 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Decentralized Momentum Stochastic Gradient Methods for Nonconvex Optimization
Aug 07, 2025In this paper, we design two compressed decentralized algorithms for solving nonconvex stochastic optimization under two different scenarios. Both algorithms adopt a momentum technique to achieve fast convergence and a message-compression technique to save communication costs. Though momentum acceleration and compressed communication have been used in literature, it is highly nontrivial to theoretically prove the effectiveness of their composition in a decentralized algorithm that can maintain the benefits of both sides, because of the need to simultaneously control the consensus error, the compression error, and the bias from the momentum gradient. For the scenario where gradients are bounded, our proposal is a compressed decentralized adaptive method. To the best of our knowledge, this is the first decentralized adaptive stochastic gradient method with compressed communication. For the scenario of data heterogeneity without bounded gradients, our proposal is a compressed decentralized heavy-ball method, which applies a gradient tracking technique to address the challenge of data heterogeneity. Notably, both methods achieve an optimal convergence rate, and they can achieve linear speed up and adopt topology-independent algorithmic parameters within a certain regime of the user-specified error tolerance. Superior empirical performance is observed over state-of-the-art methods on training deep neural networks (DNNs) and Transformers.
LaMAGIC2: Advanced Circuit Formulations for Language Model-Based Analog Topology Generation
Jun 11, 2025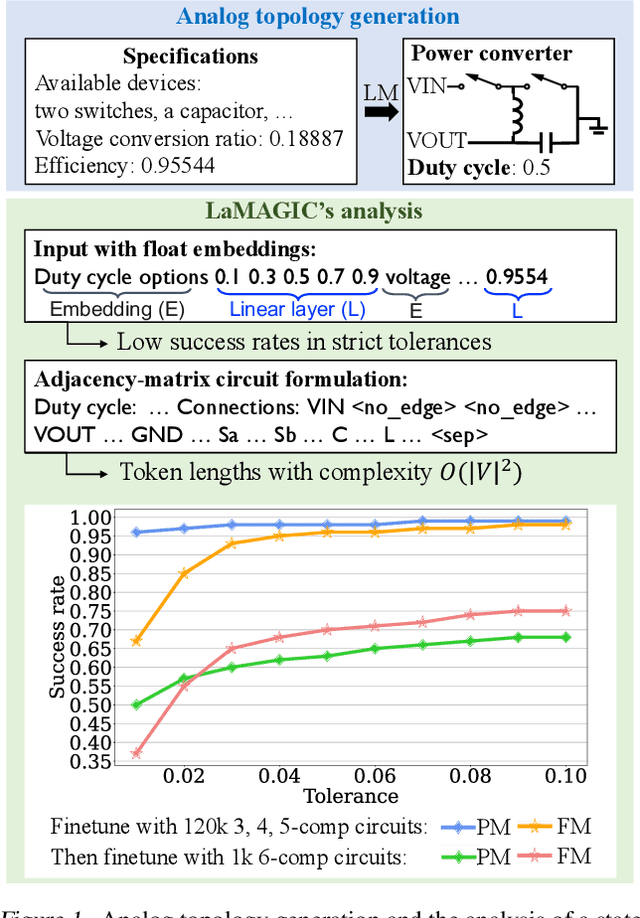

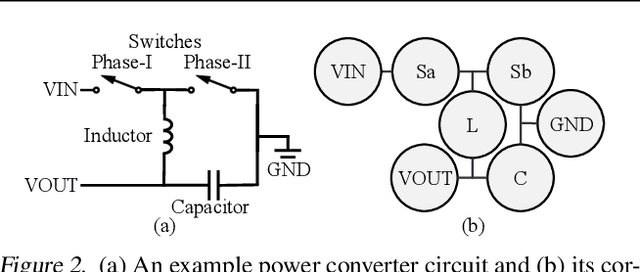

Automation of analog topology design is crucial due to customized requirements of modern applications with heavily manual engineering efforts. The state-of-the-art work applies a sequence-to-sequence approach and supervised finetuning on language models to generate topologies given user specifications. However, its circuit formulation is inefficient due to O(|V |2) token length and suffers from low precision sensitivity to numeric inputs. In this work, we introduce LaMAGIC2, a succinct float-input canonical formulation with identifier (SFCI) for language model-based analog topology generation. SFCI addresses these challenges by improving component-type recognition through identifier-based representations, reducing token length complexity to O(|V |), and enhancing numeric precision sensitivity for better performance under tight tolerances. Our experiments demonstrate that LaMAGIC2 achieves 34% higher success rates under a tight tolerance of 0.01 and 10X lower MSEs compared to a prior method. LaMAGIC2 also exhibits better transferability for circuits with more vertices with up to 58.5% improvement. These advancements establish LaMAGIC2 as a robust framework for analog topology generation.
