 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
Mar 15, 2026Transformers are highly parallel but are limited to computations in the TC$^0$ complexity class, excluding tasks such as entity tracking and code execution that provably require greater expressive power. Motivated by this limitation, we revisit non-linear Recurrent Neural Networks (RNNs) for language modeling and introduce Matrix-to-Matrix RNN (M$^2$RNN): an architecture with matrix-valued hidden states and expressive non-linear state transitions. We demonstrate that the language modeling performance of non-linear RNNs is limited by their state size. We also demonstrate how the state size expansion mechanism enables efficient use of tensor cores. Empirically, M$^2$RNN achieves perfect state tracking generalization at sequence lengths not seen during training. These benefits also translate to large-scale language modeling. In hybrid settings that interleave recurrent layers with attention, Hybrid M$^2$RNN outperforms equivalent Gated DeltaNet hybrids by $0.4$-$0.5$ perplexity points on a 7B MoE model, while using $3\times$ smaller state sizes for the recurrent layers. Notably, replacing even a single recurrent layer with M$^2$RNN in an existing hybrid architecture yields accuracy gains comparable to Hybrid M$^2$RNN with minimal impact on training throughput. Further, the Hybrid Gated DeltaNet models with a single M$^2$RNN layer also achieve superior long-context generalization, outperforming state-of-the-art hybrid linear attention architectures by up to $8$ points on LongBench. Together, these results establish non-linear RNN layers as a compelling building block for efficient and scalable language models.
Distilling to Hybrid Attention Models via KL-Guided Layer Selection
Dec 23, 2025Distilling pretrained softmax attention Transformers into more efficient hybrid architectures that interleave softmax and linear attention layers is a promising approach for improving the inference efficiency of LLMs without requiring expensive pretraining from scratch. A critical factor in the conversion process is layer selection, i.e., deciding on which layers to convert to linear attention variants. This paper describes a simple and efficient recipe for layer selection that uses layer importance scores derived from a small amount of training on generic text data. Once the layers have been selected we use a recent pipeline for the distillation process itself \citep[RADLADS;][]{goldstein2025radlads}, which consists of attention weight transfer, hidden state alignment, KL-based distribution matching, followed by a small amount of finetuning. We find that this approach is more effective than existing approaches for layer selection, including heuristics that uniformly interleave linear attentions based on a fixed ratio, as well as more involved approaches that rely on specialized diagnostic datasets.
PaTH Attention: Position Encoding via Accumulating Householder Transformations
May 22, 2025The attention mechanism is a core primitive in modern large language models (LLMs) and AI more broadly. Since attention by itself is permutation-invariant, position encoding is essential for modeling structured domains such as language. Rotary position encoding (RoPE) has emerged as the de facto standard approach for position encoding and is part of many modern LLMs. However, in RoPE the key/query transformation between two elements in a sequence is only a function of their relative position and otherwise independent of the actual input. This limits the expressivity of RoPE-based transformers. This paper describes PaTH, a flexible data-dependent position encoding scheme based on accumulated products of Householder(like) transformations, where each transformation is data-dependent, i.e., a function of the input. We derive an efficient parallel algorithm for training through exploiting a compact representation of products of Householder matrices, and implement a FlashAttention-style blockwise algorithm that minimizes I/O cost. Across both targeted synthetic benchmarks and moderate-scale real-world language modeling experiments, we find that PaTH demonstrates superior performance compared to RoPE and other recent baselines.
Do Larger Language Models Imply Better Reasoning? A Pretraining Scaling Law for Reasoning
Apr 04, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks requiring complex reasoning. However, the effects of scaling on their reasoning abilities remain insufficiently understood. In this paper, we introduce a synthetic multihop reasoning environment designed to closely replicate the structure and distribution of real-world large-scale knowledge graphs. Our reasoning task involves completing missing edges in the graph, which requires advanced multi-hop reasoning and mimics real-world reasoning scenarios. To evaluate this, we pretrain language models (LMs) from scratch solely on triples from the incomplete graph and assess their ability to infer the missing edges. Interestingly, we observe that overparameterization can impair reasoning performance due to excessive memorization. We investigate different factors that affect this U-shaped loss curve, including graph structure, model size, and training steps. To predict the optimal model size for a specific knowledge graph, we find an empirical scaling that linearly maps the knowledge graph search entropy to the optimal model size. This work provides new insights into the relationship between scaling and reasoning in LLMs, shedding light on possible ways to optimize their performance for reasoning tasks.
Stick-breaking Attention
Oct 23, 2024



