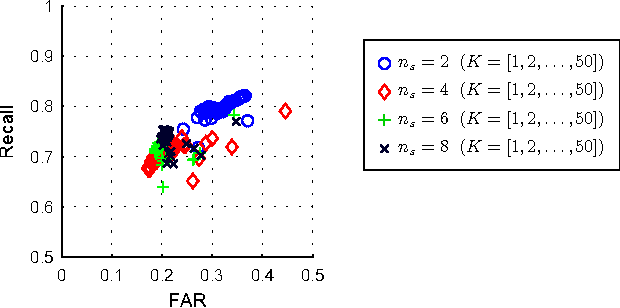
This paper proposes a new hyperspectral unmixing method for nonlinearly mixed hyperspectral data using a semantic representation in a semi-supervised fashion, assuming the availability of a spectral reference library. Existing semi-supervised unmixing algorithms select members from an endmember library that are present at each of the pixels; most such methods assume a linear mixing model. However, those methods will fail in the presence of nonlinear mixing among the observed spectra. To address this issue, we develop an endmember selection method using a recently proposed semantic spectral representation obtained via non-homogeneous hidden Markov chain (NHMC) model for a wavelet transform of the spectra. The semantic representation can encode spectrally discriminative features for any observed spectrum and, therefore, our proposed method can perform endmember selection without any assumption on the mixing model. Experimental results show that in the presence of sufficiently nonlinear mixing our proposed method outperforms dictionary-based sparse unmixing approaches based on linear models.
Perfect Recovery Conditions For Non-Negative Sparse Modeling
Sep 20, 2016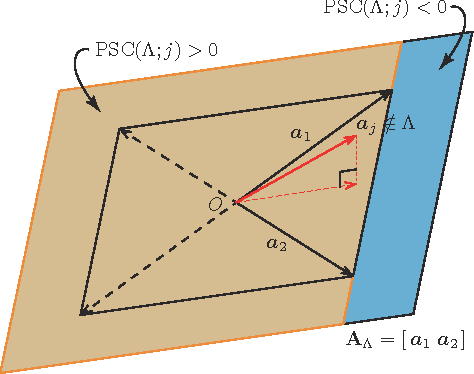
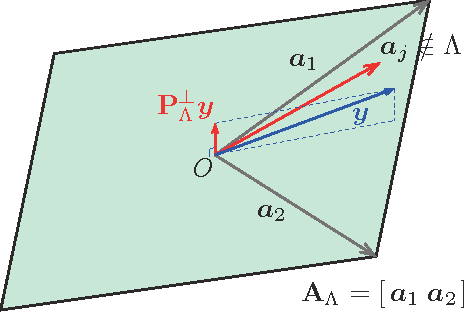

Sparse modeling has been widely and successfully used in many applications such as computer vision, machine learning, and pattern recognition. Accompanied with those applications, significant research has studied the theoretical limits and algorithm design for convex relaxations in sparse modeling. However, theoretical analyses on non-negative versions of sparse modeling are limited in the literature either to a noiseless setting or a scenario with a specific statistical noise model such as Gaussian noise. This paper studies the performance of non-negative sparse modeling in a more general scenario where the observed signals have an unknown arbitrary distortion, especially focusing on non-negativity constrained and L1-penalized least squares, and gives an exact bound for which this problem can recover the correct signal elements. We pose two conditions to guarantee the correct signal recovery: minimum coefficient condition (MCC) and nonlinearity vs. subset coherence condition (NSCC). The former defines the minimum weight for each of the correct atoms present in the signal and the latter defines the tolerable deviation from the linear model relative to the positive subset coherence (PSC), a novel type of "coherence" metric. We provide rigorous performance guarantees based on these conditions and experimentally verify their precise predictive power in a hyperspectral data unmixing application.
