 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscoTrace: Representing and Comparing Answering Strategies of Humans and LLMs in Information-Seeking Question Answering
Apr 16, 2026We introduce DiscoTrace, a method to identify the rhetorical strategies that answerers use when responding to information-seeking questions. DiscoTrace represents answers as a sequence of question-related discourse acts paired with interpretations of the original question, annotated on top of rhetorical structure theory parses. Applying DiscoTrace to answers from nine different human communities reveals that communities have diverse preferences for answer construction. In contrast, LLMs do not exhibit rhetorical diversity in their answers, even when prompted to mimic specific human community answering guidelines. LLMs also systematically opt for breadth, addressing interpretations of questions that human answerers choose not to address. Our findings can guide the development of pragmatic LLM answerers that consider a range of strategies informed by context in QA.
SQLSpace: A Representation Space for Text-to-SQL to Discover and Mitigate Robustness Gaps
Oct 31, 2025We introduce SQLSpace, a human-interpretable, generalizable, compact representation for text-to-SQL examples derived with minimal human intervention. We demonstrate the utility of these representations in evaluation with three use cases: (i) closely comparing and contrasting the composition of popular text-to-SQL benchmarks to identify unique dimensions of examples they evaluate, (ii) understanding model performance at a granular level beyond overall accuracy scores, and (iii) improving model performance through targeted query rewriting based on learned correctness estimation. We show that SQLSpace enables analysis that would be difficult with raw examples alone: it reveals compositional differences between benchmarks, exposes performance patterns obscured by accuracy alone, and supports modeling of query success.
Understanding Common Ground Misalignment in Goal-Oriented Dialog: A Case-Study with Ubuntu Chat Logs
Mar 16, 2025



While it is commonly accepted that maintaining common ground plays a role in conversational success, little prior research exists connecting conversational grounding to success in task-oriented conversations. We study failures of grounding in the Ubuntu IRC dataset, where participants use text-only communication to resolve technical issues. We find that disruptions in conversational flow often stem from a misalignment in common ground, driven by a divergence in beliefs and assumptions held by participants. These disruptions, which we call conversational friction, significantly correlate with task success. We find that although LLMs can identify overt cases of conversational friction, they struggle with subtler and more context-dependent instances requiring pragmatic or domain-specific reasoning.
NLI under the Microscope: What Atomic Hypothesis Decomposition Reveals
Feb 12, 2025Decomposition of text into atomic propositions is a flexible framework allowing for the closer inspection of input and output text. We use atomic decomposition of hypotheses in two natural language reasoning tasks, traditional NLI and defeasible NLI, to form atomic sub-problems, or granular inferences that models must weigh when solving the overall problem. These atomic sub-problems serve as a tool to further understand the structure of both NLI and defeasible reasoning, probe a model's consistency and understanding of different inferences, and measure the diversity of examples in benchmark datasets. Our results indicate that LLMs still struggle with logical consistency on atomic NLI and defeasible NLI sub-problems. Lastly, we identify critical atomic sub-problems of defeasible NLI examples, or those that most contribute to the overall label, and propose a method to measure the inferential consistency of a model, a metric designed to capture the degree to which a model makes consistently correct or incorrect predictions about the same fact under different contexts.
How often are errors in natural language reasoning due to paraphrastic variability?
Apr 17, 2024Large language models have been shown to behave inconsistently in response to meaning-preserving paraphrastic inputs. At the same time, researchers evaluate the knowledge and reasoning abilities of these models with test evaluations that do not disaggregate the effect of paraphrastic variability on performance. We propose a metric for evaluating the paraphrastic consistency of natural language reasoning models based on the probability of a model achieving the same correctness on two paraphrases of the same problem. We mathematically connect this metric to the proportion of a model's variance in correctness attributable to paraphrasing. To estimate paraphrastic consistency, we collect ParaNLU, a dataset of 7,782 human-written and validated paraphrased reasoning problems constructed on top of existing benchmark datasets for defeasible and abductive natural language inference. Using ParaNLU, we measure the paraphrastic consistency of several model classes and show that consistency dramatically increases with pretraining but not finetuning. All models tested exhibited room for improvement in paraphrastic consistency.
Towards Pragmatic Awareness in Question Answering: A Case Study in Maternal and Infant Health
Nov 16, 2023



Questions posed by information-seeking users often contain implicit false or potentially harmful assumptions. In a high-risk domain such as maternal and infant health, a question-answering system must recognize these pragmatic constraints and go beyond simply answering user questions, examining them in context to respond helpfully. To achieve this, we study pragmatic inferences made when mothers ask questions about pregnancy and infant care. Some of the inferences in these questions evade detection by existing methods, risking the possibility of QA systems failing to address them which can have dangerous health and policy implications. We explore the viability of detecting inferences from questions using large language models and illustrate that informing existing QA pipelines with pragmatic inferences produces responses that can mitigate the propagation of harmful beliefs.
