 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Open-World Object Localization by Discovering Background
Apr 24, 2025



Our work addresses the problem of learning to localize objects in an open-world setting, i.e., given the bounding box information of a limited number of object classes during training, the goal is to localize all objects, belonging to both the training and unseen classes in an image, during inference. Towards this end, recent work in this area has focused on improving the characterization of objects either explicitly by proposing new objective functions (localization quality) or implicitly using object-centric auxiliary-information, such as depth information, pixel/region affinity map etc. In this work, we address this problem by incorporating background information to guide the learning of the notion of objectness. Specifically, we propose a novel framework to discover background regions in an image and train an object proposal network to not detect any objects in these regions. We formulate the background discovery task as that of identifying image regions that are not discriminative, i.e., those that are redundant and constitute low information content. We conduct experiments on standard benchmarks to showcase the effectiveness of our proposed approach and observe significant improvements over the previous state-of-the-art approaches for this task.
Improving Pre-Trained Self-Supervised Embeddings Through Effective Entropy Maximization
Nov 24, 2024



A number of different architectures and loss functions have been applied to the problem of self-supervised learning (SSL), with the goal of developing embeddings that provide the best possible pre-training for as-yet-unknown, lightly supervised downstream tasks. One of these SSL criteria is to maximize the entropy of a set of embeddings in some compact space. But the goal of maximizing the embedding entropy often depends--whether explicitly or implicitly--upon high dimensional entropy estimates, which typically perform poorly in more than a few dimensions. In this paper, we motivate an effective entropy maximization criterion (E2MC), defined in terms of easy-to-estimate, low-dimensional constraints. We demonstrate that using it to continue training an already-trained SSL model for only a handful of epochs leads to a consistent and, in some cases, significant improvement in downstream performance. We perform careful ablation studies to show that the improved performance is due to the proposed add-on criterion. We also show that continued pre-training with alternative criteria does not lead to notable improvements, and in some cases, even degrades performance.
Log-Concavity of Multinomial Likelihood Functions Under Interval Censoring Constraints on Frequencies or Their Partial Sums
Nov 05, 2023We show that the likelihood function for a multinomial vector observed under arbitrary interval censoring constraints on the frequencies or their partial sums is completely log-concave by proving that the constrained sample spaces comprise M-convex subsets of the discrete simplex.
Machine Learning for Automated Mitral Regurgitation Detection from Cardiac Imaging
Oct 07, 2023Mitral regurgitation (MR) is a heart valve disease with potentially fatal consequences that can only be forestalled through timely diagnosis and treatment. Traditional diagnosis methods are expensive, labor-intensive and require clinical expertise, posing a barrier to screening for MR. To overcome this impediment, we propose a new semi-supervised model for MR classification called CUSSP. CUSSP operates on cardiac imaging slices of the 4-chamber view of the heart. It uses standard computer vision techniques and contrastive models to learn from large amounts of unlabeled data, in conjunction with specialized classifiers to establish the first ever automated MR classification system. Evaluated on a test set of 179 labeled -- 154 non-MR and 25 MR -- sequences, CUSSP attains an F1 score of 0.69 and a ROC-AUC score of 0.88, setting the first benchmark result for this new task.
* 12 pages including references and the appendix. 9 Figures, 2 tables. Accepted at MICCAI (Machine Learning for Automated Mitral Regurgitation Detection from Cardiac Imaging) 2023, Link to Springer at https://link.springer.com/chapter/10.1007/978-3-031-43990-2_23
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
Sep 15, 2023



