 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadial-VCReg: More Informative Representation Learning Through Radial Gaussianization
Feb 15, 2026Self-supervised learning aims to learn maximally informative representations, but explicit information maximization is hindered by the curse of dimensionality. Existing methods like VCReg address this by regularizing first and second-order feature statistics, which cannot fully achieve maximum entropy. We propose Radial-VCReg, which augments VCReg with a radial Gaussianization loss that aligns feature norms with the Chi distribution-a defining property of high-dimensional Gaussians. We prove that Radial-VCReg transforms a broader class of distributions towards normality compared to VCReg and show on synthetic and real-world datasets that it consistently improves performance by reducing higher-order dependencies and promoting more diverse and informative representations.
A Survey on Data Curation for Visual Contrastive Learning: Why Crafting Effective Positive and Negative Pairs Matters
Feb 12, 2025Visual contrastive learning aims to learn representations by contrasting similar (positive) and dissimilar (negative) pairs of data samples. The design of these pairs significantly impacts representation quality, training efficiency, and computational cost. A well-curated set of pairs leads to stronger representations and faster convergence. As contrastive pre-training sees wider adoption for solving downstream tasks, data curation becomes essential for optimizing its effectiveness. In this survey, we attempt to create a taxonomy of existing techniques for positive and negative pair curation in contrastive learning, and describe them in detail.
Improving Pre-Trained Self-Supervised Embeddings Through Effective Entropy Maximization
Nov 24, 2024



A number of different architectures and loss functions have been applied to the problem of self-supervised learning (SSL), with the goal of developing embeddings that provide the best possible pre-training for as-yet-unknown, lightly supervised downstream tasks. One of these SSL criteria is to maximize the entropy of a set of embeddings in some compact space. But the goal of maximizing the embedding entropy often depends--whether explicitly or implicitly--upon high dimensional entropy estimates, which typically perform poorly in more than a few dimensions. In this paper, we motivate an effective entropy maximization criterion (E2MC), defined in terms of easy-to-estimate, low-dimensional constraints. We demonstrate that using it to continue training an already-trained SSL model for only a handful of epochs leads to a consistent and, in some cases, significant improvement in downstream performance. We perform careful ablation studies to show that the improved performance is due to the proposed add-on criterion. We also show that continued pre-training with alternative criteria does not lead to notable improvements, and in some cases, even degrades performance.
Self-Supervised Learning to Guide Scientifically Relevant Categorization of Martian Terrain Images
Apr 21, 2022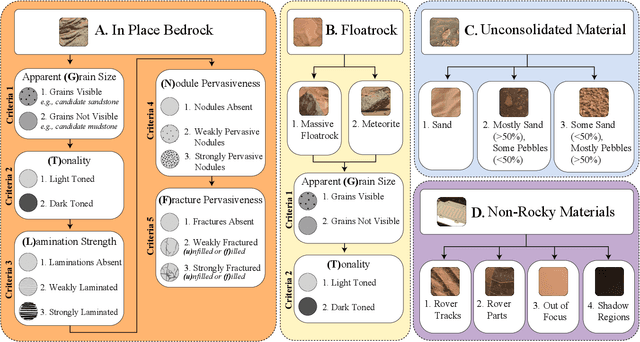

