 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Numerical Gradient Inversion Attack in Variational Quantum Neural-Networks
Apr 17, 2025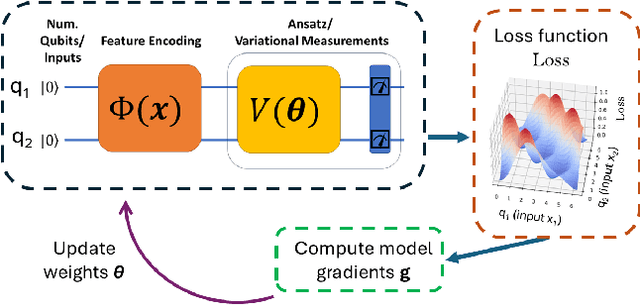
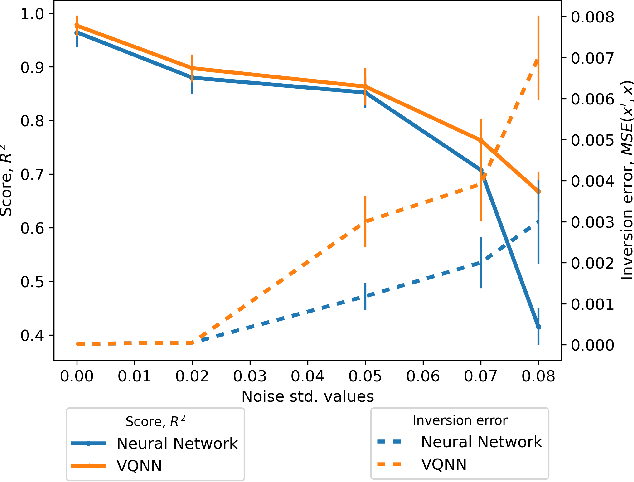
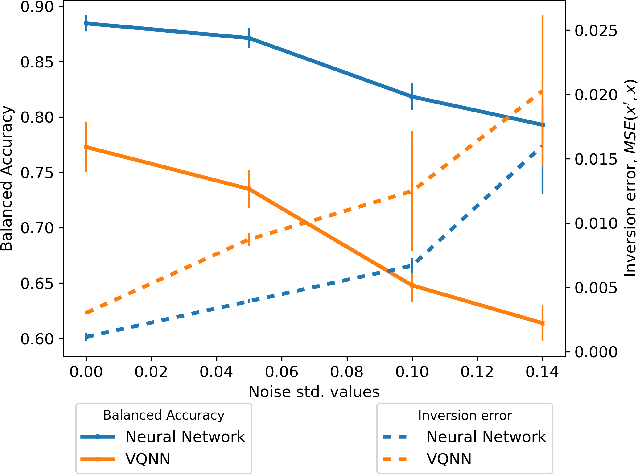
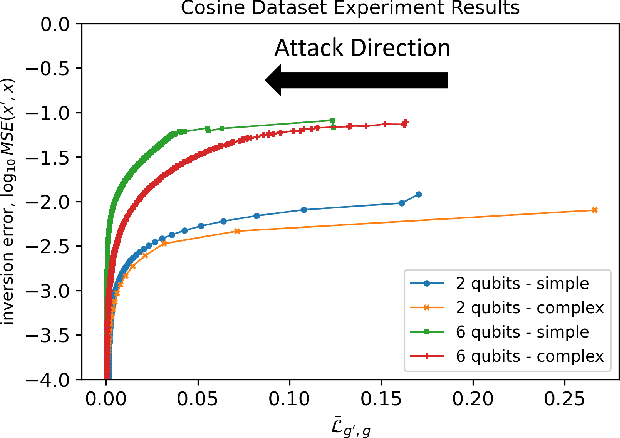
The loss landscape of Variational Quantum Neural Networks (VQNNs) is characterized by local minima that grow exponentially with increasing qubits. Because of this, it is more challenging to recover information from model gradients during training compared to classical Neural Networks (NNs). In this paper we present a numerical scheme that successfully reconstructs input training, real-world, practical data from trainable VQNNs' gradients. Our scheme is based on gradient inversion that works by combining gradients estimation with the finite difference method and adaptive low-pass filtering. The scheme is further optimized with Kalman filter to obtain efficient convergence. Our experiments show that our algorithm can invert even batch-trained data, given the VQNN model is sufficiently over-parameterized.
