 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Code LLMs: Data Mix or Model Merge?
Jan 28, 2026Recent research advocates deploying smaller, specialized code LLMs in agentic frameworks alongside frontier models, sparking interest in efficient strategies for multi-task learning that balance performance, constraints, and costs. We compare two approaches for creating small, multi-task code LLMs: data mixing versus model merging. We conduct extensive experiments across two model families (Qwen Coder and DeepSeek Coder) at two scales (2B and 7B parameters), fine-tuning them for code generation and code summarization tasks. Our evaluation on HumanEval, MBPP, and CodeXGlue benchmarks reveals that model merging achieves the best overall performance at larger scale across model families, retaining 96% of specialized model performance on code generation tasks while maintaining summarization capabilities. Notably, merged models can even surpass individually fine-tuned models, with our best configuration of Qwen Coder 2.5 7B model achieving 92.7% Pass@1 on HumanEval compared to 90.9% for its task-specific fine-tuned equivalent. At a smaller scale we find instead data mixing to be a preferred strategy. We further introduce a weight analysis technique to understand how different tasks affect model parameters and their implications for merging strategies. The results suggest that careful merging and mixing strategies can effectively combine task-specific capabilities without significant performance degradation, making them ideal for resource-constrained deployment scenarios.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
A Comparative Analysis of Task-Agnostic Distillation Methods for Compressing Transformer Language Models
Oct 13, 2023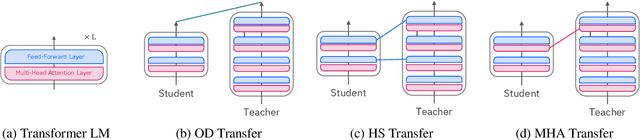


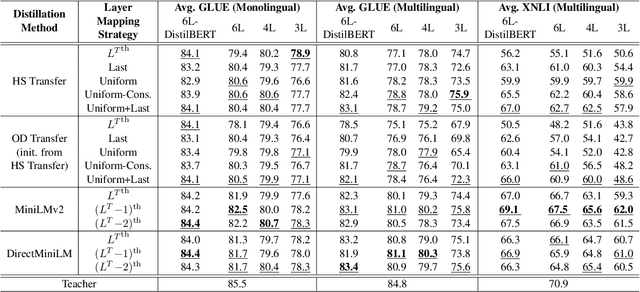
Large language models have become a vital component in modern NLP, achieving state of the art performance in a variety of tasks. However, they are often inefficient for real-world deployment due to their expensive inference costs. Knowledge distillation is a promising technique to improve their efficiency while retaining most of their effectiveness. In this paper, we reproduce, compare and analyze several representative methods for task-agnostic (general-purpose) distillation of Transformer language models. Our target of study includes Output Distribution (OD) transfer, Hidden State (HS) transfer with various layer mapping strategies, and Multi-Head Attention (MHA) transfer based on MiniLMv2. Through our extensive experiments, we study the effectiveness of each method for various student architectures in both monolingual (English) and multilingual settings. Overall, we show that MHA transfer based on MiniLMv2 is generally the best option for distillation and explain the potential reasons behind its success. Moreover, we show that HS transfer remains as a competitive baseline, especially under a sophisticated layer mapping strategy, while OD transfer consistently lags behind other approaches. Findings from this study helped us deploy efficient yet effective student models for latency-critical applications.
CoSiNES: Contrastive Siamese Network for Entity Standardization
Jun 05, 2023Entity standardization maps noisy mentions from free-form text to standard entities in a knowledge base. The unique challenge of this task relative to other entity-related tasks is the lack of surrounding context and numerous variations in the surface form of the mentions, especially when it comes to generalization across domains where labeled data is scarce. Previous research mostly focuses on developing models either heavily relying on context, or dedicated solely to a specific domain. In contrast, we propose CoSiNES, a generic and adaptable framework with Contrastive Siamese Network for Entity Standardization that effectively adapts a pretrained language model to capture the syntax and semantics of the entities in a new domain. We construct a new dataset in the technology domain, which contains 640 technical stack entities and 6,412 mentions collected from industrial content management systems. We demonstrate that CoSiNES yields higher accuracy and faster runtime than baselines derived from leading methods in this domain. CoSiNES also achieves competitive performance in four standard datasets from the chemistry, medicine, and biomedical domains, demonstrating its cross-domain applicability.