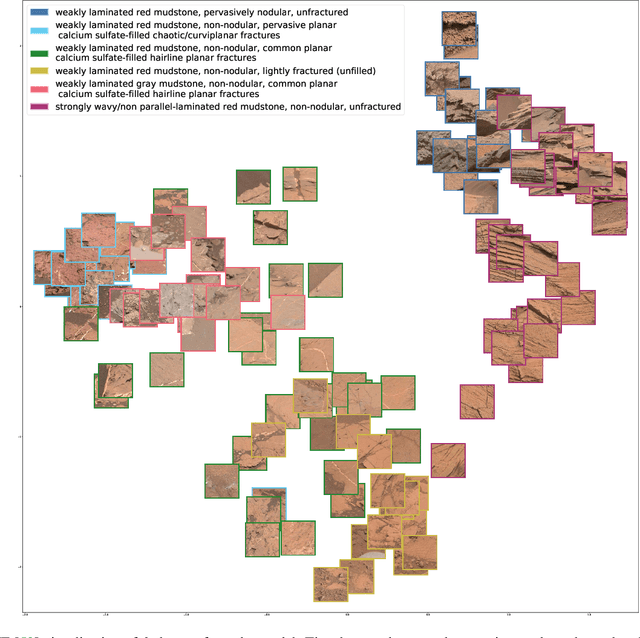

Automatic terrain recognition in Mars rover images is an important problem not just for navigation, but for scientists interested in studying rock types, and by extension, conditions of the ancient Martian paleoclimate and habitability. Existing approaches to label Martian terrain either involve the use of non-expert annotators producing taxonomies of limited granularity (e.g. soil, sand, bedrock, float rock, etc.), or rely on generic class discovery approaches that tend to produce perceptual classes such as rover parts and landscape, which are irrelevant to geologic analysis. Expert-labeled datasets containing granular geological/geomorphological terrain categories are rare or inaccessible to public, and sometimes require the extraction of relevant categorical information from complex annotations. In order to facilitate the creation of a dataset with detailed terrain categories, we present a self-supervised method that can cluster sedimentary textures in images captured from the Mast camera onboard the Curiosity rover (Mars Science Laboratory). We then present a qualitative analysis of these clusters and describe their geologic significance via the creation of a set of granular terrain categories. The precision and geologic validation of these automatically discovered clusters suggest that our methods are promising for the rapid classification of important geologic features and will therefore facilitate our long-term goal of producing a large, granular, and publicly available dataset for Mars terrain recognition.
Pedestrian Detection in Thermal Images using Saliency Maps
Apr 15, 2019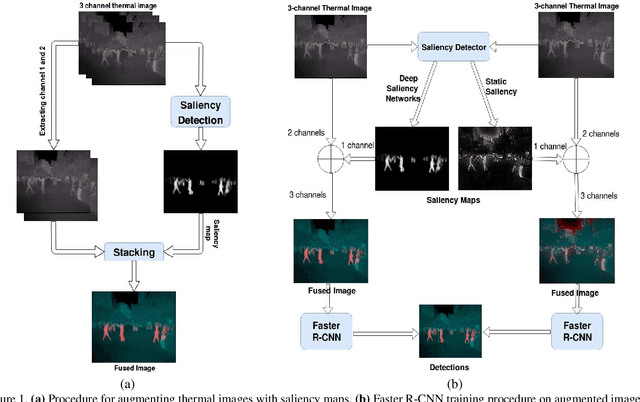
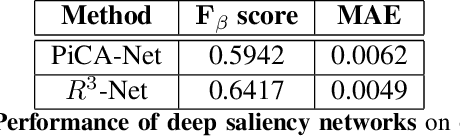