An Unsupervised Method for Estimating Class Separability of Datasets with Application to LLMs Fine-Tuning
May 24, 2023
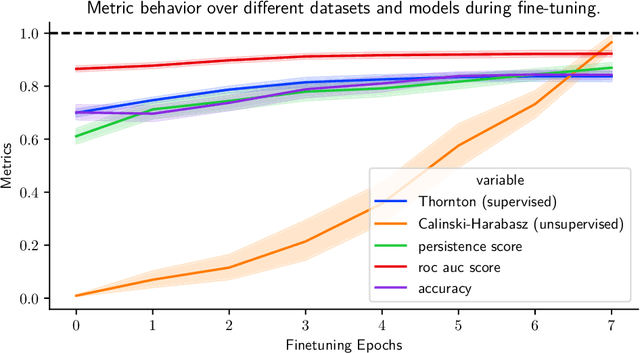


This paper proposes an unsupervised method that leverages topological characteristics of data manifolds to estimate class separability of the data without requiring labels. Experiments conducted in this paper on several datasets demonstrate a clear correlation and consistency between the class separability estimated by the proposed method with supervised metrics like Fisher Discriminant Ratio~(FDR) and cross-validation of a classifier, which both require labels. This can enable implementing learning paradigms aimed at learning from both labeled and unlabeled data, like semi-supervised and transductive learning. This would be particularly useful when we have limited labeled data and a relatively large unlabeled dataset that can be used to enhance the learning process. The proposed method is implemented for language model fine-tuning with automated stopping criterion by monitoring class separability of the embedding-space manifold in an unsupervised setting. The proposed methodology has been first validated on synthetic data, where the results show a clear consistency between class separability estimated by the proposed method and class separability computed by FDR. The method has been also implemented on both public and internal data. The results show that the proposed method can effectively aid -- without the need for labels -- a decision on when to stop or continue the fine-tuning of a language model and which fine-tuning iteration is expected to achieve a maximum classification performance through quantification of the class separability of the embedding manifold.
Bandit-Based Policy Invariant Explicit Shaping for Incorporating External Advice in Reinforcement Learning
Apr 14, 2023A key challenge for a reinforcement learning (RL) agent is to incorporate external/expert1 advice in its learning. The desired goals of an algorithm that can shape the learning of an RL agent with external advice include (a) maintaining policy invariance; (b) accelerating the learning of the agent; and (c) learning from arbitrary advice [3]. To address this challenge this paper formulates the problem of incorporating external advice in RL as a multi-armed bandit called shaping-bandits. The reward of each arm of shaping bandits corresponds to the return obtained by following the expert or by following a default RL algorithm learning on the true environment reward.We show that directly applying existing bandit and shaping algorithms that do not reason about the non-stationary nature of the underlying returns can lead to poor results. Thus we propose UCB-PIES (UPIES), Racing-PIES (RPIES), and Lazy PIES (LPIES) three different shaping algorithms built on different assumptions that reason about the long-term consequences of following the expert policy or the default RL algorithm. Our experiments in four different settings show that these proposed algorithms achieve the above-mentioned goals whereas the other algorithms fail to do so.
