 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Visual Question Answering Pipeline for Autonomous Driving via Scene Region Compression
Jan 11, 2026Autonomous driving increasingly relies on Visual Question Answering (VQA) to enable vehicles to understand complex surroundings by analyzing visual inputs and textual queries. Currently, a paramount concern for VQA in this domain is the stringent requirement for fast latency and real-time processing, as delays directly impact real-world safety in this safety-critical application. However, current state-of-the-art VQA models, particularly large vision-language models (VLMs), often prioritize performance over computational efficiency. These models typically process dense patch tokens for every frame, leading to prohibitive computational costs (FLOPs) and significant inference latency, especially with long video sequences. This focus limits their practical deployment in real-time autonomous driving scenarios. To tackle this issue, we propose an efficient VLM framework for autonomous driving VQA tasks, SRC-Pipeline. It learns to compress early frame tokens into a small number of high-level tokens while retaining full patch tokens for recent frames. Experiments on autonomous driving video question answering tasks show that our approach achieves 66% FLOPs reduction while maintaining comparable performance, enabling VLMs to operate more effectively in real-time, safety-critical autonomous driving settings.
An Efficient General-Purpose Modular Vision Model via Multi-Task Heterogeneous Training
Jun 29, 2023We present a model that can perform multiple vision tasks and can be adapted to other downstream tasks efficiently. Despite considerable progress in multi-task learning, most efforts focus on learning from multi-label data: a single image set with multiple task labels. Such multi-label data sets are rare, small, and expensive. We say heterogeneous to refer to image sets with different task labels, or to combinations of single-task datasets. Few have explored training on such heterogeneous datasets. General-purpose vision models are still dominated by single-task pretraining, and it remains unclear how to scale up multi-task models by leveraging mainstream vision datasets designed for different purposes. The challenges lie in managing large intrinsic differences among vision tasks, including data distribution, architectures, task-specific modules, dataset scales, and sampling strategies. To address these challenges, we propose to modify and scale up mixture-of-experts (MoE) vision transformers, so that they can simultaneously learn classification, detection, and segmentation on diverse mainstream vision datasets including ImageNet, COCO, and ADE20K. Our approach achieves comparable results to single-task state-of-the-art models and demonstrates strong generalization on downstream tasks. Due to its emergent modularity, this general-purpose model decomposes into high-performing components, efficiently adapting to downstream tasks. We can fine-tune it with fewer training parameters, fewer model parameters, and less computation. Additionally, its modularity allows for easy expansion in continual-learning-without-forgetting scenarios. Finally, these functions can be controlled and combined to meet various demands of downstream tasks.
Visual Dependency Transformers: Dependency Tree Emerges from Reversed Attention
Apr 06, 2023Humans possess a versatile mechanism for extracting structured representations of our visual world. When looking at an image, we can decompose the scene into entities and their parts as well as obtain the dependencies between them. To mimic such capability, we propose Visual Dependency Transformers (DependencyViT) that can induce visual dependencies without any labels. We achieve that with a novel neural operator called \emph{reversed attention} that can naturally capture long-range visual dependencies between image patches. Specifically, we formulate it as a dependency graph where a child token in reversed attention is trained to attend to its parent tokens and send information following a normalized probability distribution rather than gathering information in conventional self-attention. With such a design, hierarchies naturally emerge from reversed attention layers, and a dependency tree is progressively induced from leaf nodes to the root node unsupervisedly. DependencyViT offers several appealing benefits. (i) Entities and their parts in an image are represented by different subtrees, enabling part partitioning from dependencies; (ii) Dynamic visual pooling is made possible. The leaf nodes which rarely send messages can be pruned without hindering the model performance, based on which we propose the lightweight DependencyViT-Lite to reduce the computational and memory footprints; (iii) DependencyViT works well on both self- and weakly-supervised pretraining paradigms on ImageNet, and demonstrates its effectiveness on 8 datasets and 5 tasks, such as unsupervised part and saliency segmentation, recognition, and detection.
