 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unseen Threat: Residual Knowledge in Machine Unlearning under Perturbed Samples
Jan 29, 2026Machine unlearning offers a practical alternative to avoid full model re-training by approximately removing the influence of specific user data. While existing methods certify unlearning via statistical indistinguishability from re-trained models, these guarantees do not naturally extend to model outputs when inputs are adversarially perturbed. In particular, slight perturbations of forget samples may still be correctly recognized by the unlearned model - even when a re-trained model fails to do so - revealing a novel privacy risk: information about the forget samples may persist in their local neighborhood. In this work, we formalize this vulnerability as residual knowledge and show that it is inevitable in high-dimensional settings. To mitigate this risk, we propose a fine-tuning strategy, named RURK, that penalizes the model's ability to re-recognize perturbed forget samples. Experiments on vision benchmarks with deep neural networks demonstrate that residual knowledge is prevalent across existing unlearning methods and that our approach effectively prevents residual knowledge.
A Numerical Gradient Inversion Attack in Variational Quantum Neural-Networks
Apr 17, 2025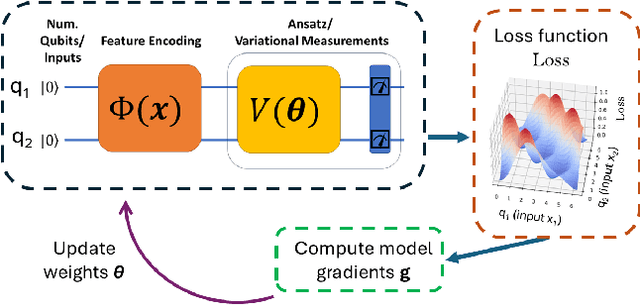
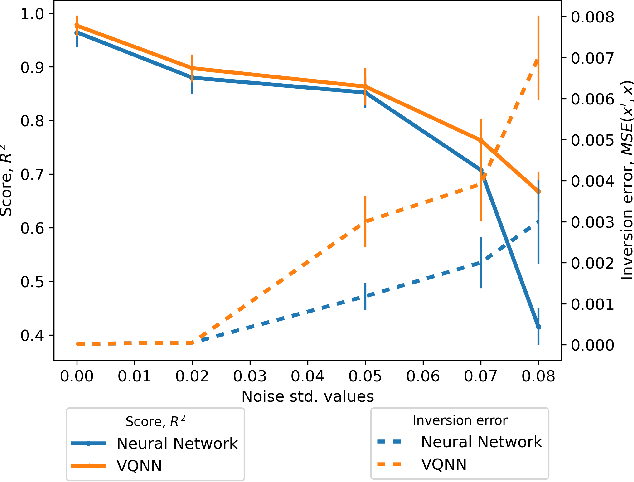
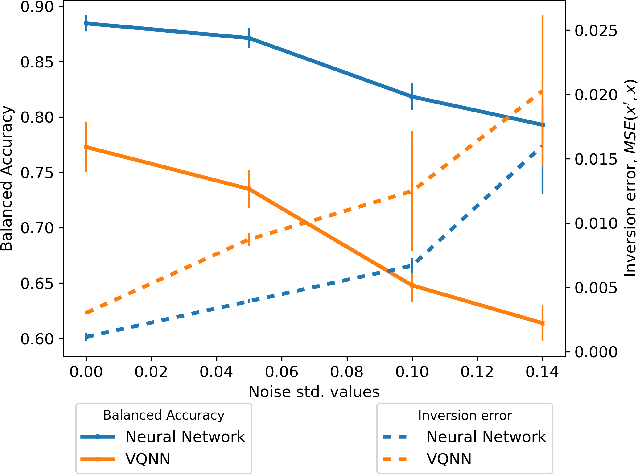
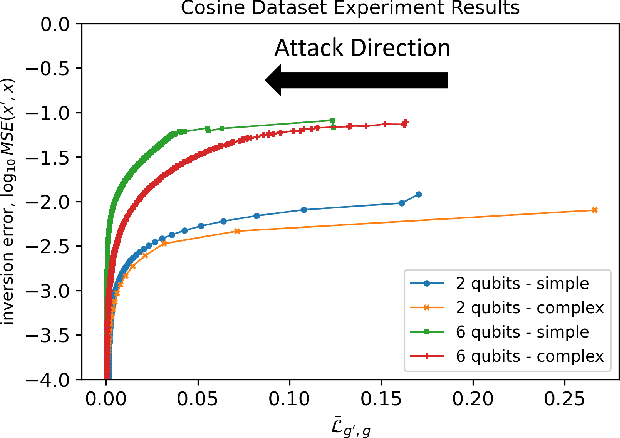
The loss landscape of Variational Quantum Neural Networks (VQNNs) is characterized by local minima that grow exponentially with increasing qubits. Because of this, it is more challenging to recover information from model gradients during training compared to classical Neural Networks (NNs). In this paper we present a numerical scheme that successfully reconstructs input training, real-world, practical data from trainable VQNNs' gradients. Our scheme is based on gradient inversion that works by combining gradients estimation with the finite difference method and adaptive low-pass filtering. The scheme is further optimized with Kalman filter to obtain efficient convergence. Our experiments show that our algorithm can invert even batch-trained data, given the VQNN model is sufficiently over-parameterized.