Topical: Learning Repository Embeddings from Source Code using Attention
Aug 19, 2022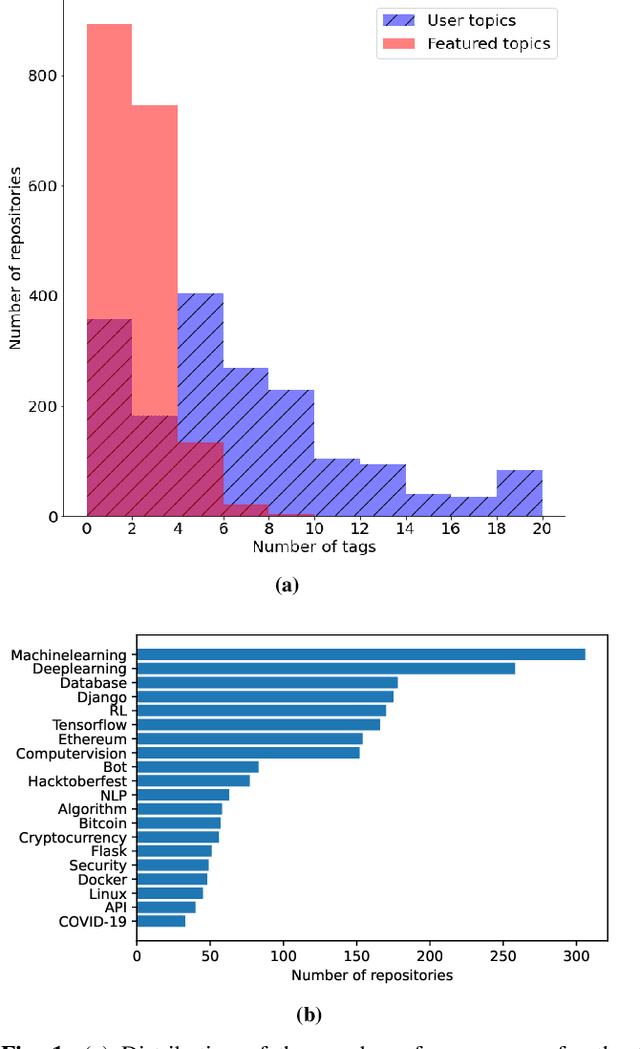
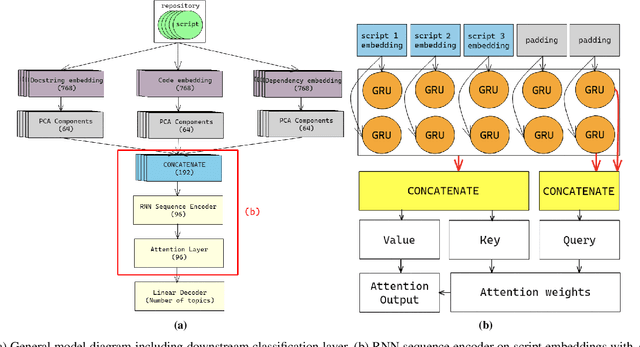

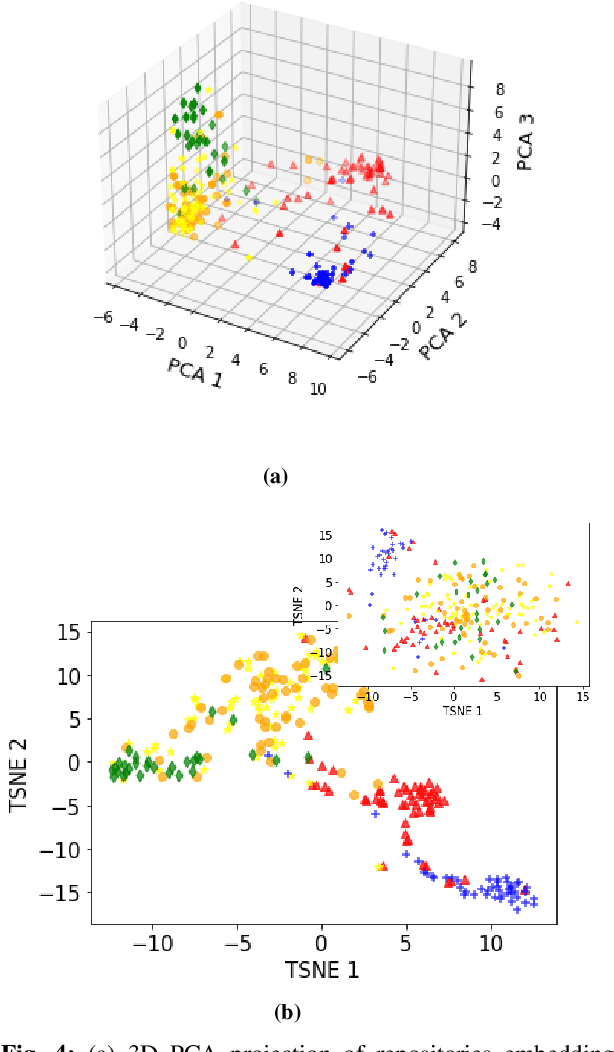
Machine learning on source code (MLOnCode) promises to transform how software is delivered. By mining the context and relationship between software artefacts, MLOnCode augments the software developers capabilities with code auto-generation, code recommendation, code auto-tagging and other data-driven enhancements. For many of these tasks a script level representation of code is sufficient, however, in many cases a repository level representation that takes into account various dependencies and repository structure is imperative, for example, auto-tagging repositories with topics or auto-documentation of repository code etc. Existing methods for computing repository level representations suffer from (a) reliance on natural language documentation of code (for example, README files) (b) naive aggregation of method/script-level representation, for example, by concatenation or averaging. This paper introduces Topical a deep neural network to generate repository level embeddings of publicly available GitHub code repositories directly from source code. Topical incorporates an attention mechanism that projects the source code, the full dependency graph and the script level textual information into a dense repository-level representation. To compute the repository-level representations, Topical is trained to predict the topics associated with a repository, on a dataset of publicly available GitHub repositories that were crawled along with their ground truth topic tags. Our experiments show that the embeddings computed by Topical are able to outperform multiple baselines, including baselines that naively combine the method-level representations through averaging or concatenation at the task of repository auto-tagging.
