 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Semantic Feature Augmentation for One-shot Learning
Paper and Code
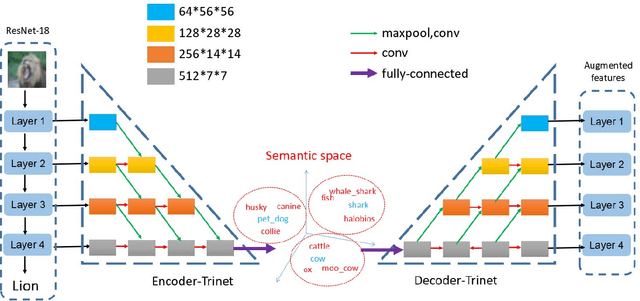
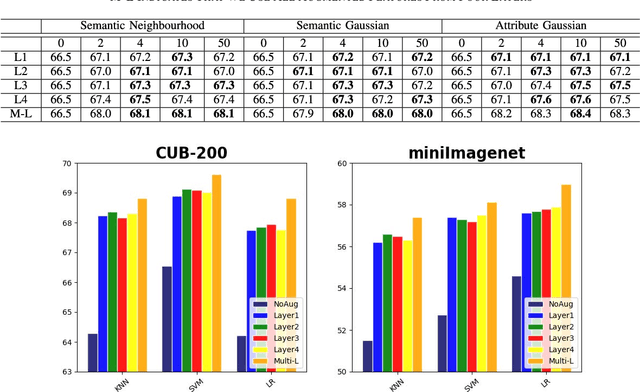

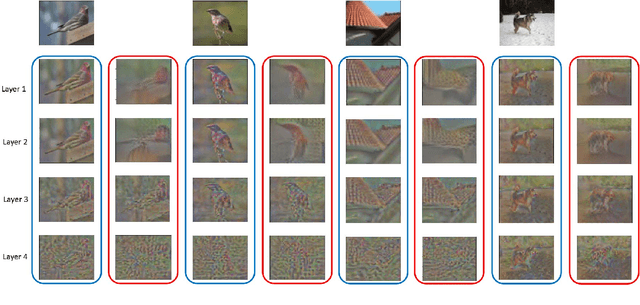
The ability to quickly recognize and learn new visual concepts from limited samples enables humans to swiftly adapt to new environments. This ability is enabled by semantic associations of novel concepts with those that have already been learned and stored in memory. Computers can start to ascertain similar abilities by utilizing a semantic concept space. A concept space is a high-dimensional semantic space in which similar abstract concepts appear close and dissimilar ones far apart. In this paper, we propose a novel approach to one-shot learning that builds on this idea. Our approach learns to map a novel sample instance to a concept, relates that concept to the existing ones in the concept space and generates new instances, by interpolating among the concepts, to help learning. Instead of synthesizing new image instance, we propose to directly synthesize instance features by leveraging semantics using a novel auto-encoder network we call dual TriNet. The encoder part of the TriNet learns to map multi-layer visual features of deep CNNs, that is, multi-level concepts, to a semantic vector. In semantic space, we search for related concepts, which are then projected back into the image feature spaces by the decoder portion of the TriNet. Two strategies in the semantic space are explored. Notably, this seemingly simple strategy results in complex augmented feature distributions in the image feature space, leading to substantially better performance.