LLM Hallucination Reasoning with Zero-shot Knowledge Test
Nov 14, 2024LLM hallucination, where LLMs occasionally generate unfaithful text, poses significant challenges for their practical applications. Most existing detection methods rely on external knowledge, LLM fine-tuning, or hallucination-labeled datasets, and they do not distinguish between different types of hallucinations, which are crucial for improving detection performance. We introduce a new task, Hallucination Reasoning, which classifies LLM-generated text into one of three categories: aligned, misaligned, and fabricated. Our novel zero-shot method assesses whether LLM has enough knowledge about a given prompt and text. Our experiments conducted on new datasets demonstrate the effectiveness of our method in hallucination reasoning and underscore its importance for enhancing detection performance.
Model-Agnostic Utility-Preserving Biometric Information Anonymization
May 23, 2024The recent rapid advancements in both sensing and machine learning technologies have given rise to the universal collection and utilization of people's biometrics, such as fingerprints, voices, retina/facial scans, or gait/motion/gestures data, enabling a wide range of applications including authentication, health monitoring, or much more sophisticated analytics. While providing better user experiences and deeper business insights, the use of biometrics has raised serious privacy concerns due to their intrinsic sensitive nature and the accompanying high risk of leaking sensitive information such as identity or medical conditions. In this paper, we propose a novel modality-agnostic data transformation framework that is capable of anonymizing biometric data by suppressing its sensitive attributes and retaining features relevant to downstream machine learning-based analyses that are of research and business values. We carried out a thorough experimental evaluation using publicly available facial, voice, and motion datasets. Results show that our proposed framework can achieve a \highlight{high suppression level for sensitive information}, while at the same time retain underlying data utility such that subsequent analyses on the anonymized biometric data could still be carried out to yield satisfactory accuracy.
OVOR: OnePrompt with Virtual Outlier Regularization for Rehearsal-Free Class-Incremental Learning
Feb 06, 2024Recent works have shown that by using large pre-trained models along with learnable prompts, rehearsal-free methods for class-incremental learning (CIL) settings can achieve superior performance to prominent rehearsal-based ones. Rehearsal-free CIL methods struggle with distinguishing classes from different tasks, as those are not trained together. In this work we propose a regularization method based on virtual outliers to tighten decision boundaries of the classifier, such that confusion of classes among different tasks is mitigated. Recent prompt-based methods often require a pool of task-specific prompts, in order to prevent overwriting knowledge of previous tasks with that of the new task, leading to extra computation in querying and composing an appropriate prompt from the pool. This additional cost can be eliminated, without sacrificing accuracy, as we reveal in the paper. We illustrate that a simplified prompt-based method can achieve results comparable to previous state-of-the-art (SOTA) methods equipped with a prompt pool, using much less learnable parameters and lower inference cost. Our regularization method has demonstrated its compatibility with different prompt-based methods, boosting those previous SOTA rehearsal-free CIL methods' accuracy on the ImageNet-R and CIFAR-100 benchmarks. Our source code is available at https://github.com/jpmorganchase/ovor.