Learning to Be Cautious
Oct 29, 2021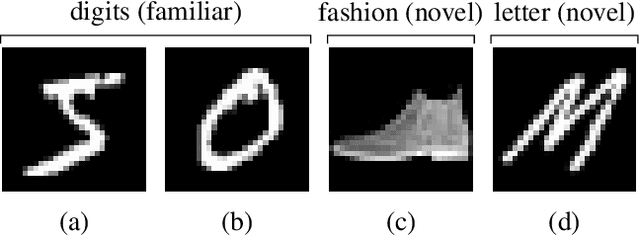


A key challenge in the field of reinforcement learning is to develop agents that behave cautiously in novel situations. It is generally impossible to anticipate all situations that an autonomous system may face or what behavior would best avoid bad outcomes. An agent that could learn to be cautious would overcome this challenge by discovering for itself when and how to behave cautiously. In contrast, current approaches typically embed task-specific safety information or explicit cautious behaviors into the system, which is error-prone and imposes extra burdens on practitioners. In this paper, we present both a sequence of tasks where cautious behavior becomes increasingly non-obvious, as well as an algorithm to demonstrate that it is possible for a system to \emph{learn} to be cautious. The essential features of our algorithm are that it characterizes reward function uncertainty without task-specific safety information and uses this uncertainty to construct a robust policy. Specifically, we construct robust policies with a $k$-of-$N$ counterfactual regret minimization (CFR) subroutine given a learned reward function uncertainty represented by a neural network ensemble belief. These policies exhibit caution in each of our tasks without any task-specific safety tuning.
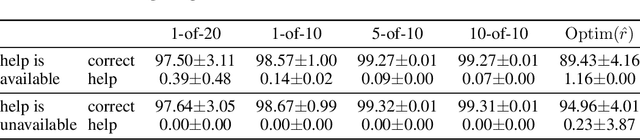
Useful Policy Invariant Shaping from Arbitrary Advice
Nov 02, 2020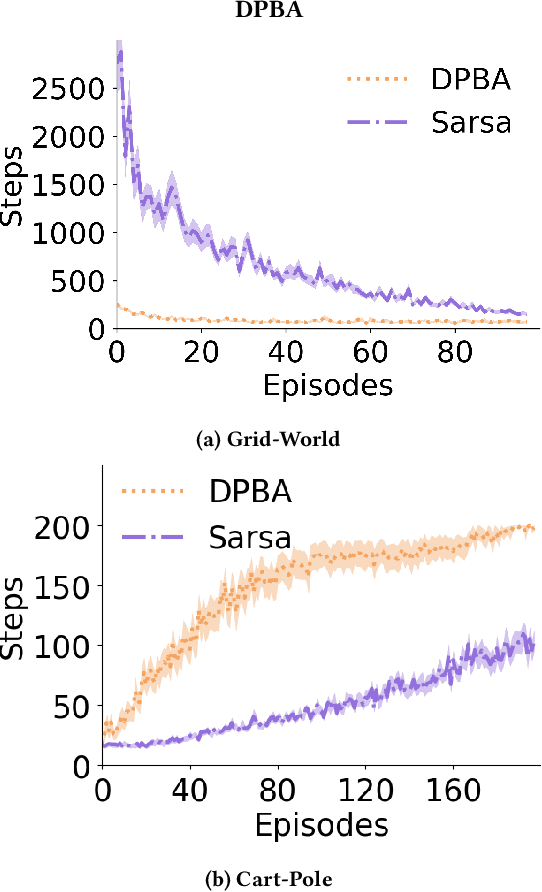

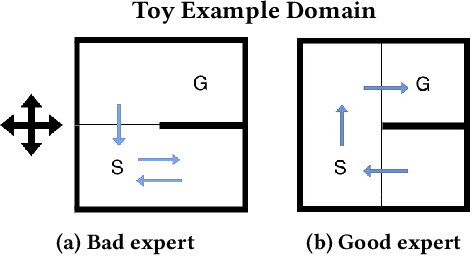

Reinforcement learning is a powerful learning paradigm in which agents can learn to maximize sparse and delayed reward signals. Although RL has had many impressive successes in complex domains, learning can take hours, days, or even years of training data. A major challenge of contemporary RL research is to discover how to learn with less data. Previous work has shown that domain information can be successfully used to shape the reward; by adding additional reward information, the