Mod-Squad: Designing Mixture of Experts As Modular Multi-Task Learners
Dec 15, 2022Optimization in multi-task learning (MTL) is more challenging than single-task learning (STL), as the gradient from different tasks can be contradictory. When tasks are related, it can be beneficial to share some parameters among them (cooperation). However, some tasks require additional parameters with expertise in a specific type of data or discrimination (specialization). To address the MTL challenge, we propose Mod-Squad, a new model that is Modularized into groups of experts (a 'Squad'). This structure allows us to formalize cooperation and specialization as the process of matching experts and tasks. We optimize this matching process during the training of a single model. Specifically, we incorporate mixture of experts (MoE) layers into a transformer model, with a new loss that incorporates the mutual dependence between tasks and experts. As a result, only a small set of experts are activated for each task. This prevents the sharing of the entire backbone model between all tasks, which strengthens the model, especially when the training set size and the number of tasks scale up. More interestingly, for each task, we can extract the small set of experts as a standalone model that maintains the same performance as the large model. Extensive experiments on the Taskonomy dataset with 13 vision tasks and the PASCAL-Context dataset with 5 vision tasks show the superiority of our approach.
Is Label Smoothing Truly Incompatible with Knowledge Distillation: An Empirical Study
Apr 01, 2021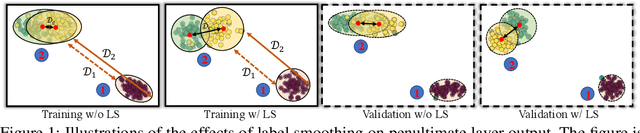


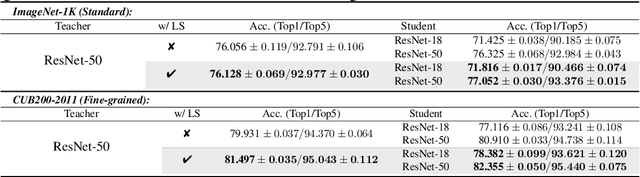
This work aims to empirically clarify a recently discovered perspective that label smoothing is incompatible with knowledge distillation. We begin by introducing the motivation behind on how this incompatibility is raised, i.e., label smoothing erases relative information between teacher logits. We provide a novel connection on how label smoothing affects distributions of semantically similar and dissimilar classes. Then we propose a metric to quantitatively measure the degree of erased information in sample's representation. After that, we study its one-sidedness and imperfection of the incompatibility view through massive analyses, visualizations and comprehensive experiments on Image Classification, Binary Networks, and Neural Machine Translation. Finally, we broadly discuss several circumstances wherein label smoothing will indeed lose its effectiveness. Project page: http://zhiqiangshen.com/projects/LS_and_KD/index.html.
Shot in the Dark: Few-Shot Learning with No Base-Class Labels
Oct 06, 2020
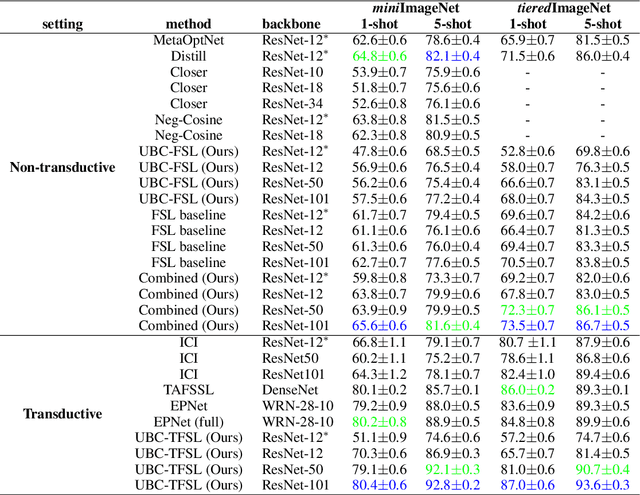
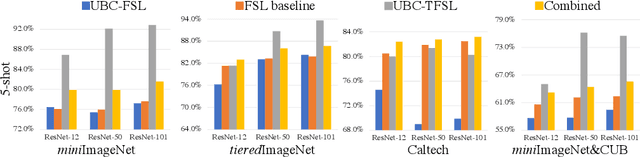

