 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeiTFake: Deepfake Detection Model using DeiT Multi-Stage Training
Nov 15, 2025
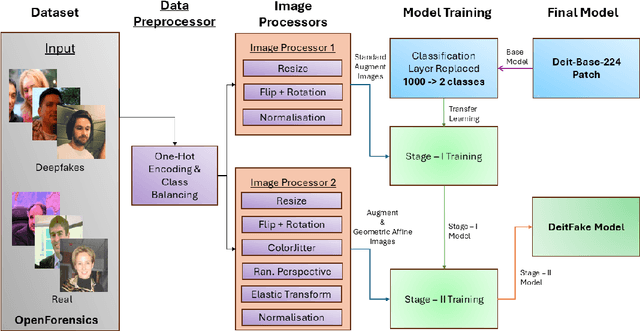


Deepfakes are major threats to the integrity of digital media. We propose DeiTFake, a DeiT-based transformer and a novel two-stage progressive training strategy with increasing augmentation complexity. The approach applies an initial transfer-learning phase with standard augmentations followed by a fine-tuning phase using advanced affine and deepfake-specific augmentations. DeiT's knowledge distillation model captures subtle manipulation artifacts, increasing robustness of the detection model. Trained on the OpenForensics dataset (190,335 images), DeiTFake achieves 98.71\% accuracy after stage one and 99.22\% accuracy with an AUROC of 0.9997, after stage two, outperforming the latest OpenForensics baselines. We analyze augmentation impact and training schedules, and provide practical benchmarks for facial deepfake detection.
Improving Open-World Object Localization by Discovering Background
Apr 24, 2025



Our work addresses the problem of learning to localize objects in an open-world setting, i.e., given the bounding box information of a limited number of object classes during training, the goal is to localize all objects, belonging to both the training and unseen classes in an image, during inference. Towards this end, recent work in this area has focused on improving the characterization of objects either explicitly by proposing new objective functions (localization quality) or implicitly using object-centric auxiliary-information, such as depth information, pixel/region affinity map etc. In this work, we address this problem by incorporating background information to guide the learning of the notion of objectness. Specifically, we propose a novel framework to discover background regions in an image and train an object proposal network to not detect any objects in these regions. We formulate the background discovery task as that of identifying image regions that are not discriminative, i.e., those that are redundant and constitute low information content. We conduct experiments on standard benchmarks to showcase the effectiveness of our proposed approach and observe significant improvements over the previous state-of-the-art approaches for this task.
Hierarchical Re-ranker Retriever (HRR)
Mar 04, 2025


Retrieving the right level of context for a given query is a perennial challenge in information retrieval - too large a chunk dilutes semantic specificity, while chunks that are too small lack broader context. This paper introduces the Hierarchical Re-ranker Retriever (HRR), a framework designed to achieve both fine-grained and high-level context retrieval for large language model (LLM) applications. In HRR, documents are split into sentence-level and intermediate-level (512 tokens) chunks to maximize vector-search quality for both short and broad queries. We then employ a reranker that operates on these 512-token chunks, ensuring an optimal balance neither too coarse nor too fine for robust relevance scoring. Finally, top-ranked intermediate chunks are mapped to parent chunks (2048 tokens) to provide an LLM with sufficiently large context.
A Survey of Small Language Models
Oct 25, 2024


Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others. In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques. We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed. Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.
KODA: A Data-Driven Recursive Model for Time Series Forecasting and Data Assimilation using Koopman Operators
Sep 29, 2024