agent can learn with much less data. Furthermore, if the reward is constructed from a potential function, the optimal policy is guaranteed to be unaltered. While such potential-based reward shaping (PBRS) holds promise, it is limited by the need for a well-defined potential function. Ideally, we would like to be able to take arbitrary advice from a human or other agent and improve performance without affecting the optimal policy. The recently introduced dynamic potential based advice (DPBA) method tackles this challenge by admitting arbitrary advice from a human or other agent and improves performance without affecting the optimal policy. The main contribution of this paper is to expose, theoretically and empirically, a flaw in DPBA. Alternatively, to achieve the ideal goals, we present a simple method called policy invariant explicit shaping (PIES) and show theoretically and empirically that PIES succeeds where DPBA fails.
Exploiting Submodular Value Functions For Scaling Up Active Perception
Sep 21, 2020
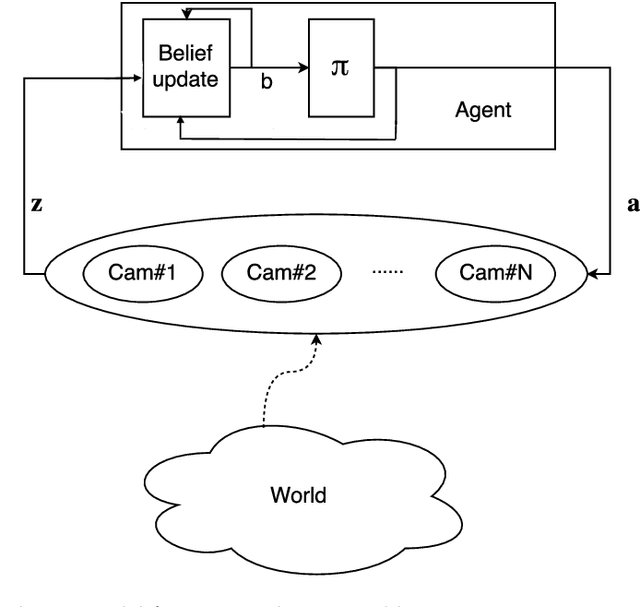
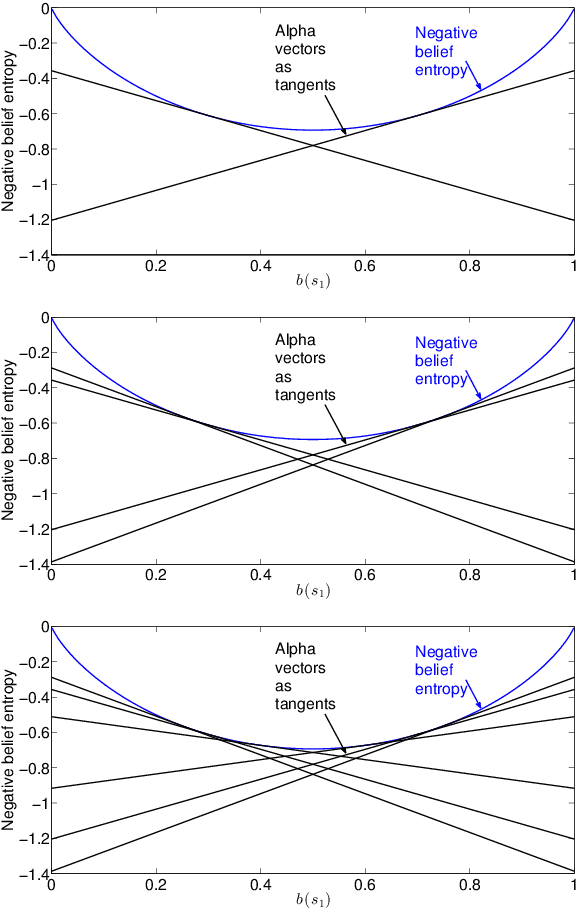
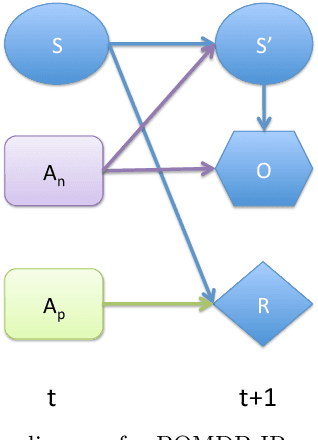
In active perception tasks, an agent aims to select sensory actions that reduce its uncertainty about one or more hidden variables. While partially observable Markov decision processes (POMDPs) provide a natural model for such problems, reward functions that directly penalize uncertainty in the agent's belief can remove the piecewise-linear and convex property of the value function required by most POMDP planners. Furthermore, as the number of sensors available to the agent grows, the computational cost of POMDP planning grows exponentially with it, making POMDP planning infeasible with traditional methods. In this article, we address a twofold challenge of modeling and planning for active perception tasks. We show the mathematical equivalence of $\rho$POMDP and POMDP-IR, two frameworks for modeling active perception tasks, that restore the PWLC property of the value function. To