 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler
Aug 23, 2024

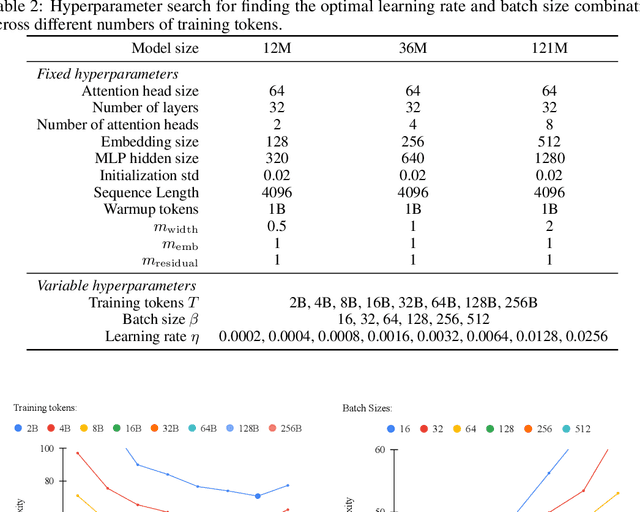
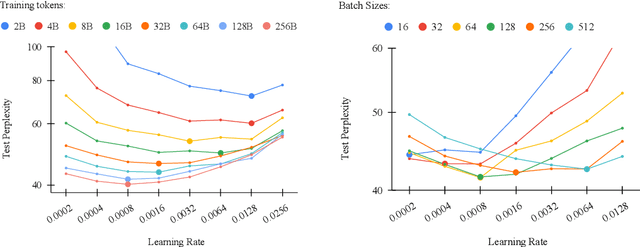
Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored. In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (muP) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models. We open-source these pretrained models at https://ibm.biz/BdKhLa.
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024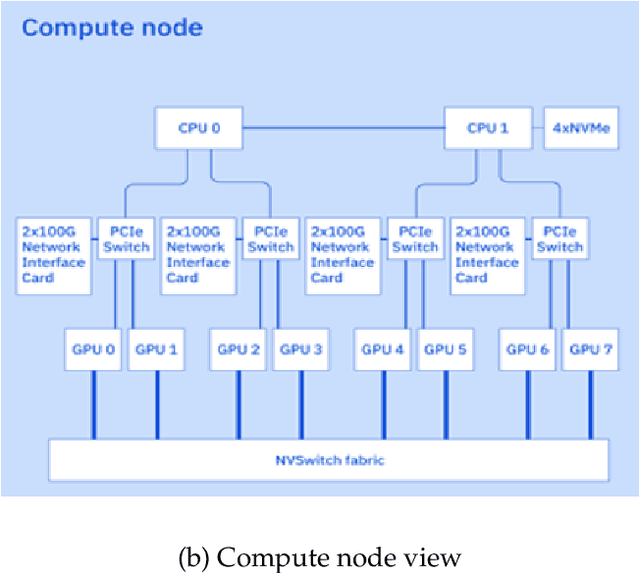
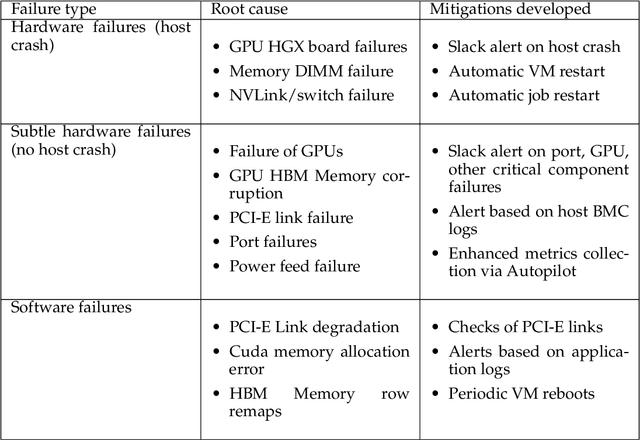
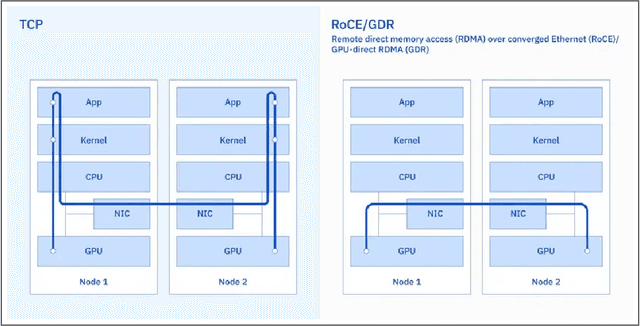
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