The self-attention mechanism traditionally relies on the softmax operator, necessitating positional embeddings like RoPE, or position biases to account for token order. But current methods using still face length generalisation challenges. We propose an alternative attention mechanism based on the stick-breaking process: For each token before the current, we determine a break point $\beta_{i,j}$, which represents the proportion of the remaining stick to allocate to the current token. We repeat the process until the stick is fully allocated, resulting in a sequence of attention weights. This process naturally incorporates recency bias, which has linguistic motivations for grammar parsing (Shen et. al., 2017). We study the implications of replacing the conventional softmax-based attention mechanism with stick-breaking attention. We then discuss implementation of numerically stable stick-breaking attention and adapt Flash Attention to accommodate this mechanism. When used as a drop-in replacement for current softmax+RoPE attention systems, we find that stick-breaking attention performs competitively with current methods on length generalisation and downstream tasks. Stick-breaking also performs well at length generalisation, allowing a model trained with $2^{11}$ context window to perform well at $2^{14}$ with perplexity improvements.
Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler
Aug 23, 2024

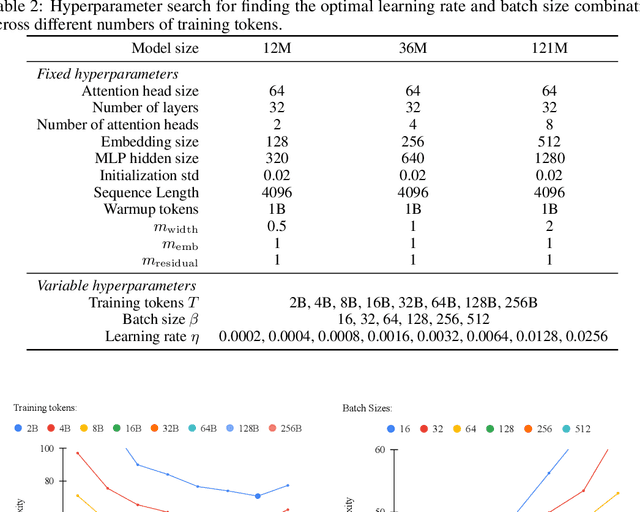
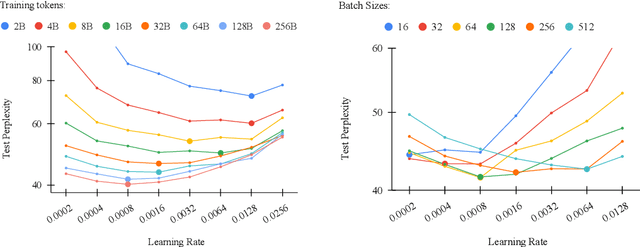
Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored. In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (muP) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models. We open-source these pretrained models at https://ibm.biz/BdKhLa.
Scattered Mixture-of-Experts Implementation
Mar 13, 2024We present ScatterMoE, an implementation of Sparse Mixture-of-Experts (SMoE) on GPUs. ScatterMoE builds upon existing implementations, and overcoming some of the limitations to improve inference and training speed, and memory footprint. This implementation achieves this by avoiding padding and making excessive copies of the input. We introduce ParallelLinear, the main component we use to build our implementation and the various kernels used to speed up the operation. We benchmark our implementation against Megablocks, and show that it enables a higher throughput and lower memory footprint. We also show how ParallelLinear enables extension of the Mixture-of-Experts concept by demonstrating with an implementation of Mixture of Attention.
CattleEyeView: A Multi-task Top-down View Cattle Dataset for Smarter Precision Livestock Farming
Dec 14, 2023