efficiently plan for active perception tasks, we identify and exploit the independence properties of POMDP-IR to reduce the computational cost of solving POMDP-IR (and $\rho$POMDP). We propose greedy point-based value iteration (PBVI), a new POMDP planning method that uses greedy maximization to greatly improve scalability in the action space of an active perception POMDP. Furthermore, we show that, under certain conditions, including submodularity, the value function computed using greedy PBVI is guaranteed to have bounded error with respect to the optimal value function. We establish the conditions under which the value function of an active perception POMDP is guaranteed to be submodular. Finally, we present a detailed empirical analysis on a dataset collected from a multi-camera tracking system employed in a shopping mall. Our method achieves similar performance to existing methods but at a fraction of the computational cost leading to better scalability for solving active perception tasks.
Real-Time Resource Allocation for Tracking Systems
Sep 21, 2020
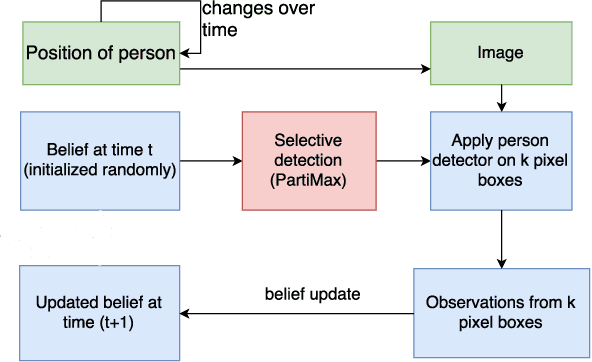

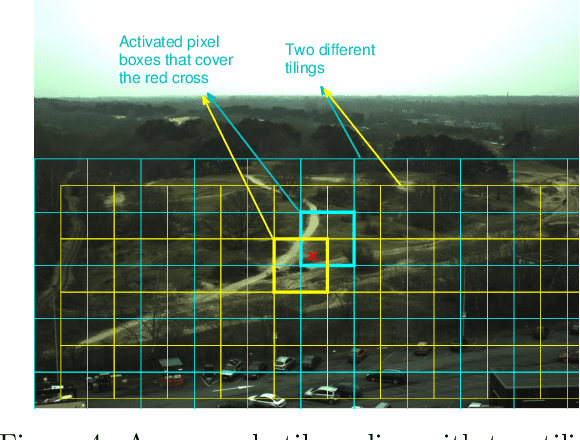
Automated tracking is key to many computer vision applications. However, many tracking systems struggle to perform in real-time due to the high computational cost of detecting people, especially in ultra high resolution images. We propose a new algorithm called \emph{PartiMax} that greatly reduces this cost by applying the person detector only to the relevant parts of the image. PartiMax exploits information in the particle filter to select $k$ of the $n$ candidate \emph{pixel boxes} in the image. We prove that PartiMax is guaranteed to make a near-optimal selection with error bounds that are independent of the problem size. Furthermore, empirical results on a real-life dataset show that our system runs in real-time by processing only 10\% of the pixel boxes in the image while still retaining 80\% of the original tracking performance achieved when processing all pixel boxes.