Neural Architecture Search for Effective Teacher-Student Knowledge Transfer in Language Models
Mar 16, 2023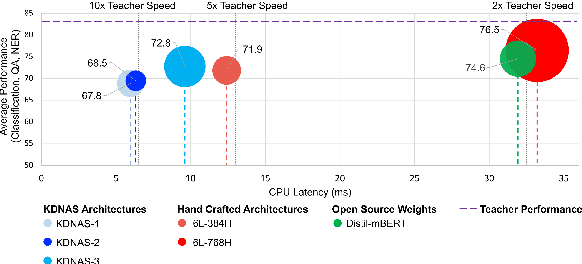

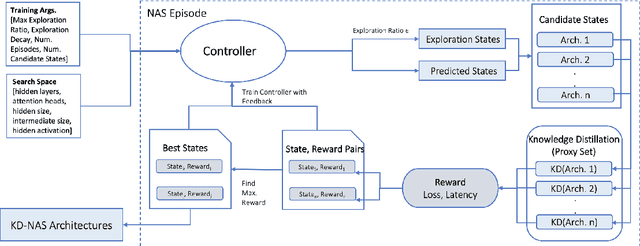
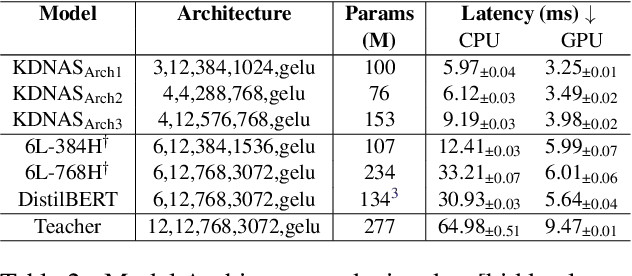
Large pre-trained language models have achieved state-of-the-art results on a variety of downstream tasks. Knowledge Distillation (KD) of a smaller student model addresses their inefficiency, allowing for deployment in resource-constraint environments. KD however remains ineffective, as the student is manually selected from a set of existing options already pre-trained on large corpora, a sub-optimal choice within the space of all possible student architectures. This paper proposes KD-NAS, the use of Neural Architecture Search (NAS) guided by the Knowledge Distillation process to find the optimal student model for distillation from a teacher, for a given natural language task. In each episode of the search process, a NAS controller predicts a reward based on a combination of accuracy on the downstream task and latency of inference. The top candidate architectures are then distilled from the teacher on a small proxy set. Finally the architecture(s) with the highest reward is selected, and distilled on the full downstream task training set. When distilling on the MNLI task, our KD-NAS model produces a 2 point improvement in accuracy on GLUE tasks with equivalent GPU latency with respect to a hand-crafted student architecture available in the literature. Using Knowledge Distillation, this model also achieves a 1.4x speedup in GPU Latency (3.2x speedup on CPU) with respect to a BERT-Base Teacher, while maintaining 97% performance on GLUE Tasks (without CoLA). We also obtain an architecture with equivalent performance as the hand-crafted student model on the GLUE benchmark, but with a 15% speedup in GPU latency (20% speedup in CPU latency) and 0.8 times the number of parameters
Large Scale Neural Architecture Search with Polyharmonic Splines
Nov 20, 2020
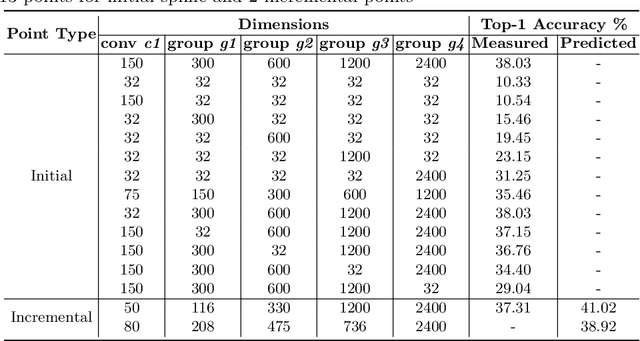
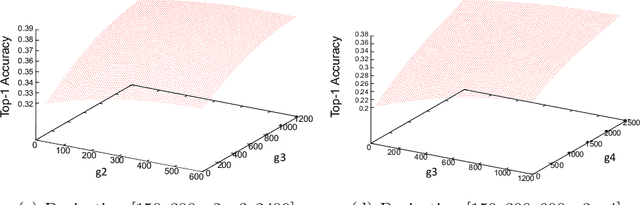
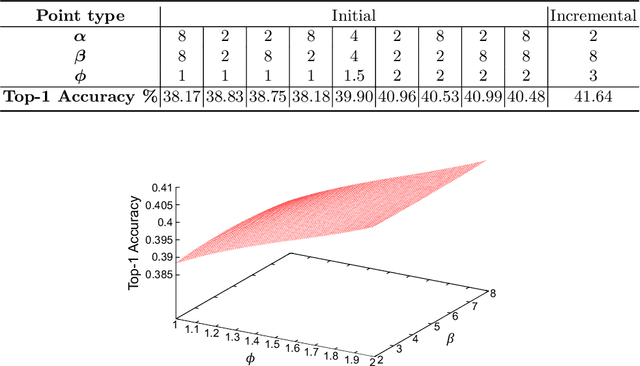
Neural Architecture Search (NAS) is a powerful tool to automatically design deep neural networks for many tasks, including image classification. Due to the significant computational burden of the search phase, most NAS methods have focused so far on small, balanced datasets. All attempts at conducting NAS at large scale have employed small proxy sets, and then transferred the learned architectures to larger datasets by replicating or stacking the searched cells. We propose a NAS method based on polyharmonic splines that can perform search directly on large scale, imbalanced