Few-shot learning aims to learn classifiers for new objects from a small number of labeled examples. But it does not do this in a vacuum. Usually, a strong inductive bias is borrowed from the supervised learning of base classes. This inductive bias enables more statistically efficient learning of the new classes. In this work, we show that no labels are needed to develop such an inductive bias, and that self-supervised learning can provide a powerful inductive bias for few-shot learning. This is particularly effective when the unlabeled data for learning such a bias contains not only examples of the base classes, but also examples of the novel classes. The setting in which unlabeled examples of the novel classes are available is known as the transductive setting. Our method outperforms state-of-the-art few-shot learning methods, including other transductive learning methods, by 3.9% for 5-shot accuracy on miniImageNet without using any base class labels. By benchmarking unlabeled-base-class (UBC) few-shot learning and UBC transductive few-shot learning, we demonstrate the great potential of self-supervised feature learning: self-supervision alone is sufficient to create a remarkably good inductive bias for few-shot learning. This motivates a rethinking of whether base-class labels are necessary at all for few-shot learning. We also explore the relationship between self-supervised features and supervised features, comparing both their transferability and their complementarity in the non-transductive setting. By combining supervised and self-supervised features learned from base classes, we also achieve a new state-of-the-art in the non-transductive setting, outperforming all previous methods.
Cross-Supervised Object Detection
Jun 29, 2020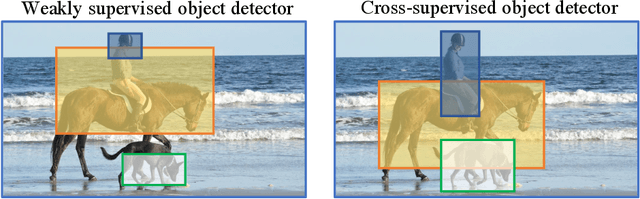
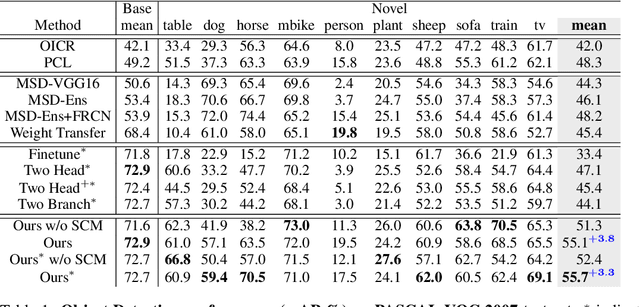
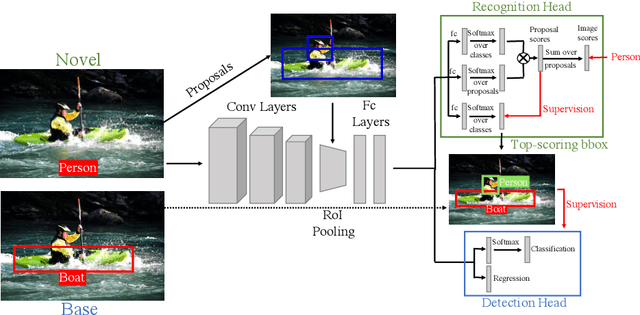
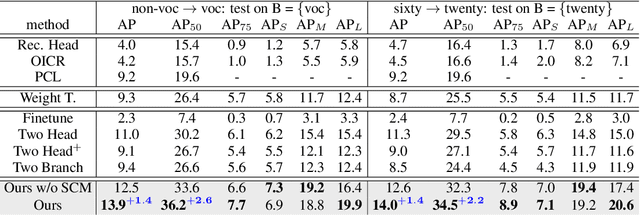
After learning a new object category from image-level annotations (with no object bounding boxes), humans are remarkably good at precisely localizing those objects. However, building good object localizers (i.e., detectors) currently requires expensive instance-level annotations. While some work has been done on learning detectors from weakly labeled samples (with only class labels), these detectors do poorly at localization. In this work, we show how to build better object detectors from weakly labeled images of new categories by leveraging knowledge learned from fully labeled base categories. We call this novel learning paradigm cross-supervised object detection. We propose a unified framework that combines a detection head trained from instance-level annotations and a recognition head learned from image-level annotations, together with a spatial correlation module that bridges the gap between detection and recognition. These contributions enable us to better detect novel objects with image-level annotations in complex multi-object scenes such as the COCO dataset.
