 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShot in the Dark: Few-Shot Learning with No Base-Class Labels
Paper and Code

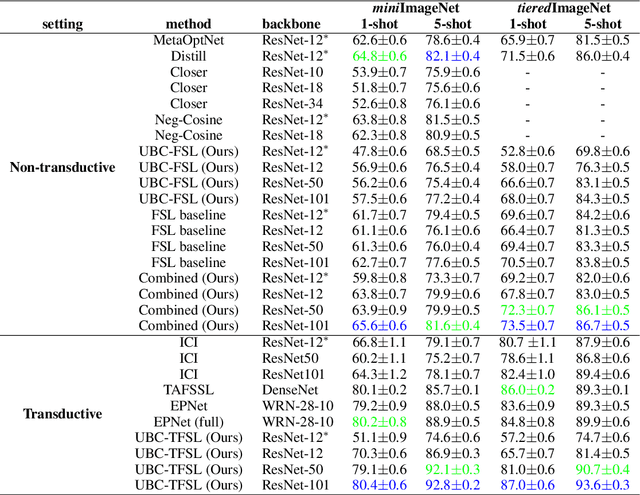
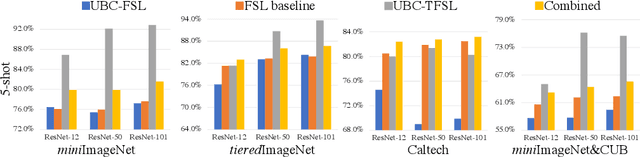

Few-shot learning aims to learn classifiers for new objects from a small number of labeled examples. But it does not do this in a vacuum. Usually, a strong inductive bias is borrowed from the supervised learning of base classes. This inductive bias enables more statistically efficient learning of the new classes. In this work, we show that no labels are needed to develop such an inductive bias, and that self-supervised learning can provide a powerful inductive bias for few-shot learning. This is particularly effective when the unlabeled data for learning such a bias contains not only examples of the base classes, but also examples of the novel classes. The setting in which unlabeled examples of the novel classes are available is known as the transductive setting. Our method outperforms state-of-the-art few-shot learning methods, including other transductive learning methods, by 3.9% for 5-shot accuracy on miniImageNet without using any base class labels. By benchmarking unlabeled-base-class (UBC) few-shot learning and UBC transductive few-shot learning, we demonstrate the great potential of self-supervised feature learning: self-supervision alone is sufficient to create a remarkably good inductive bias for few-shot learning. This motivates a rethinking of whether base-class labels are necessary at all for few-shot learning. We also explore the relationship between self-supervised features and supervised features, comparing both their transferability and their complementarity in the non-transductive setting. By combining supervised and self-supervised features learned from base classes, we also achieve a new state-of-the-art in the non-transductive setting, outperforming all previous methods.