Approaches based on Koopman operators have shown great promise in forecasting time series data generated by complex nonlinear dynamical systems (NLDS). Although such approaches are able to capture the latent state representation of a NLDS, they still face difficulty in long term forecasting when applied to real world data. Specifically many real-world NLDS exhibit time-varying behavior, leading to nonstationarity that is hard to capture with such models. Furthermore they lack a systematic data-driven approach to perform data assimilation, that is, exploiting noisy measurements on the fly in the forecasting task. To alleviate the above issues, we propose a Koopman operator-based approach (named KODA - Koopman Operator with Data Assimilation) that integrates forecasting and data assimilation in NLDS. In particular we use a Fourier domain filter to disentangle the data into a physical component whose dynamics can be accurately represented by a Koopman operator, and residual dynamics that represents the local or time varying behavior that are captured by a flexible and learnable recursive model. We carefully design an architecture and training criterion that ensures this decomposition lead to stable and long-term forecasts. Moreover, we introduce a course correction strategy to perform data assimilation with new measurements at inference time. The proposed approach is completely data-driven and can be learned end-to-end. Through extensive experimental comparisons we show that KODA outperforms existing state of the art methods on multiple time series benchmarks such as electricity, temperature, weather, lorenz 63 and duffing oscillator demonstrating its superior performance and efficacy along the three tasks a) forecasting, b) data assimilation and c) state prediction.
FigCaps-HF: A Figure-to-Caption Generative Framework and Benchmark with Human Feedback
Jul 20, 2023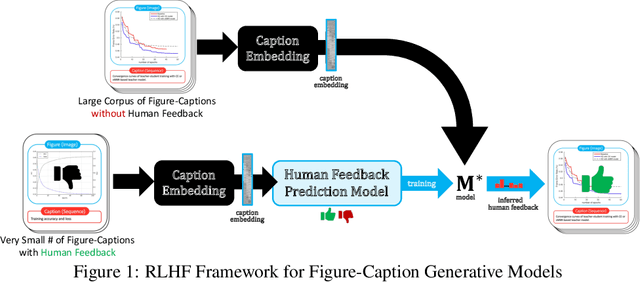
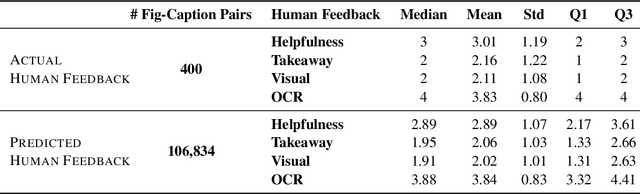
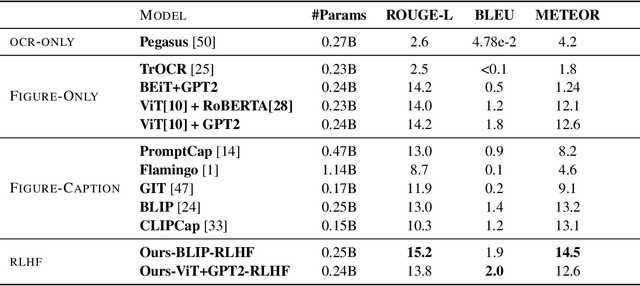
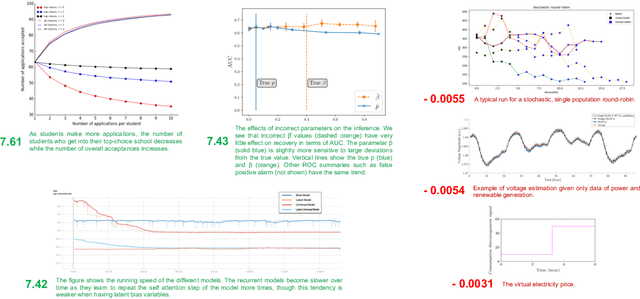
Captions are crucial for understanding scientific visualizations and documents. Existing captioning methods for scientific figures rely on figure-caption pairs extracted from documents for training, many of which fall short with respect to metrics like helpfulness, explainability, and visual-descriptiveness [15] leading to generated captions being misaligned with reader preferences. To enable the generation of high-quality figure captions, we introduce FigCaps-HF a new framework for figure-caption generation that can incorporate domain expert feedback in generating captions optimized for reader preferences. Our framework comprises of 1) an automatic method for evaluating quality of figure-caption pairs, 2) a novel reinforcement learning with human feedback (RLHF) method to optimize a generative figure-to-caption model for reader preferences. We demonstrate the effectiveness of our simple learning framework by improving performance over standard fine-tuning across different types of models. In particular, when using BLIP as the base model, our RLHF framework achieves a mean gain of 35.7%, 16.9%, and 9% in ROUGE, BLEU, and Meteor, respectively. Finally, we release a large-scale benchmark dataset with human feedback on figure-caption pairs to enable further evaluation and development of RLHF techniques for this problem.
An Examination of Wearable Sensors and Video Data Capture for Human Exercise Classification
Jul 10, 2023