Partial-input baselines show that NLI models can ignore context, but they don't
May 24, 2022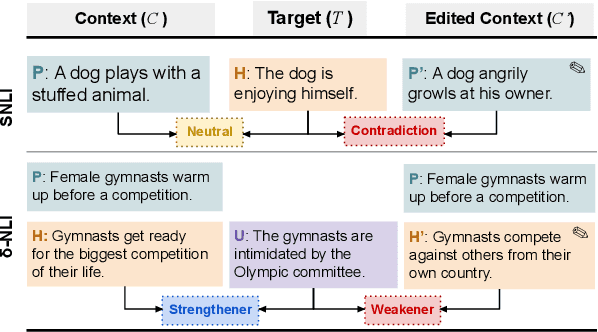
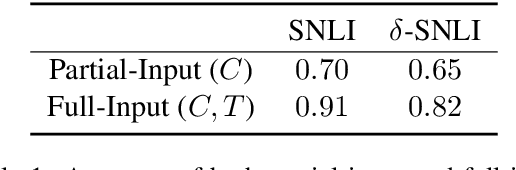
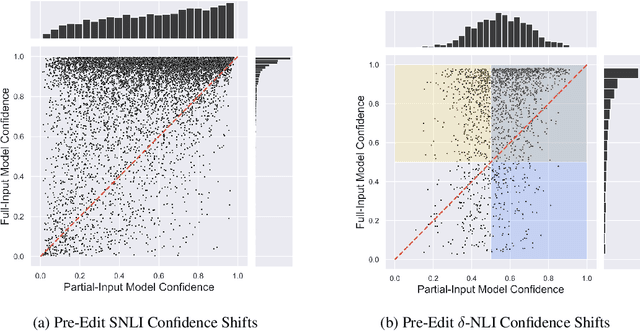
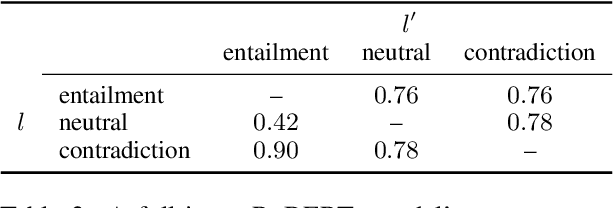
When strong partial-input baselines reveal artifacts in crowdsourced NLI datasets, the performance of full-input models trained on such datasets is often dismissed as reliance on spurious correlations. We investigate whether state-of-the-art NLI models are capable of overriding default inferences made by a partial-input baseline. We introduce an evaluation set of 600 examples consisting of perturbed premises to examine a RoBERTa model's sensitivity to edited contexts. Our results indicate that NLI models are still capable of learning to condition on context--a necessary component of inferential reasoning--despite being trained on artifact-ridden datasets.
Elaborative Simplification: Content Addition and Explanation Generation in Text Simplification
Oct 20, 2020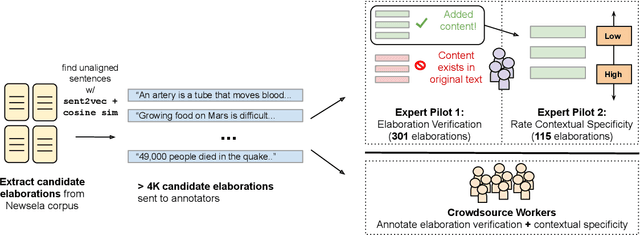
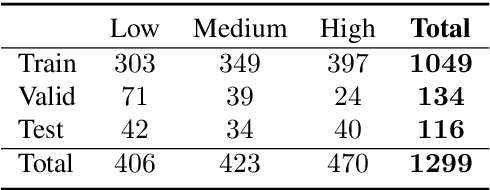
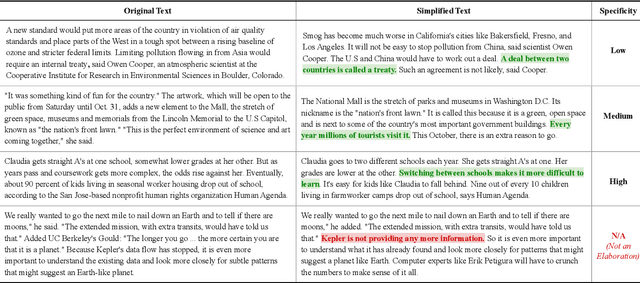
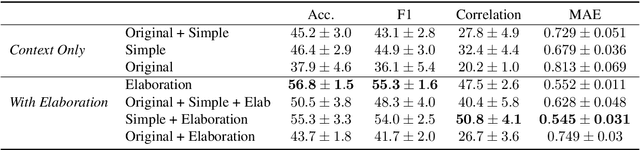
Much of modern day text simplification research focuses on sentence-level simplification, transforming original, more complex sentences to simplified versions. However, adding content can often be useful when difficult concepts and reasoning need to be explained. In this work, we present the first data-driven study of content addition in document simplification, which we call elaborative simplification. We introduce a new annotated dataset of 1.3K instances of elaborative simplification and analyze how entities, ideas, and concepts are elaborated through the lens of contextual specificity. We establish baselines for elaboration generation using large scale pre-trained language models, and illustrate that considering contextual specificity during generation can improve performance. Our results illustrate the complexities of elaborative simplification, suggesting many interesting directions for future work.