Image Deformation Meta-Networks for One-Shot Learning
May 28, 2019

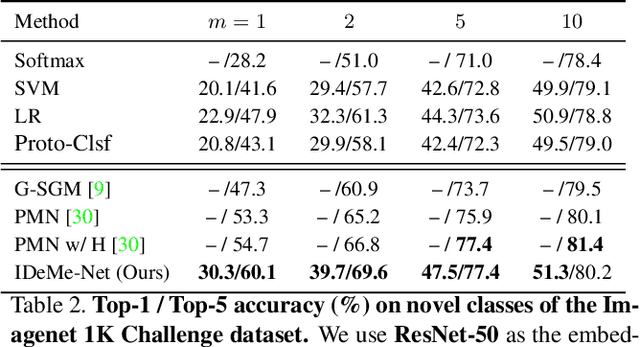

Humans can robustly learn novel visual concepts even when images undergo various deformations and loose certain information. Mimicking the same behavior and synthesizing deformed instances of new concepts may help visual recognition systems perform better one-shot learning, i.e., learning concepts from one or few examples. Our key insight is that, while the deformed images may not be visually realistic, they still maintain critical semantic information and contribute significantly to formulating classifier decision boundaries. Inspired by the recent progress of meta-learning, we combine a meta-learner with an image deformation sub-network that produces additional training examples, and optimize both models in an end-to-end manner. The deformation sub-network learns to deform images by fusing a pair of images -- a probe image that keeps the visual content and a gallery image that diversifies the deformations. We demonstrate results on the widely used one-shot learning benchmarks (miniImageNet and ImageNet 1K Challenge datasets), which significantly outperform state-of-the-art approaches.
Multi-level Semantic Feature Augmentation for One-shot Learning
Oct 02, 2018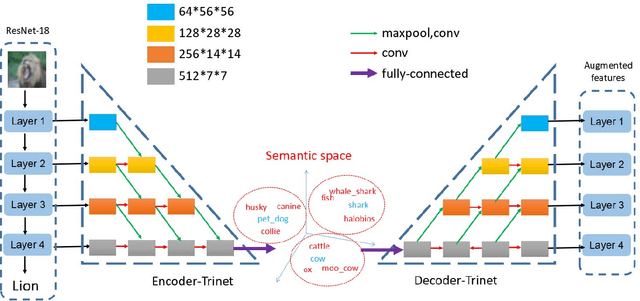
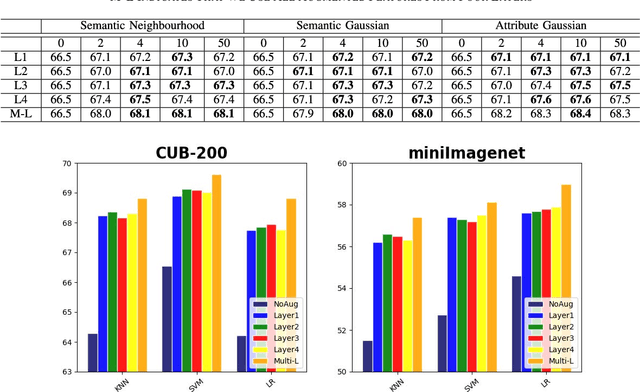

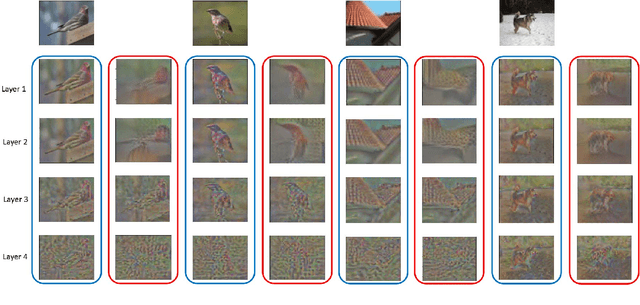
The ability to quickly recognize and learn new visual concepts from limited samples enables humans to swiftly adapt to new environments. This ability is enabled by semantic associations of novel concepts with those that have already been learned and stored in memory. Computers can start to ascertain similar abilities by utilizing a semantic concept space. A concept space is a high-dimensional semantic space in which similar abstract concepts appear close and dissimilar ones far apart. In this paper, we propose a novel approach to one-shot learning that builds on this idea. Our approach learns to map a novel sample instance to a concept, relates that concept to the existing