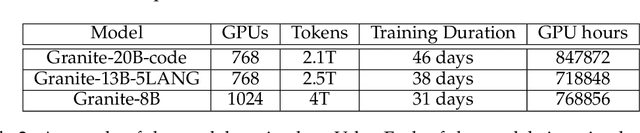
Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Rapid Development of Compositional AI
Feb 12, 2023
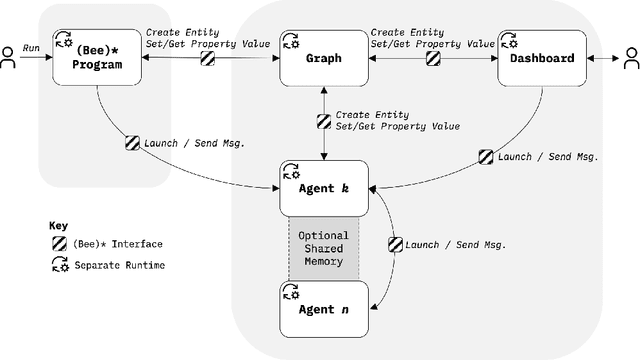
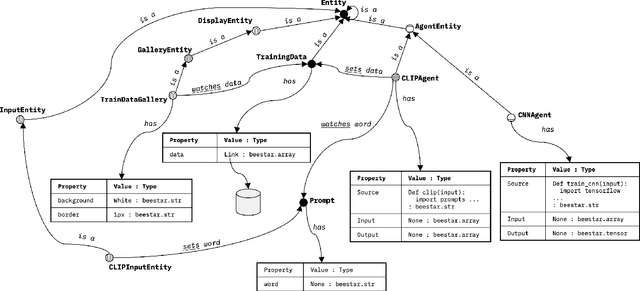

Compositional AI systems, which combine multiple artificial intelligence components together with other application components to solve a larger problem, have no known pattern of development and are often approached in a bespoke and ad hoc style. This makes development slower and harder to reuse for future applications. To support the full rapid development cycle of compositional AI applications, we have developed a novel framework called (Bee)* (written as a regular expression and pronounced as "beestar"). We illustrate how (Bee)* supports building integrated, scalable, and interactive compositional AI applications with a simplified developer experience.
* Accepted to ICSE 2023, NIER track
Data-Centric Mixed-Variable Bayesian Optimization For Materials Design
Jul 04, 2019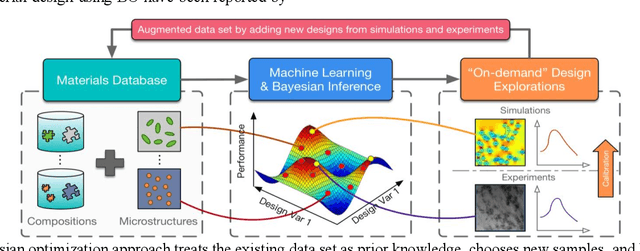