target datasets. We demonstrate the effectiveness of our method on the ImageNet22K benchmark[16], which contains 14 million images distributed in a highly imbalanced manner over 21,841 categories. By exploring the search space of the ResNet [23] and Big-Little Net ResNext [11] architectures directly on ImageNet22K, our polyharmonic splines NAS method designed a model which achieved a top-1 accuracy of 40.03% on ImageNet22K, an absolute improvement of 3.13% over the state of the art with similar global batch size [15].
NASTransfer: Analyzing Architecture Transferability in Large Scale Neural Architecture Search
Jun 23, 2020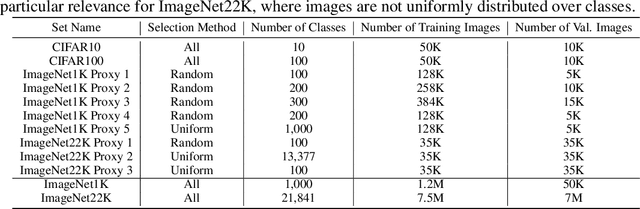
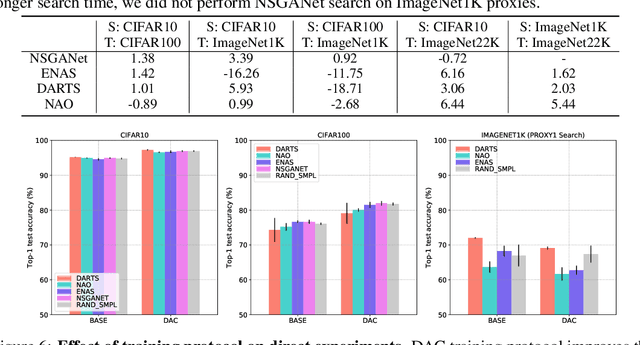
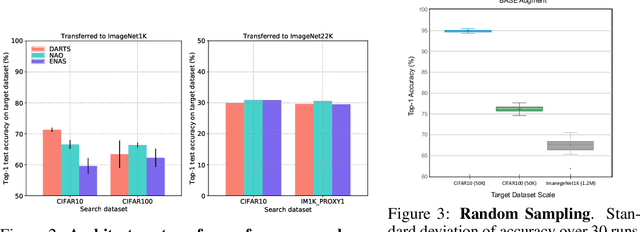
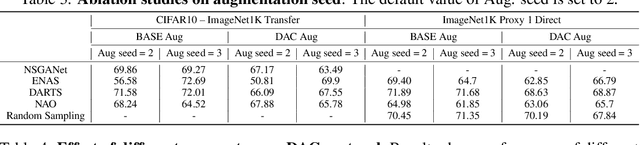
Neural Architecture Search (NAS) is an open and challenging problem in machine learning. While NAS offers great promise, the prohibitive computational demand of most of the existing NAS methods makes it difficult to directly search the architectures on large-scale tasks. The typical way of conducting large scale NAS is to search for an architectural building block on a small dataset (either using a proxy set from the large dataset or a completely different small scale dataset) and then transfer the block to a larger dataset. Despite a number of recent results that show the promise of transfer from proxy datasets, a comprehensive evaluation of different NAS methods studying the impact of different source datasets and training protocols has not yet been addressed. In this work, we propose to analyze the architecture transferability of different NAS methods by performing a series of experiments on large scale benchmarks such as ImageNet1K and ImageNet22K. We find that: (i) On average, transfer performance of architectures searched using completely different small datasets perform similarly to the architectures searched directly on proxy target datasets. However, design of proxy sets has considerable impact on rankings of different NAS methods. (ii) While the different NAS methods show similar performance on a source dataset (e.g., CIFAR10), they significantly differ on the transfer performance to a large dataset (e.g., ImageNet1K). (iii) Even on large datasets, the randomly sampled architecture baseline is very competitive and significantly outperforms many representative NAS methods. (iv) The training protocol has a larger impact on small datasets, but it fails to provide consistent improvements on large datasets. We believe that our NASTransfer benchmark will be key to designing future NAS strategies that consistently show superior transfer performance on large scale datasets.