ones in the concept space and generates new instances, by interpolating among the concepts, to help learning. Instead of synthesizing new image instance, we propose to directly synthesize instance features by leveraging semantics using a novel auto-encoder network we call dual TriNet. The encoder part of the TriNet learns to map multi-layer visual features of deep CNNs, that is, multi-level concepts, to a semantic vector. In semantic space, we search for related concepts, which are then projected back into the image feature spaces by the decoder portion of the TriNet. Two strategies in the semantic space are explored. Notably, this seemingly simple strategy results in complex augmented feature distributions in the image feature space, leading to substantially better performance.
Neural Arithmetic Expression Calculator
Sep 23, 2018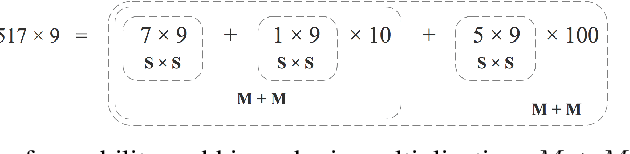

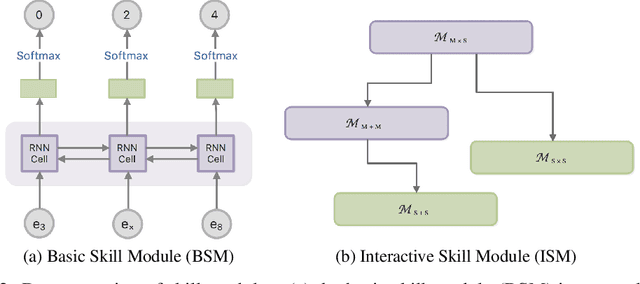
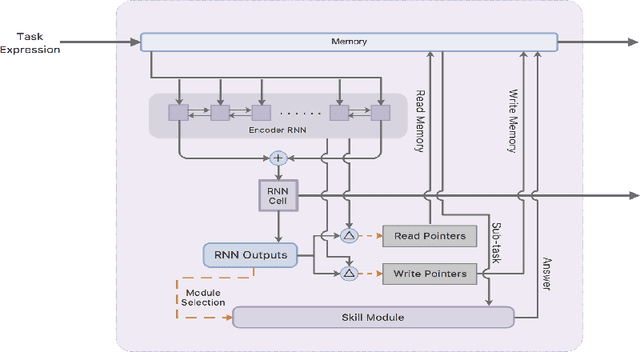
This paper presents a pure neural solver for arithmetic expression calculation (AEC) problem. Previous work utilizes the powerful capabilities of deep neural networks and attempts to build an end-to-end model to solve this problem. However, most of these methods can only deal with the additive operations. It is still a challenging problem to solve the complex expression calculation problem, which includes the adding, subtracting, multiplying, dividing and bracketing operations. In this work, we regard the arithmetic expression calculation as a hierarchical reinforcement learning problem. An arithmetic operation is decomposed into a series of sub-tasks, and each sub-task is dealt with by a skill module. The skill module could be a basic module performing elementary operations, or interactive module performing complex operations by invoking other skill models. With curriculum learning, our model can deal with a complex arithmetic expression calculation with the deep hierarchical structure of skill models. Experiments show that our model significantly outperforms the previous models for arithmetic expression calculation.