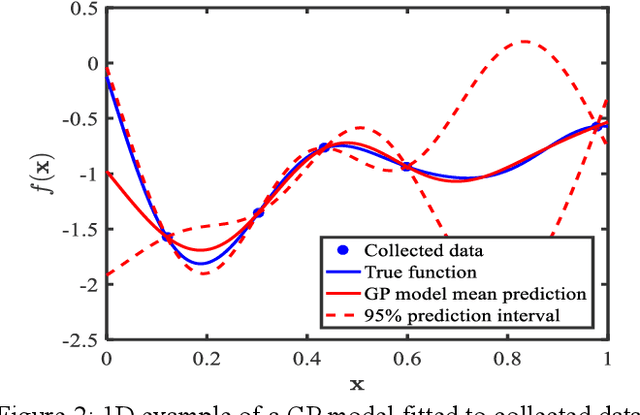
Materials design can be cast as an optimization problem with the goal of achieving desired properties, by varying material composition, microstructure morphology, and processing conditions. Existence of both qualitative and quantitative material design variables leads to disjointed regions in property space, making the search for optimal design challenging. Limited availability of experimental data and the high cost of simulations magnify the challenge. This situation calls for design methodologies that can extract useful information from existing data and guide the search for optimal designs efficiently. To this end, we present a data-centric, mixed-variable Bayesian Optimization framework that integrates data from literature, experiments, and simulations for knowledge discovery and computational materials design. Our framework pivots around the Latent Variable Gaussian Process (LVGP), a novel Gaussian Process technique which projects qualitative variables on a continuous latent space for covariance formulation, as the surrogate model to quantify "lack of data" uncertainty. Expected improvement, an acquisition criterion that balances exploration and exploitation, helps navigate a complex, nonlinear design space to locate the optimum design. The proposed framework is tested through a case study which seeks to concurrently identify the optimal composition and morphology for insulating polymer nanocomposites. We also present an extension of mixed-variable Bayesian Optimization for multiple objectives to identify the Pareto Frontier within tens of iterations. These findings project Bayesian Optimization as a powerful tool for design of engineered material systems.
Unsupervised Hard Example Mining from Videos for Improved Object Detection
Aug 13, 2018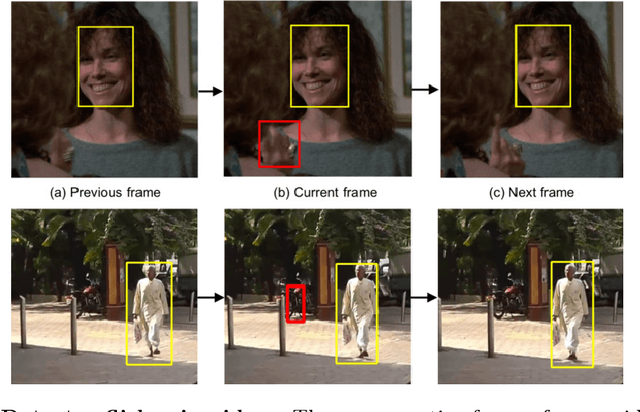


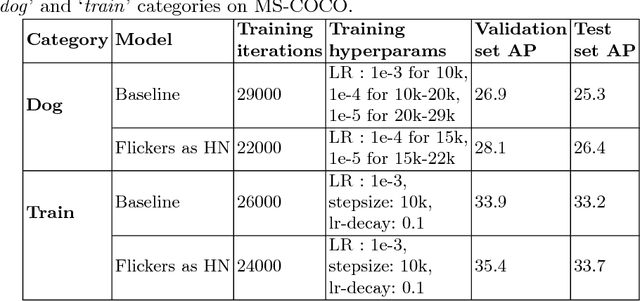
Important gains have recently been obtained in object detection by using training objectives that focus on {\em hard negative} examples, i.e., negative examples that are currently rated as positive or ambiguous by the detector. These examples can strongly influence parameters when the network is trained to correct them. Unfortunately, they are often sparse in the training data, and are expensive to obtain. In this work, we show how large numbers of hard negatives can be obtained {\em automatically} by analyzing the output of a trained detector on video sequences. In particular, detections that are {\em isolated in time}, i.e., that have no associated preceding or following detections, are likely to be hard negatives. We describe simple procedures for mining large numbers of such hard negatives (and also hard {\em positives}) from unlabeled video data. Our experiments show that retraining detectors on these automatically obtained examples often significantly improves performance. We present experiments on multiple architectures and multiple data sets, including face detection, pedestrian detection and other object categories.