Covering the News with (AI) Style
Jan 05, 2020



We introduce a multi-modal discriminative and generative frame-work capable of assisting humans in producing visual content re-lated to a given theme, starting from a collection of documents(textual, visual, or both). This framework can be used by edit or to generate images for articles, as well as books or music album covers. Motivated by a request from the The New York Times (NYT) seeking help to use AI to create art for their special section on Artificial Intelligence, we demonstrated the application of our system in producing such image.
Diversity in Faces
Jan 30, 2019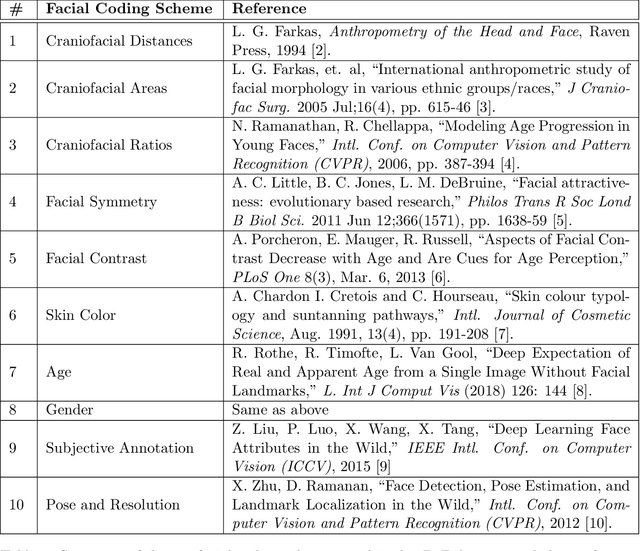
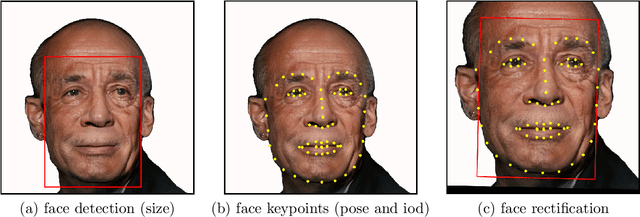
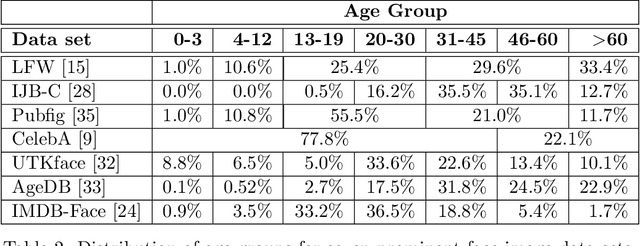
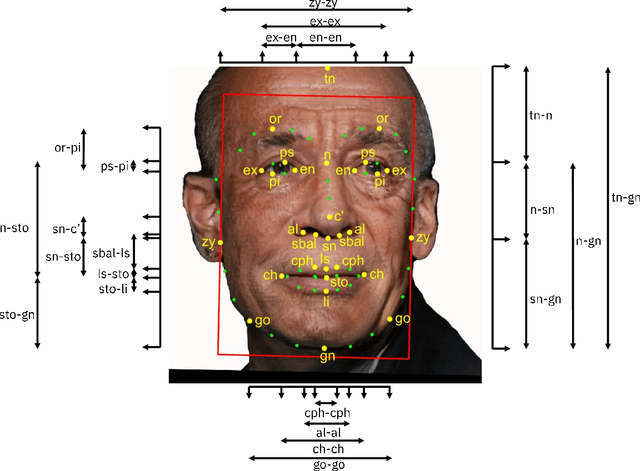
Face recognition is a long standing challenge in the field of Artificial Intelligence (AI). The goal is to create systems that accurately detect, recognize, verify, and understand human faces. There are significant technical hurdles in making these systems accurate, particularly in unconstrained settings due to confounding factors related to pose, resolution, illumination, occlusion, and viewpoint. However, with recent advances in neural networks, face recognition has achieved unprecedented accuracy, largely built on data-driven deep learning methods. While this is encouraging, a critical aspect that is limiting facial recognition accuracy and fairness is inherent facial diversity. Every face is different. Every face reflects something unique about us. Aspects of our heritage - including race, ethnicity, culture, geography - and our individual identify - age, gender, and other visible manifestations of self-expression, are reflected in our faces. We expect face recognition to work equally accurately for every face. Face recognition needs to be fair. As we rely on data-driven methods to create face recognition technology, we need to ensure necessary balance and coverage in training data. However, there