FlashFormer: Whole-Model Kernels for Efficient Low-Batch Inference
May 28, 2025The size and compute characteristics of modern large language models have led to an increased interest in developing specialized kernels tailored for training and inference. Existing kernels primarily optimize for compute utilization, targeting the large-batch training and inference settings. However, low-batch inference, where memory bandwidth and kernel launch overheads contribute are significant factors, remains important for many applications of interest such as in edge deployment and latency-sensitive applications. This paper describes FlashFormer, a proof-of-concept kernel for accelerating single-batch inference for transformer-based large language models. Across various model sizes and quantizations settings, we observe nontrivial speedups compared to existing state-of-the-art inference kernels.
PaTH Attention: Position Encoding via Accumulating Householder Transformations
May 22, 2025The attention mechanism is a core primitive in modern large language models (LLMs) and AI more broadly. Since attention by itself is permutation-invariant, position encoding is essential for modeling structured domains such as language. Rotary position encoding (RoPE) has emerged as the de facto standard approach for position encoding and is part of many modern LLMs. However, in RoPE the key/query transformation between two elements in a sequence is only a function of their relative position and otherwise independent of the actual input. This limits the expressivity of RoPE-based transformers. This paper describes PaTH, a flexible data-dependent position encoding scheme based on accumulated products of Householder(like) transformations, where each transformation is data-dependent, i.e., a function of the input. We derive an efficient parallel algorithm for training through exploiting a compact representation of products of Householder matrices, and implement a FlashAttention-style blockwise algorithm that minimizes I/O cost. Across both targeted synthetic benchmarks and moderate-scale real-world language modeling experiments, we find that PaTH demonstrates superior performance compared to RoPE and other recent baselines.
Do Larger Language Models Imply Better Reasoning? A Pretraining Scaling Law for Reasoning
Apr 04, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks requiring complex reasoning. However, the effects of scaling on their reasoning abilities remain insufficiently understood. In this paper, we introduce a synthetic multihop reasoning environment designed to closely replicate the structure and distribution of real-world large-scale knowledge graphs. Our reasoning task involves completing missing edges in the graph, which requires advanced multi-hop reasoning and mimics real-world reasoning scenarios. To evaluate this, we pretrain language models (LMs) from scratch solely on triples from the incomplete graph and assess their ability to infer the missing edges. Interestingly, we observe that overparameterization can impair reasoning performance due to excessive memorization. We investigate different factors that affect this U-shaped loss curve, including graph structure, model size, and training steps. To predict the optimal model size for a specific knowledge graph, we find an empirical scaling that linearly maps the knowledge graph search entropy to the optimal model size. This work provides new insights into the relationship between scaling and reasoning in LLMs, shedding light on possible ways to optimize their performance for reasoning tasks.
Stick-breaking Attention
Oct 23, 2024



The self-attention mechanism traditionally relies on the softmax operator, necessitating positional embeddings like RoPE, or position biases to account for token order. But current methods using still face length generalisation challenges. We propose an alternative attention mechanism based on the stick-breaking process: For each token before the current, we determine a break point $\beta_{i,j}$, which represents the proportion of the remaining stick to allocate to the current token. We repeat the process until the stick is fully allocated, resulting in a sequence of attention weights. This process naturally incorporates recency bias, which has linguistic motivations for grammar parsing (Shen et. al., 2017). We study the implications of replacing the conventional softmax-based attention mechanism with stick-breaking attention. We then discuss implementation of numerically stable stick-breaking attention and adapt Flash Attention to accommodate this mechanism. When used as a drop-in replacement for current softmax+RoPE attention systems, we find that stick-breaking attention performs competitively with current methods on length generalisation and downstream tasks. Stick-breaking also performs well at length generalisation, allowing a model trained with $2^{11}$ context window to perform well at $2^{14}$ with perplexity improvements.
Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler
Aug 23, 2024

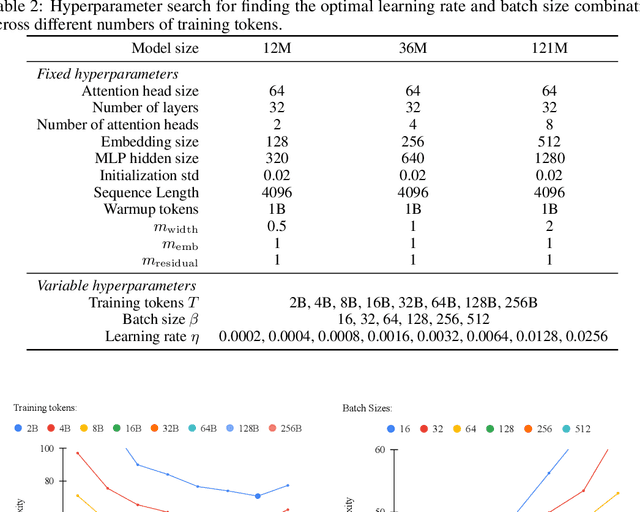
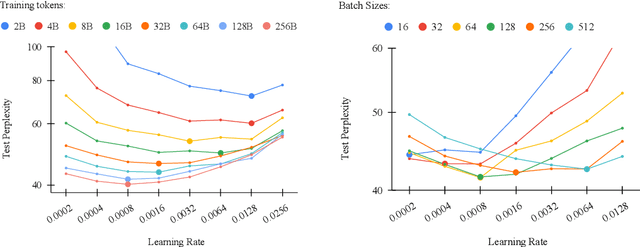
Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored. In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (muP) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models. We open-source these pretrained models at https://ibm.biz/BdKhLa.
FlexAttention for Efficient High-Resolution Vision-Language Models
Jul 29, 2024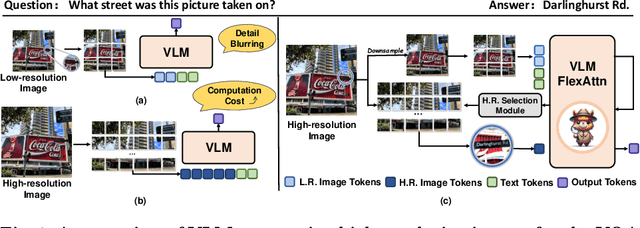
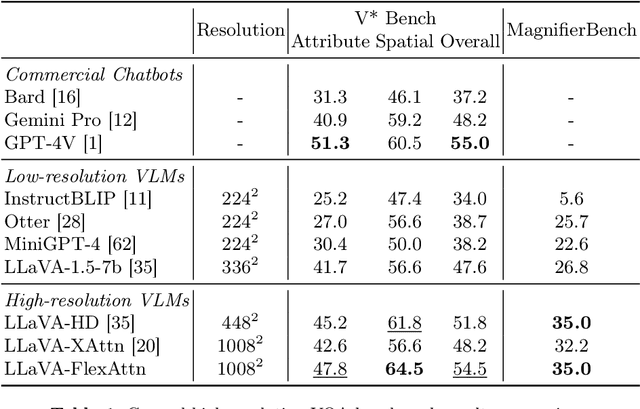
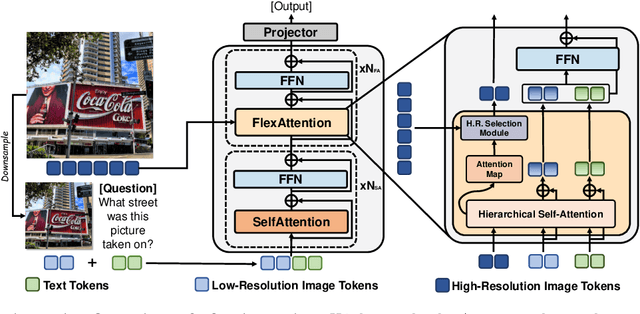
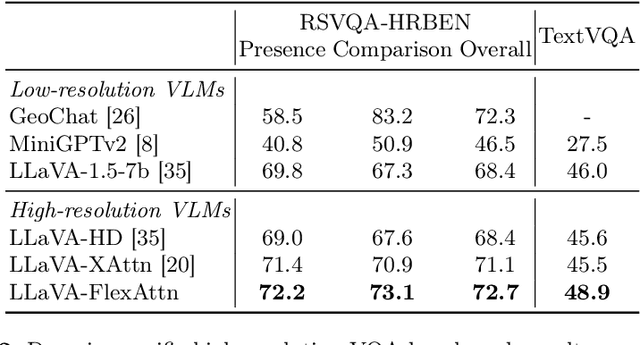
Current high-resolution vision-language models encode images as high-resolution image tokens and exhaustively take all these tokens to compute attention, which significantly increases the computational cost. To address this problem, we propose FlexAttention, a flexible attention mechanism for efficient high-resolution vision-language models. Specifically, a high-resolution image is encoded both as high-resolution tokens and low-resolution tokens, where only the low-resolution tokens and a few selected high-resolution tokens are utilized to calculate the attention map, which greatly shrinks the computational cost. The high-resolution tokens are selected via a high-resolution selection module which could retrieve tokens of relevant regions based on an input attention map. The selected high-resolution tokens are then concatenated to the low-resolution tokens and text tokens, and input to a hierarchical self-attention layer which produces an attention map that could be used for the next-step high-resolution token selection. The hierarchical self-attention process and high-resolution token selection process are performed iteratively for each attention layer. Experiments on multimodal benchmarks prove that our FlexAttention outperforms existing high-resolution VLMs (e.g., relatively ~9% in V* Bench, ~7% in TextVQA), while also significantly reducing the computational cost by nearly 40%.
