 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQLSpace: A Representation Space for Text-to-SQL to Discover and Mitigate Robustness Gaps
Oct 31, 2025We introduce SQLSpace, a human-interpretable, generalizable, compact representation for text-to-SQL examples derived with minimal human intervention. We demonstrate the utility of these representations in evaluation with three use cases: (i) closely comparing and contrasting the composition of popular text-to-SQL benchmarks to identify unique dimensions of examples they evaluate, (ii) understanding model performance at a granular level beyond overall accuracy scores, and (iii) improving model performance through targeted query rewriting based on learned correctness estimation. We show that SQLSpace enables analysis that would be difficult with raw examples alone: it reveals compositional differences between benchmarks, exposes performance patterns obscured by accuracy alone, and supports modeling of query success.
ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search
Oct 20, 2023



Large language models (LLMs) have demonstrated powerful decision-making and planning capabilities in solving complicated real-world problems. LLM-based autonomous agents can interact with diverse tools (e.g., functional APIs) and generate solution plans that execute a series of API function calls in a step-by-step manner. The multitude of candidate API function calls significantly expands the action space, amplifying the critical need for efficient action space navigation. However, existing methods either struggle with unidirectional exploration in expansive action spaces, trapped into a locally optimal solution, or suffer from exhaustively traversing all potential actions, causing inefficient navigation. To address these issues, we propose ToolChain*, an efficient tree search-based planning algorithm for LLM-based agents. It formulates the entire action space as a decision tree, where each node represents a possible API function call involved in a solution plan. By incorporating the A* search algorithm with task-specific cost function design, it efficiently prunes high-cost branches that may involve incorrect actions, identifying the most low-cost valid path as the solution. Extensive experiments on multiple tool-use and reasoning tasks demonstrate that ToolChain* efficiently balances exploration and exploitation within an expansive action space. It outperforms state-of-the-art baselines on planning and reasoning tasks by 3.1% and 3.5% on average while requiring 7.35x and 2.31x less time, respectively.
FigCaps-HF: A Figure-to-Caption Generative Framework and Benchmark with Human Feedback
Jul 20, 2023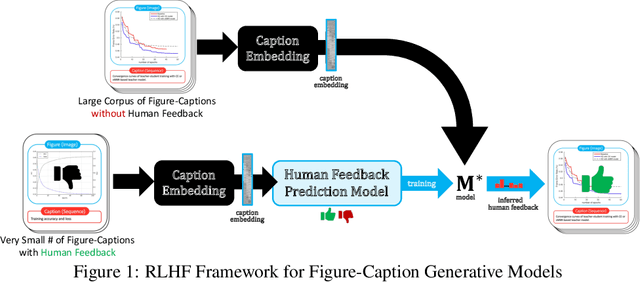
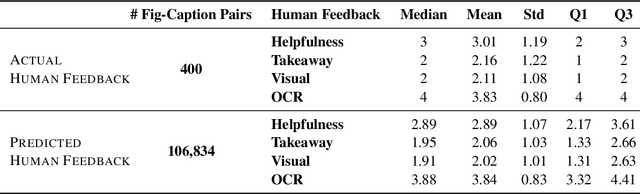
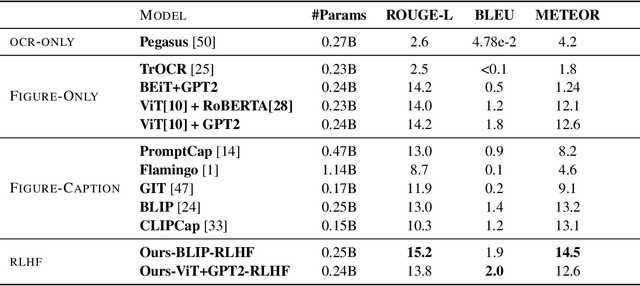
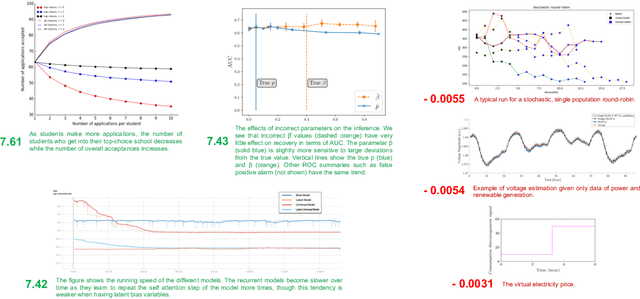
Captions are crucial for understanding scientific visualizations and documents. Existing captioning methods for scientific figures rely on figure-caption pairs extracted from documents for training, many of which fall short with respect to metrics like helpfulness, explainability, and visual-descriptiveness [15] leading to generated captions being misaligned with reader preferences. To enable the generation of high-quality figure captions, we introduce FigCaps-HF a new framework for figure-caption generation that can incorporate domain expert feedback in generating captions optimized for reader preferences. Our framework comprises of 1) an automatic method for evaluating quality of figure-caption pairs, 2) a novel reinforcement learning with human feedback (RLHF) method to optimize a generative figure-to-caption model for reader preferences. We demonstrate the effectiveness of our simple learning framework by improving performance over standard fine-tuning across different types of models. In particular, when using BLIP as the base model, our RLHF framework achieves a mean gain of 35.7%, 16.9%, and 9% in ROUGE, BLEU, and Meteor, respectively. Finally, we release a large-scale benchmark dataset with human feedback on figure-caption pairs to enable further evaluation and development of RLHF techniques for this problem.