are still scientific questions about how to represent and extract pertinent facial features and quantitatively measure facial diversity. Towards this goal, Diversity in Faces (DiF) provides a data set of one million annotated human face images for advancing the study of facial diversity. The annotations are generated using ten well-established facial coding schemes from the scientific literature. The facial coding schemes provide human-interpretable quantitative measures of facial features. We believe that by making the extracted coding schemes available on a large set of faces, we can accelerate research and development towards creating more fair and accurate facial recognition systems.
Automatic Curation of Golf Highlights using Multimodal Excitement Features
Jul 22, 2017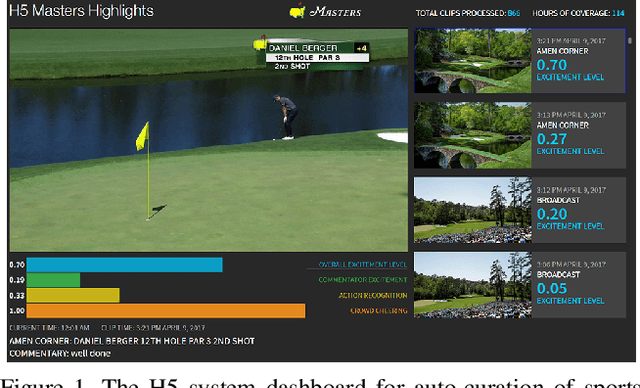

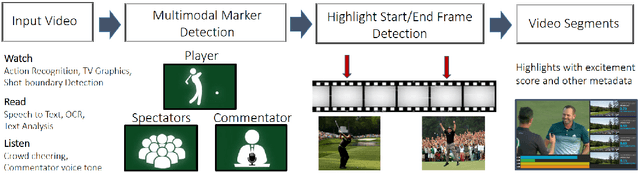
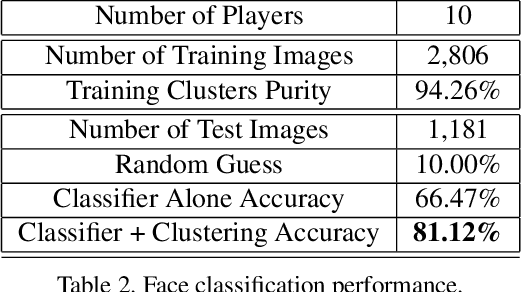
The production of sports highlight packages summarizing a game's most exciting moments is an essential task for broadcast media. Yet, it requires labor-intensive video editing. We propose a novel approach for auto-curating sports highlights, and use it to create a real-world system for the editorial aid of golf highlight reels. Our method fuses information from the players' reactions (action recognition such as high-fives and fist pumps), spectators (crowd cheering), and commentator (tone of the voice and word analysis) to determine the most interesting moments of a game. We accurately identify the start and end frames of key shot highlights with additional metadata, such as the player's name and the hole number, allowing personalized content summarization and retrieval. In addition, we introduce new techniques for learning our classifiers with reduced manual training data annotation by exploiting the correlation of different modalities. Our work has been demonstrated at a major golf tournament, successfully extracting highlights from live video streams over four consecutive days.