 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCattleEyeView: A Multi-task Top-down View Cattle Dataset for Smarter Precision Livestock Farming
Dec 14, 2023

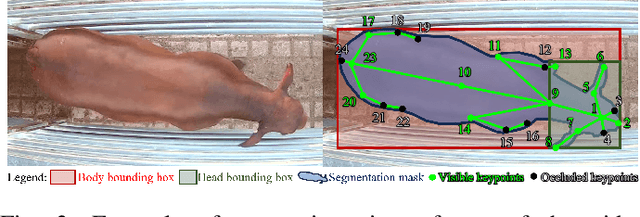
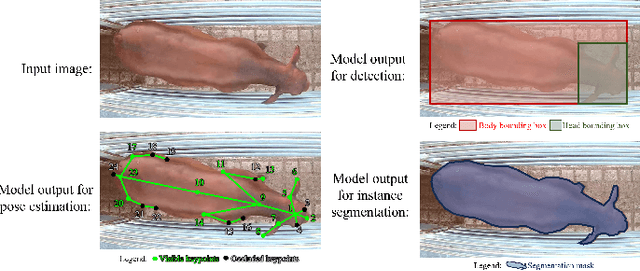
Cattle farming is one of the important and profitable agricultural industries. Employing intelligent automated precision livestock farming systems that can count animals, track the animals and their poses will raise productivity and significantly reduce the heavy burden on its already limited labor pool. To achieve such intelligent systems, a large cattle video dataset is essential in developing and training such models. However, many current animal datasets are tailored to few tasks or other types of animals, which result in poorer model performance when applied to cattle. Moreover, they do not provide top-down views of cattle. To address such limitations, we introduce CattleEyeView dataset, the first top-down view multi-task cattle video dataset for a variety of inter-related tasks (i.e., counting, detection, pose estimation, tracking, instance segmentation) that are useful to count the number of cows and assess their growth and well-being. The dataset contains 753 distinct top-down cow instances in 30,703 frames (14 video sequences). We perform benchmark experiments to evaluate the model's performance for each task. The dataset and codes can be found at https://github.com/AnimalEyeQ/CattleEyeView.
Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding
Apr 18, 2022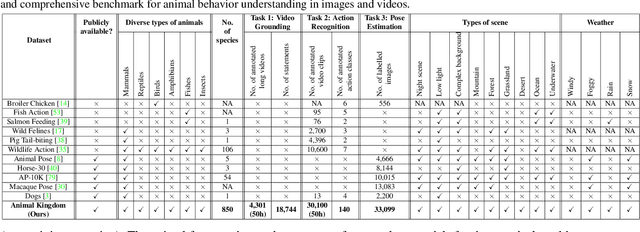
Understanding animals' behaviors is significant for a wide range of applications. However, existing animal behavior datasets have limitations in multiple aspects, including limited numbers of animal classes, data samples and provided tasks, and also limited variations in environmental conditions and viewpoints. To address these limitations, we create a large and diverse dataset, Animal Kingdom, that provides multiple annotated tasks to enable a more thorough understanding of natural animal behaviors. The wild animal footages used in our dataset record different times of the day in extensive range of environments containing variations in backgrounds, viewpoints, illumination and weather conditions. More specifically, our dataset contains 50 hours of annotated videos to localize relevant animal behavior segments in long videos for the video grounding task, 30K video sequences for the fine-grained multi-label action recognition task, and 33K frames for the pose estimation task, which correspond to a diverse range of animals with 850 species across 6 major animal classes. Such a challenging and comprehensive dataset shall be able to facilitate the community to develop, adapt, and evaluate various types of advanced methods for animal behavior analysis. Moreover, we propose a Collaborative Action Recognition (CARe) model that learns general and specific features for action recognition with unseen new animals. This method achieves promising performance in our experiments. Our dataset can be found at https://sutdcv.github.io/Animal-Kingdom.