Machine Unlearning for Image-to-Image Generative Models
Feb 02, 2024
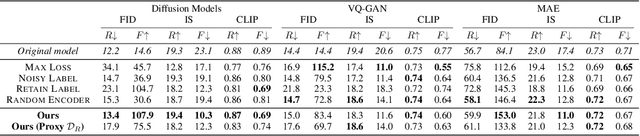
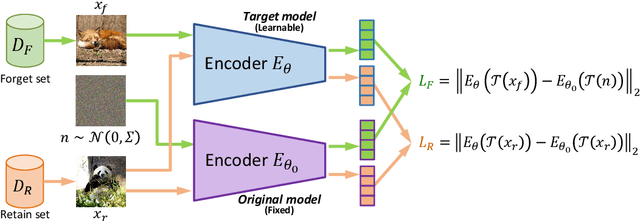
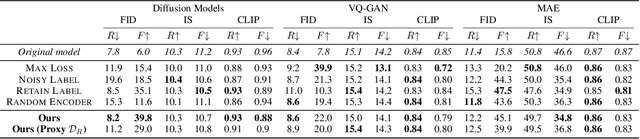
Machine unlearning has emerged as a new paradigm to deliberately forget data samples from a given model in order to adhere to stringent regulations. However, existing machine unlearning methods have been primarily focused on classification models, leaving the landscape of unlearning for generative models relatively unexplored. This paper serves as a bridge, addressing the gap by providing a unifying framework of machine unlearning for image-to-image generative models. Within this framework, we propose a computationally-efficient algorithm, underpinned by rigorous theoretical analysis, that demonstrates negligible performance degradation on the retain samples, while effectively removing the information from the forget samples. Empirical studies on two large-scale datasets, ImageNet-1K and Places-365, further show that our algorithm does not rely on the availability of the retain samples, which further complies with data retention policy. To our best knowledge, this work is the first that represents systemic, theoretical, empirical explorations of machine unlearning specifically tailored for image-to-image generative models. Our code is available at https://github.com/jpmorganchase/l2l-generator-unlearning.
Fast-NTK: Parameter-Efficient Unlearning for Large-Scale Models
Dec 22, 2023The rapid growth of machine learning has spurred legislative initiatives such as ``the Right to be Forgotten,'' allowing users to request data removal. In response, ``machine unlearning'' proposes the selective removal of unwanted data without the need for retraining from scratch. While the Neural-Tangent-Kernel-based (NTK-based) unlearning method excels in performance, it suffers from significant computational complexity, especially for large-scale models and datasets. Our work introduces ``Fast-NTK,'' a novel NTK-based unlearning algorithm that significantly reduces the computational complexity by incorporating parameter-efficient fine-tuning methods, such as fine-tuning batch normalization layers in a CNN or visual prompts in a vision transformer. Our experimental results demonstrate scalability to much larger neural networks and datasets (e.g., 88M parameters; 5k images), surpassing the limitations of previous full-model NTK-based approaches designed for smaller cases (e.g., 8M parameters; 500 images). Notably, our approach maintains a performance comparable to the traditional method of retraining on the retain set alone. Fast-NTK can thus enable for practical and scalable NTK-based unlearning in deep neural networks.