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024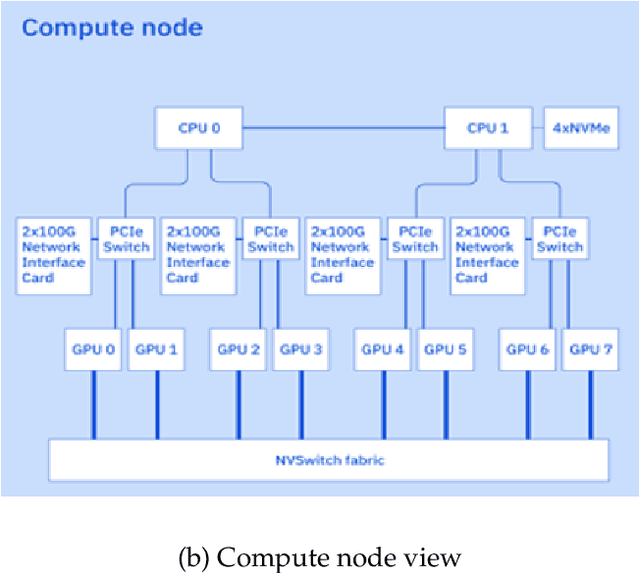
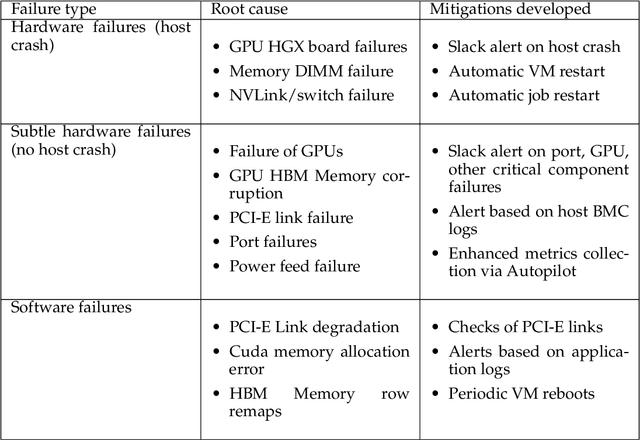
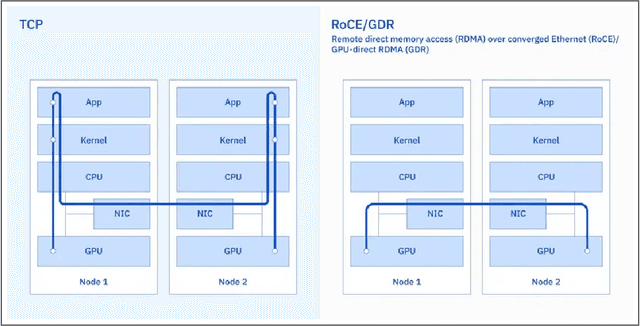
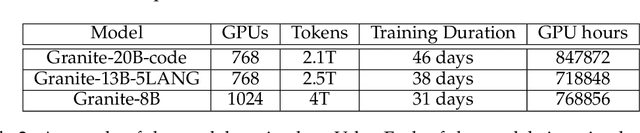
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.