Wearable sensors such as Inertial Measurement Units (IMUs) are often used to assess the performance of human exercise. Common approaches use handcrafted features based on domain expertise or automatically extracted features using time series analysis. Multiple sensors are required to achieve high classification accuracy, which is not very practical. These sensors require calibration and synchronization and may lead to discomfort over longer time periods. Recent work utilizing computer vision techniques has shown similar performance using video, without the need for manual feature engineering, and avoiding some pitfalls such as sensor calibration and placement on the body. In this paper, we compare the performance of IMUs to a video-based approach for human exercise classification on two real-world datasets consisting of Military Press and Rowing exercises. We compare the performance using a single camera that captures video in the frontal view versus using 5 IMUs placed on different parts of the body. We observe that an approach based on a single camera can outperform a single IMU by 10 percentage points on average. Additionally, a minimum of 3 IMUs are required to outperform a single camera. We observe that working with the raw data using multivariate time series classifiers outperforms traditional approaches based on handcrafted or automatically extracted features. Finally, we show that an ensemble model combining the data from a single camera with a single IMU outperforms either data modality. Our work opens up new and more realistic avenues for this application, where a video captured using a readily available smartphone camera, combined with a single sensor, can be used for effective human exercise classification.
EVAL: Explainable Video Anomaly Localization
Dec 15, 2022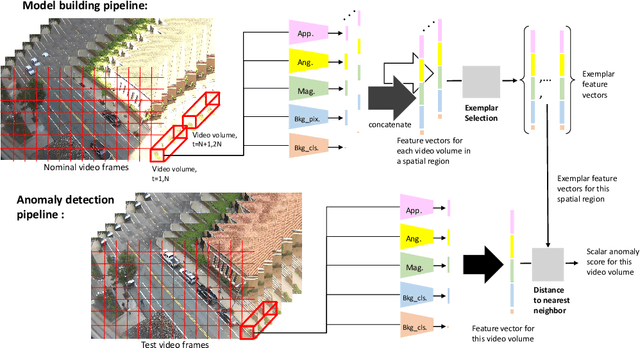



We develop a novel framework for single-scene video anomaly localization that allows for human-understandable reasons for the decisions the system makes. We first learn general representations of objects and their motions (using deep networks) and then use these representations to build a high-level, location-dependent model of any particular scene. This model can be used to detect anomalies in new videos of the same scene. Importantly, our approach is explainable - our high-level appearance and motion features can provide human-understandable reasons for why any part of a video is classified as normal or anomalous. We conduct experiments on standard video anomaly detection datasets (Street Scene, CUHK Avenue, ShanghaiTech and UCSD Ped1, Ped2) and show significant improvements over the previous state-of-the-art.
Inv-SENnet: Invariant Self Expression Network for clustering under biased data
Nov 13, 2022Subspace clustering algorithms are used for understanding the cluster structure that explains the dataset well. These methods are extensively used for data-exploration tasks in various areas of Natural Sciences. However, most of these methods fail to handle unwanted biases in datasets. For datasets where a data sample represents multiple attributes, naively applying any clustering approach can result in undesired output. To this end, we propose a novel framework for jointly removing unwanted attributes (biases) while learning to cluster data points in individual subspaces. Assuming we have information about the bias, we regularize the clustering method by adversarially learning to minimize the mutual information between the data and the unwanted attributes. Our experimental result on synthetic and real-world datasets demonstrate the effectiveness of our approach.
Fast and Robust Video-Based Exercise Classification via Body Pose Tracking and Scalable Multivariate Time Series Classifiers
Oct 02, 2022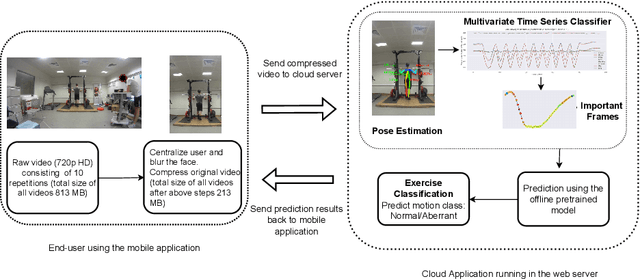


Technological advancements have spurred the usage of machine learning based applications in sports science. Physiotherapists, sports coaches and athletes actively look to incorporate the latest technologies in order to further improve performance and avoid injuries. While wearable sensors are very popular, their use is hindered by constraints on battery power and sensor calibration, especially for use cases which require multiple sensors to be placed on the body. Hence, there is renewed interest in video-based data capture and analysis for sports science. In this paper, we present the application of classifying S\&C exercises using video. We focus on the popular Military Press exercise, where the execution is captured with a video-camera using a mobile device, such as a mobile phone, and the goal is to classify the execution into different types. Since video recordings need a lot of storage and computation, this use case requires data reduction, while preserving the classification accuracy and enabling fast prediction. To this end, we propose an approach named BodyMTS to turn video into time series by employing body pose tracking, followed by training and prediction using multivariate time series classifiers. We analyze the accuracy and robustness of BodyMTS and show that it is robust to different types of noise caused by either video quality or pose estimation factors. We compare BodyMTS to state-of-the-art deep learning methods which classify human activity directly from videos and show that BodyMTS achieves similar accuracy, but with reduced running time and model engineering effort. Finally, we discuss some of the practical aspects of employing BodyMTS in this application in terms of accuracy and robustness under reduced data quality and size. We show that BodyMTS achieves an average accuracy of 87\%, which is significantly higher than the accuracy of human domain experts.