Procedural Image Programs for Representation Learning
Nov 29, 2022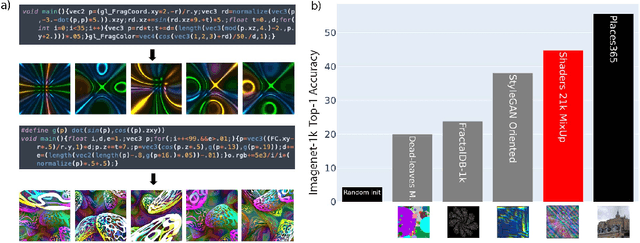
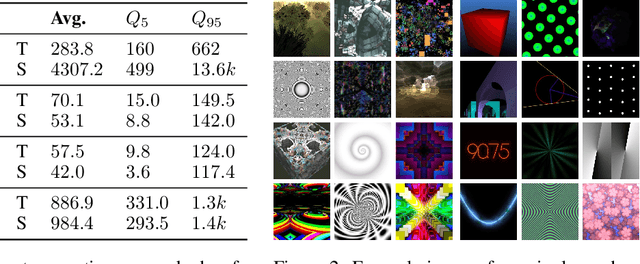
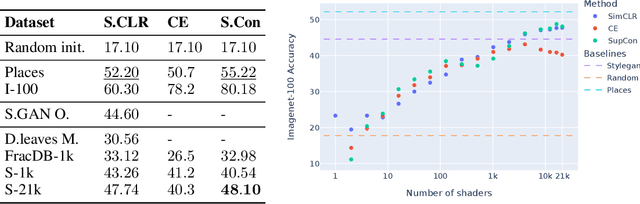
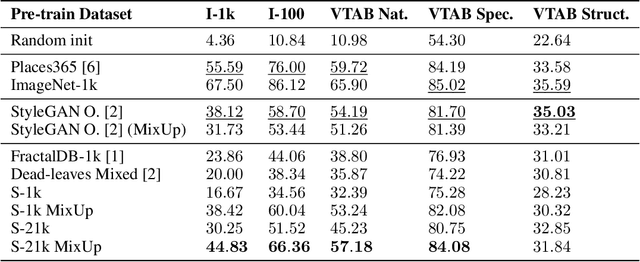
Learning image representations using synthetic data allows training neural networks without some of the concerns associated with real images, such as privacy and bias. Existing work focuses on a handful of curated generative processes which require expert knowledge to design, making it hard to scale up. To overcome this, we propose training with a large dataset of twenty-one thousand programs, each one generating a diverse set of synthetic images. These programs are short code snippets, which are easy to modify and fast to execute using OpenGL. The proposed dataset can be used for both supervised and unsupervised representation learning, and reduces the gap between pre-training with real and procedurally generated images by 38%.
* 29 pages, Accepted in the Conference on Neural Information Processing Systems 2022 (NeurIPS 2022)
MaSS: Multi-attribute Selective Suppression
Oct 18, 2022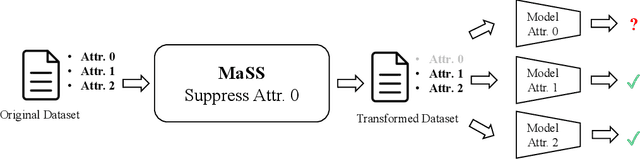

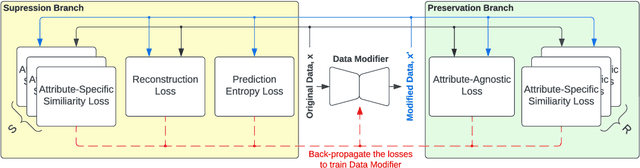
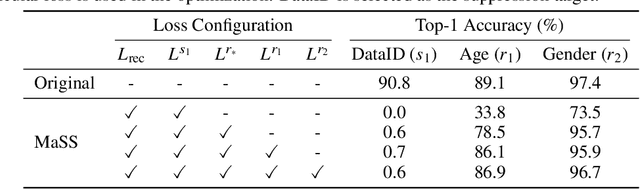
The recent rapid advances in machine learning technologies largely depend on the vast richness of data available today, in terms of both the quantity and the rich content contained within. For example, biometric data such as images and voices could reveal people's attributes like age, gender, sentiment, and origin, whereas location/motion data could be used to infer people's activity levels, transportation modes, and life habits. Along with the new services and applications enabled by such technological advances, various governmental policies are put in place to regulate such data usage and protect people's privacy and rights. As a result, data owners often opt for simple data obfuscation (e.g., blur people's faces in images) or withholding data altogether, which leads to severe data quality degradation and greatly limits the data's potential utility. Aiming for a sophisticated mechanism which gives data owners fine-grained control while retaining the maximal degree of data utility, we propose Multi-attribute Selective Suppression, or MaSS, a general framework for performing precisely targeted data surgery to simultaneously suppress any selected set of attributes while preserving the rest for downstream machine learning tasks. MaSS learns a data modifier through adversarial games between two sets of networks, where one is aimed at suppressing selected attributes, and the other ensures the retention of the rest of the attributes via general contrastive loss as well as explicit classification metrics. We carried out an extensive evaluation of our proposed method using multiple datasets from different domains including facial images, voice audio, and video clips, and obtained promising results in MaSS' generalizability and capability of suppressing targeted attributes without negatively affecting the data's usability in other downstream ML tasks.