Wavelet-Based Semantic Features for Hyperspectral Signature Discrimination
Apr 08, 2016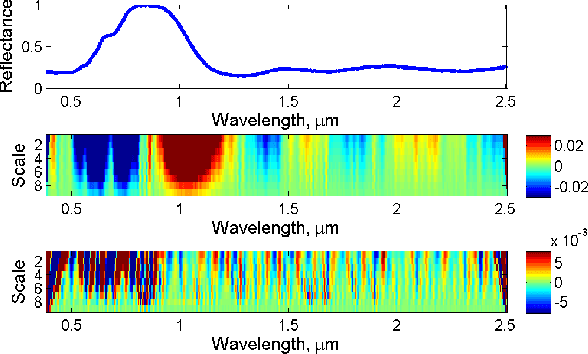
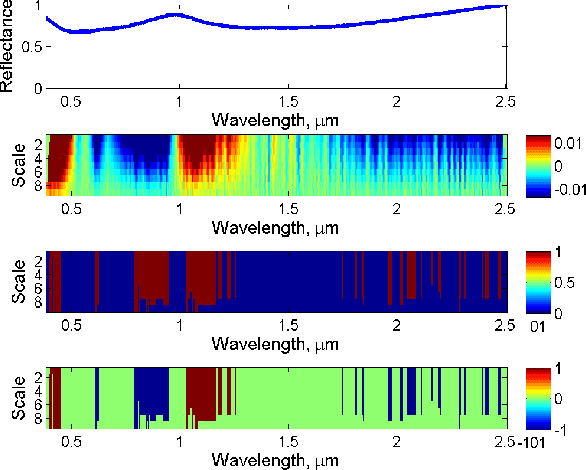
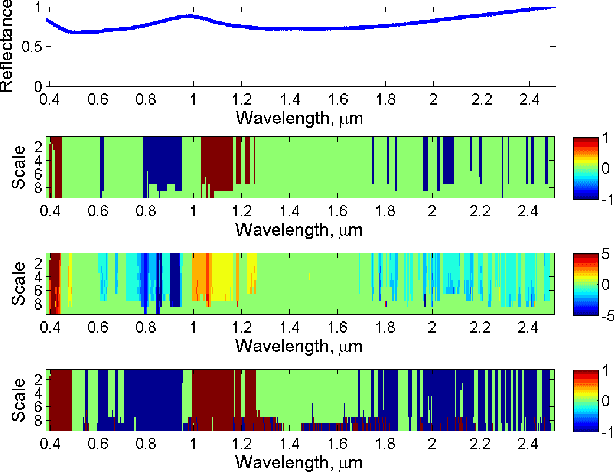
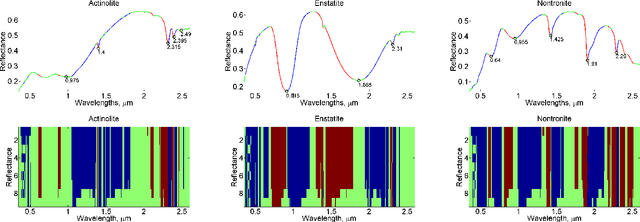
Hyperspectral signature classification is a quantitative analysis approach for hyperspectral imagery which performs detection and classification of the constituent materials at the pixel level in the scene. The classification procedure can be operated directly on hyperspectral data or performed by using some features extracted from the corresponding hyperspectral signatures containing information like the signature's energy or shape. In this paper, we describe a technique that applies non-homogeneous hidden Markov chain (NHMC) models to hyperspectral signature classification. The basic idea is to use statistical models (such as NHMC) to characterize wavelet coefficients which capture the spectrum semantics (i.e., structural information) at multiple levels. Experimental results show that the approach based on NHMC models can outperform existing approaches relevant in classification tasks.
Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches
Apr 24, 2012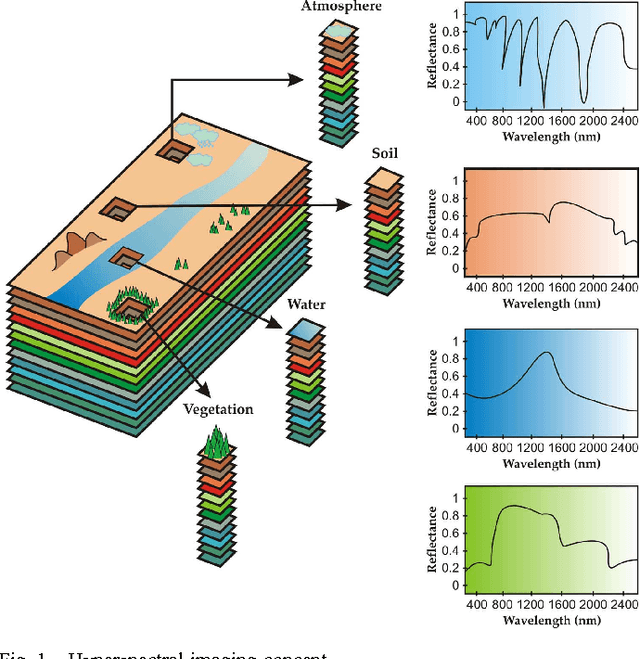
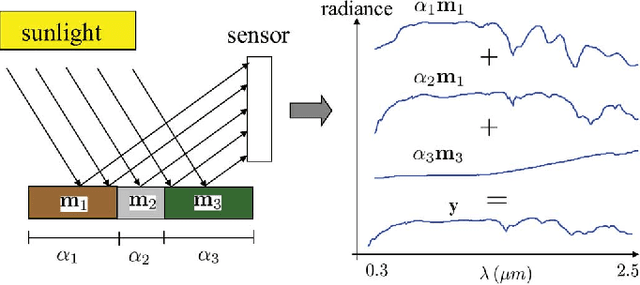
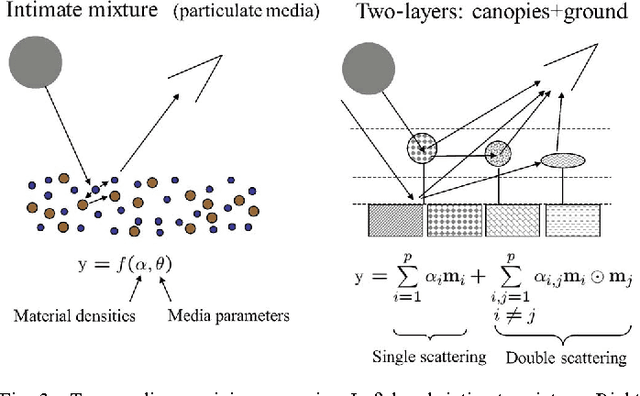
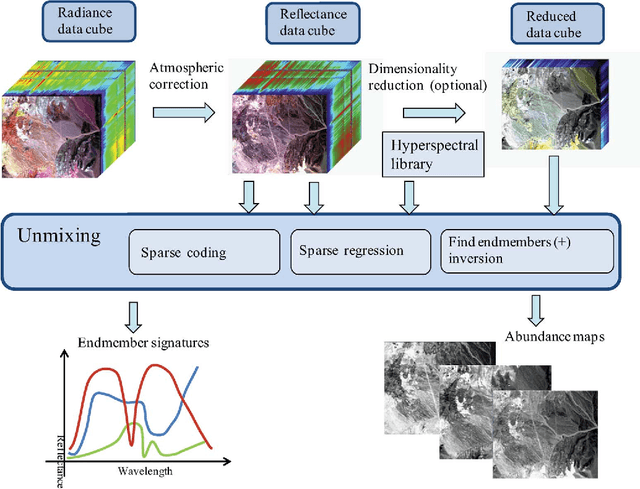
Imaging spectrometers measure electromagnetic energy scattered in their instantaneous field view in hundreds or thousands of spectral channels with higher spectral resolution than multispectral cameras. Imaging spectrometers are therefore often referred to as hyperspectral cameras (HSCs). Higher spectral resolution enables material identification via spectroscopic analysis, which facilitates countless applications that require identifying materials in scenarios unsuitable for classical spectroscopic analysis. Due to low spatial resolution of HSCs, microscopic material mixing, and multiple scattering, spectra measured by HSCs are mixtures of spectra of materials in a scene. Thus, accurate estimation requires unmixing. Pixels are assumed to be mixtures of a few materials, called endmembers. Unmixing involves estimating all or some of: the number of endmembers, their spectral signatures, and their abundances at each pixel. Unmixing is a challenging, ill-posed inverse problem because of model inaccuracies, observation noise, environmental conditions, endmember variability, and data set size. Researchers have devised and investigated many models searching for robust, stable, tractable, and accurate unmixing algorithms. This paper presents an overview of unmixing methods from the time of Keshava and Mustard's unmixing tutorial [1] to the present. Mixing models are first discussed. Signal-subspace, geometrical, statistical, sparsity-based, and spatial-contextual unmixing algorithms are described. Mathematical problems and potential solutions are described. Algorithm characteristics are illustrated experimentally.