Thermal images are mainly used to detect the presence of people at night or in bad lighting conditions, but perform poorly at daytime. To solve this problem, most state-of-the-art techniques employ a fusion network that uses features from paired thermal and color images. Instead, we propose to augment thermal images with their saliency maps, to serve as an attention mechanism for the pedestrian detector especially during daytime. We investigate how such an approach results in improved performance for pedestrian detection using only thermal images, eliminating the need for paired color images. For our experiments, we train the Faster R-CNN for pedestrian detection and report the added effect of saliency maps generated using static and deep methods (PiCA-Net and R3-Net). Our best performing model results in an absolute reduction of miss rate by 13.4% and 19.4% over the baseline in day and night images respectively. We also annotate and release pixel level masks of pedestrians on a subset of the KAIST Multispectral Pedestrian Detection dataset, which is a first publicly available dataset for salient pedestrian detection.
Nonparallel Emotional Speech Conversion
Nov 03, 2018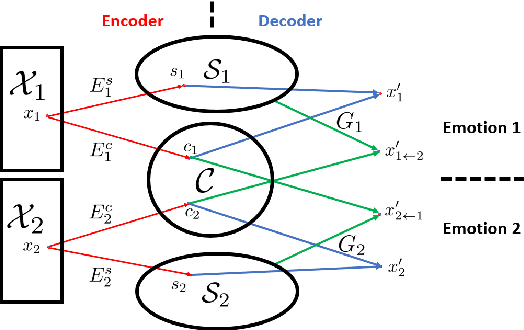
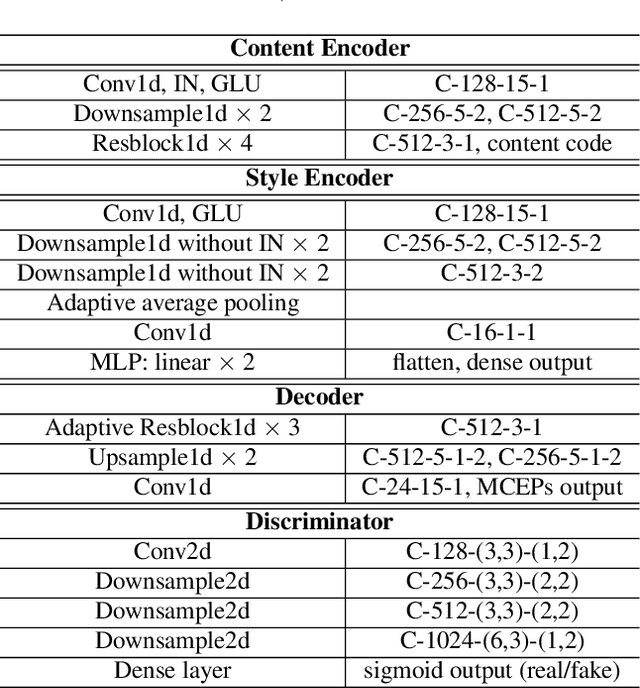
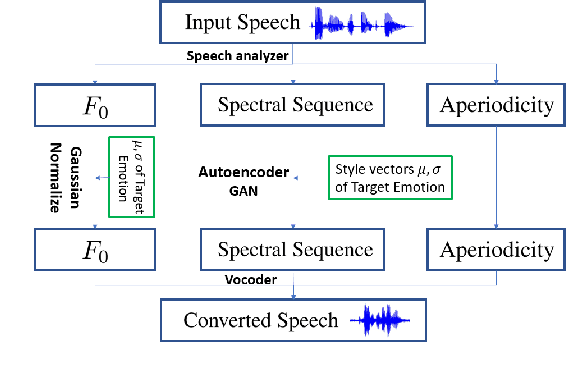
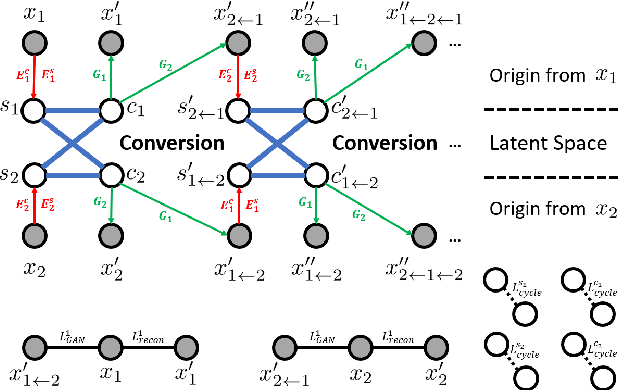
We propose a nonparallel data-driven emotional speech conversion method. It enables the transfer of emotion-related characteristics of a speech signal while preserving the speaker's identity and linguistic content. Most existing approaches require parallel data and time alignment, which is not available in most real applications. We achieve nonparallel training based on an unsupervised style transfer technique, which learns a translation model between two distributions instead of a deterministic one-to-one mapping between paired examples. The conversion model consists of an encoder and a decoder for each emotion domain. We assume that the speech signal can be decomposed into an emotion-invariant content code and an emotion-related style code in latent space. Emotion conversion is performed by extracting and recombining the content code of the source speech and the style code of the target emotion. We tested our method on a nonparallel corpora with four emotions. Both subjective and objective evaluations show the effectiveness of our approach.
Unsupervised Hard Example Mining from Videos for Improved Object Detection
Aug 13, 2018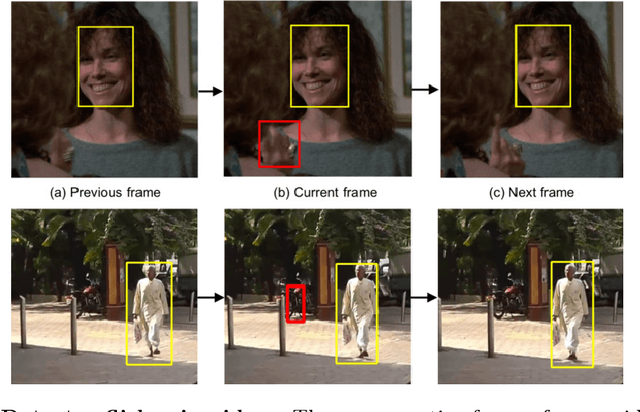


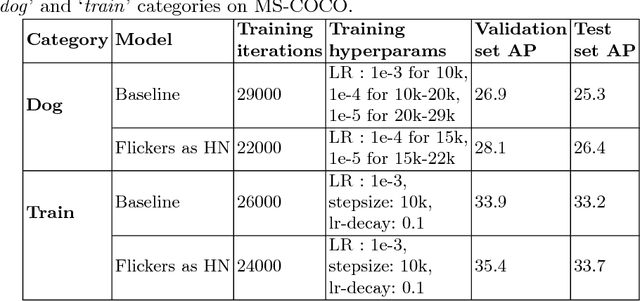
Important gains have recently been obtained in object detection by using training objectives that focus on {\em hard negative} examples, i.e., negative examples that are currently rated as positive or ambiguous by the detector. These examples can strongly influence parameters when the network is trained to correct them. Unfortunately, they are often sparse in the training data, and are expensive to obtain. In this work, we show how large numbers of hard negatives can be obtained {\em automatically} by analyzing the output of a trained detector on video sequences. In particular, detections that are {\em isolated in time}, i.e., that have no associated preceding or following detections, are likely to be hard negatives. We describe simple procedures for mining large numbers of such hard negatives (and also hard {\em positives}) from unlabeled video data. Our experiments show that retraining detectors on these automatically obtained examples often significantly improves performance. We present experiments on multiple architectures and multiple data sets, including face detection, pedestrian detection and other object categories.