Task2Sim : Towards Effective Pre-training and Transfer from Synthetic Data
Nov 30, 2021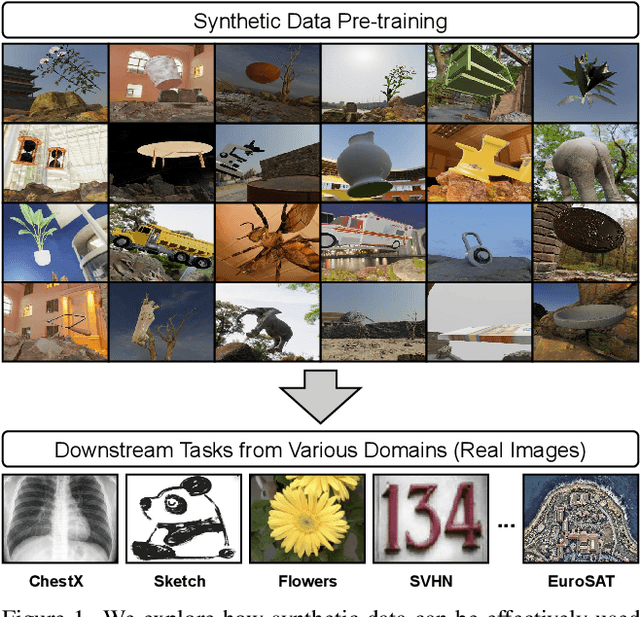
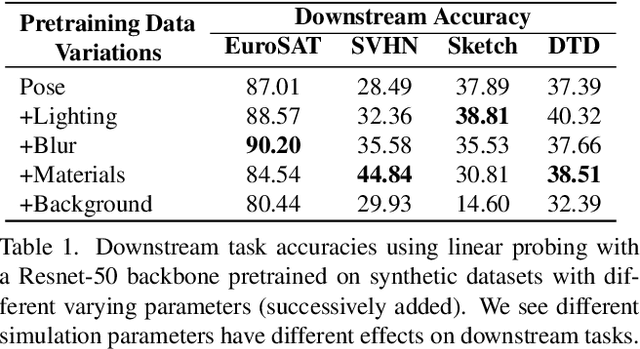
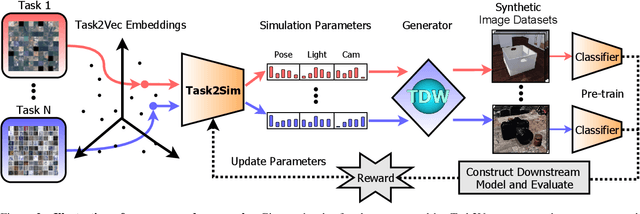
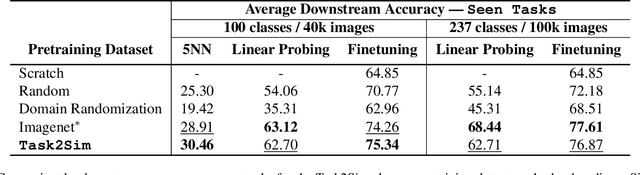
Pre-training models on Imagenet or other massive datasets of real images has led to major advances in computer vision, albeit accompanied with shortcomings related to curation cost, privacy, usage rights, and ethical issues. In this paper, for the first time, we study the transferability of pre-trained models based on synthetic data generated by graphics simulators to downstream tasks from very different domains. In using such synthetic data for pre-training, we find that downstream performance on different tasks are favored by different configurations of simulation parameters (e.g. lighting, object pose, backgrounds, etc.), and that there is no one-size-fits-all solution. It is thus better to tailor synthetic pre-training data to a specific downstream task, for best performance. We introduce Task2Sim, a unified model mapping downstream task representations to optimal simulation parameters to generate synthetic pre-training data for them. Task2Sim learns this mapping by training to find the set of best parameters on a set of "seen" tasks. Once trained, it can then be used to predict best simulation parameters for novel "unseen" tasks in one shot, without requiring additional training. Given a budget in number of images per class, our extensive experiments with 20 diverse downstream tasks show Task2Sim's task-adaptive pre-training data results in significantly better downstream performance than non-adaptively choosing simulation parameters on both seen and unseen tasks. It is even competitive with pre-training on real images from Imagenet.