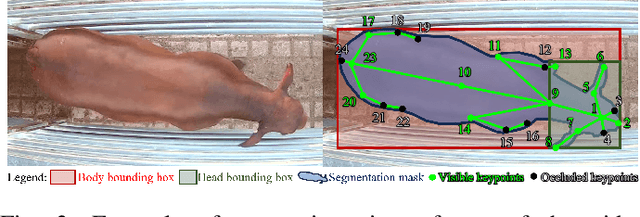
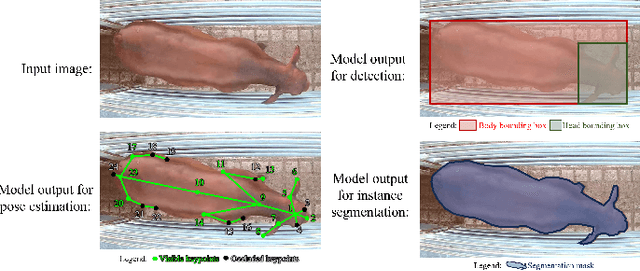
Cattle farming is one of the important and profitable agricultural industries. Employing intelligent automated precision livestock farming systems that can count animals, track the animals and their poses will raise productivity and significantly reduce the heavy burden on its already limited labor pool. To achieve such intelligent systems, a large cattle video dataset is essential in developing and training such models. However, many current animal datasets are tailored to few tasks or other types of animals, which result in poorer model performance when applied to cattle. Moreover, they do not provide top-down views of cattle. To address such limitations, we introduce CattleEyeView dataset, the first top-down view multi-task cattle video dataset for a variety of inter-related tasks (i.e., counting, detection, pose estimation, tracking, instance segmentation) that are useful to count the number of cows and assess their growth and well-being. The dataset contains 753 distinct top-down cow instances in 30,703 frames (14 video sequences). We perform benchmark experiments to evaluate the model's performance for each task. The dataset and codes can be found at https://github.com/AnimalEyeQ/CattleEyeView.
Sparse Universal Transformer
Oct 11, 2023



The Universal Transformer (UT) is a variant of the Transformer that shares parameters across its layers. Empirical evidence shows that UTs have better compositional generalization than Vanilla Transformers (VTs) in formal language tasks. The parameter-sharing also affords it better parameter efficiency than VTs. Despite its many advantages, scaling UT parameters is much more compute and memory intensive than scaling up a VT. This paper proposes the Sparse Universal Transformer (SUT), which leverages Sparse Mixture of Experts (SMoE) and a new stick-breaking-based dynamic halting mechanism to reduce UT's computation complexity while retaining its parameter efficiency and generalization ability. Experiments show that SUT achieves the same performance as strong baseline models while only using half computation and parameters on WMT'14 and strong generalization results on formal language tasks (Logical inference and CFQ). The new halting mechanism also enables around 50\% reduction in computation during inference with very little performance decrease on formal language tasks.
ModuleFormer: Learning Modular Large Language Models From Uncurated Data
Jun 07, 2023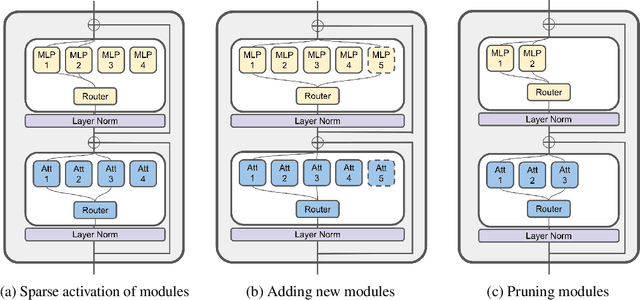

Large Language Models (LLMs) have achieved remarkable results. But existing models are expensive to train and deploy, and it is also difficult to expand their knowledge beyond pre-training data without forgetting previous knowledge. This paper proposes a new neural network architecture, ModuleFormer, that leverages modularity to improve the efficiency and flexibility of large language models. ModuleFormer is based on the Sparse Mixture of Experts (SMoE). Unlike the previous SMoE-based modular language model [Gururangan et al., 2021], which requires domain-labeled data to learn domain-specific experts, ModuleFormer can induce modularity from uncurated data with its new load balancing and load concentration losses. ModuleFormer is a modular architecture that includes two different types of modules, new stick-breaking attention heads, and feedforward experts. Different modules are sparsely activated conditions on the input token during training and inference. In our experiment, we found that the modular architecture enables three important abilities for large pre-trained language models: 1) Efficiency, since ModuleFormer only activates a subset of its modules for each input token, thus it could achieve the same performance as dense LLMs with more than two times throughput; 2) Extendability, ModuleFormer is more immune to catastrophic forgetting than dense LLMs and can be easily extended with new modules to learn new knowledge that is not included in the training data; 3) Specialisation, finetuning ModuleFormer could specialize a subset of modules to the finetuning task, and the task-unrelated modules could be easily pruned for a lightweight deployment.