We present an approach to estimating camera rotation in crowded, real-world scenes from handheld monocular video. While camera rotation estimation is a well-studied problem, no previous methods exhibit both high accuracy and acceptable speed in this setting. Because the setting is not addressed well by other datasets, we provide a new dataset and benchmark, with high-accuracy, rigorously verified ground truth, on 17 video sequences. Methods developed for wide baseline stereo (e.g., 5-point methods) perform poorly on monocular video. On the other hand, methods used in autonomous driving (e.g., SLAM) leverage specific sensor setups, specific motion models, or local optimization strategies (lagging batch processing) and do not generalize well to handheld video. Finally, for dynamic scenes, commonly used robustification techniques like RANSAC require large numbers of iterations, and become prohibitively slow. We introduce a novel generalization of the Hough transform on SO(3) to efficiently and robustly find the camera rotation most compatible with optical flow. Among comparably fast methods, ours reduces error by almost 50\% over the next best, and is more accurate than any method, irrespective of speed. This represents a strong new performance point for crowded scenes, an important setting for computer vision. The code and the dataset are available at https://fabiendelattre.com/robust-rotation-estimation.
An Efficient General-Purpose Modular Vision Model via Multi-Task Heterogeneous Training
Jun 29, 2023We present a model that can perform multiple vision tasks and can be adapted to other downstream tasks efficiently. Despite considerable progress in multi-task learning, most efforts focus on learning from multi-label data: a single image set with multiple task labels. Such multi-label data sets are rare, small, and expensive. We say heterogeneous to refer to image sets with different task labels, or to combinations of single-task datasets. Few have explored training on such heterogeneous datasets. General-purpose vision models are still dominated by single-task pretraining, and it remains unclear how to scale up multi-task models by leveraging mainstream vision datasets designed for different purposes. The challenges lie in managing large intrinsic differences among vision tasks, including data distribution, architectures, task-specific modules, dataset scales, and sampling strategies. To address these challenges, we propose to modify and scale up mixture-of-experts (MoE) vision transformers, so that they can simultaneously learn classification, detection, and segmentation on diverse mainstream vision datasets including ImageNet, COCO, and ADE20K. Our approach achieves comparable results to single-task state-of-the-art models and demonstrates strong generalization on downstream tasks. Due to its emergent modularity, this general-purpose model decomposes into high-performing components, efficiently adapting to downstream tasks. We can fine-tune it with fewer training parameters, fewer model parameters, and less computation. Additionally, its modularity allows for easy expansion in continual-learning-without-forgetting scenarios. Finally, these functions can be controlled and combined to meet various demands of downstream tasks.
Event Camera-based Visual Odometry for Dynamic Motion Tracking of a Legged Robot Using Adaptive Time Surface
May 15, 2023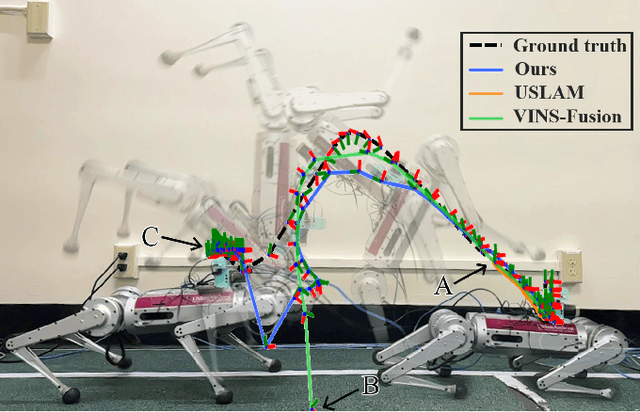
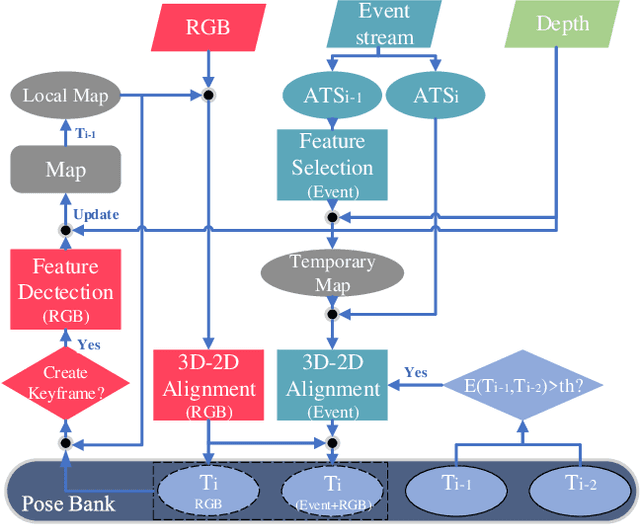
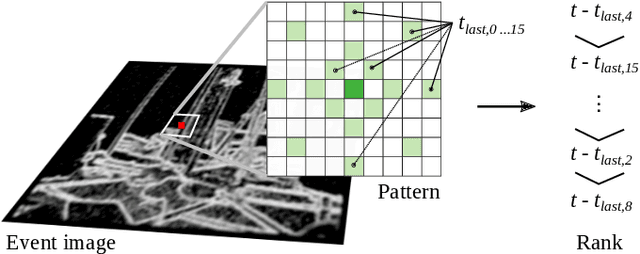

Our paper proposes a direct sparse visual odometry method that combines event and RGB-D data to estimate the pose of agile-legged robots during dynamic locomotion and acrobatic behaviors. Event cameras offer high temporal resolution and dynamic range, which can eliminate the issue of blurred RGB images during fast movements. This unique strength holds a potential for accurate pose estimation of agile-legged robots, which has been a challenging problem to tackle. Our framework leverages the benefits of both RGB-D and event cameras to achieve robust and accurate pose estimation, even during dynamic maneuvers such as jumping and landing a quadruped robot, the Mini-Cheetah. Our major contributions are threefold: Firstly, we introduce an adaptive time surface (ATS) method that addresses the whiteout and blackout issue in conventional time surfaces by formulating pixel-wise decay rates based on scene complexity and motion speed. Secondly, we develop an effective pixel selection method that directly samples from event data and applies sample filtering through ATS, enabling us to pick pixels on distinct features. Lastly, we propose a nonlinear pose optimization formula that simultaneously performs 3D-2D alignment on both RGB-based and event-based maps and images, allowing the algorithm to fully exploit the benefits of both data streams. We extensively evaluate the performance of our framework on both public datasets and our own quadruped robot dataset, demonstrating its effectiveness in accurately estimating the pose of agile robots during dynamic movements.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023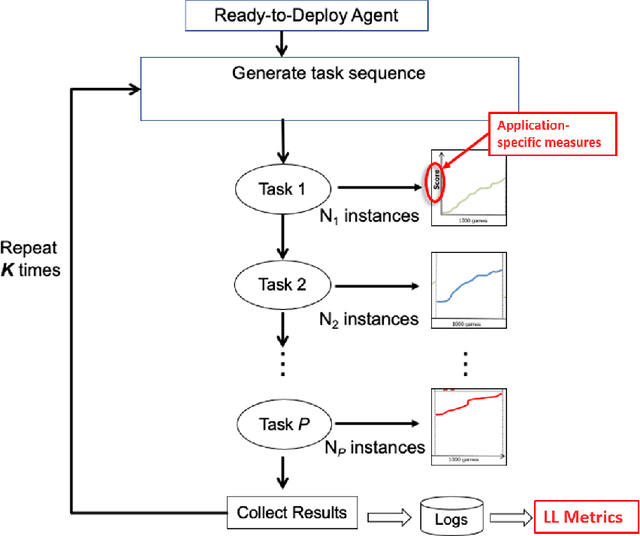
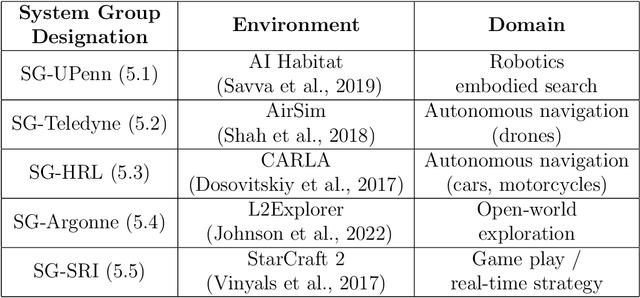


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
EVAL: Explainable Video Anomaly Localization
Dec 15, 2022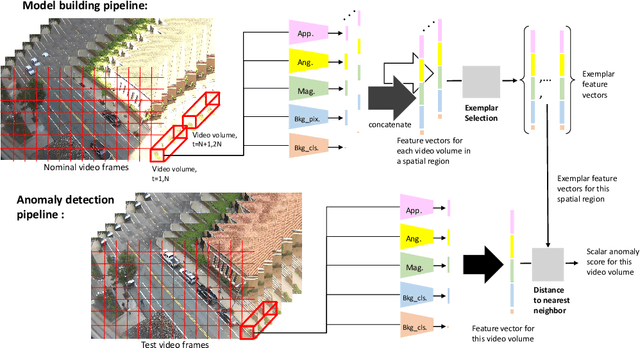



We develop a novel framework for single-scene video anomaly localization that allows for human-understandable reasons for the decisions the system makes. We first learn general representations of objects and their motions (using deep networks) and then use these representations to build a high-level, location-dependent model of any particular scene. This model can be used to detect anomalies in new videos of the same scene. Importantly, our approach is explainable - our high-level appearance and motion features can provide human-understandable reasons for why any part of a video is classified as normal or anomalous. We conduct experiments on standard video anomaly detection datasets (Street Scene, CUHK Avenue, ShanghaiTech and UCSD Ped1, Ped2) and show significant improvements over the previous state-of-the-art.
Mod-Squad: Designing Mixture of Experts As Modular Multi-Task Learners
Dec 15, 2022Optimization in multi-task learning (MTL) is more challenging than single-task learning (STL), as the gradient from different tasks can be contradictory. When tasks are related, it can be beneficial to share some parameters among them (cooperation). However, some tasks require additional parameters with expertise in a specific type of data or discrimination (specialization). To address the MTL challenge, we propose Mod-Squad, a new model that is Modularized into groups of experts (a 'Squad'). This structure allows us to formalize cooperation and specialization as the process of matching experts and tasks. We optimize this matching process during the training of a single model. Specifically, we incorporate mixture of experts (MoE) layers into a transformer model, with a new loss that incorporates the mutual dependence between tasks and experts. As a result, only a small set of experts are activated for each task. This prevents the sharing of the entire backbone model between all tasks, which strengthens the model, especially when the training set size and the number of tasks scale up. More interestingly, for each task, we can extract the small set of experts as a standalone model that maintains the same performance as the large model. Extensive experiments on the Taskonomy dataset with 13 vision tasks and the PASCAL-Context dataset with 5 vision tasks show the superiority of our approach.