* http://auai.org/uai2017/proceedings/papers/130.pdf
Maximizing Information Gain in Partially Observable Environments via Prediction Reward
May 11, 2020
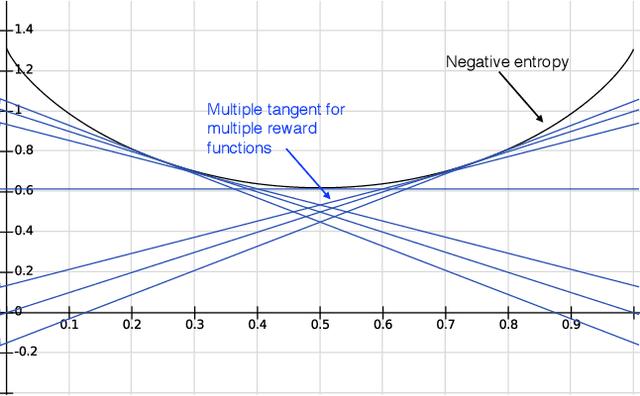
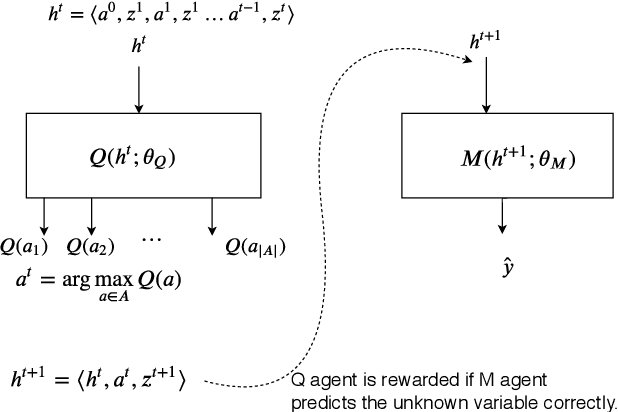
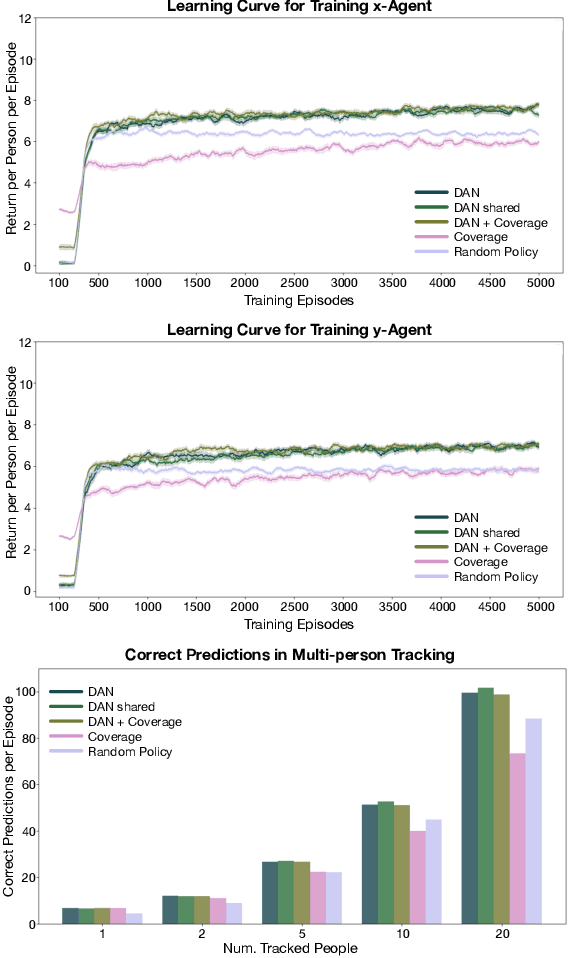
Information gathering in a partially observable environment can be formulated as a reinforcement learning (RL), problem where the reward depends on the agent's uncertainty. For example, the reward can be the negative entropy of the agent's belief over an unknown (or hidden) variable. Typically, the rewards of an RL agent are defined as a function of the state-action pairs and not as a function of the belief of the agent; this hinders the direct application of deep RL methods for such tasks. This paper tackles the challenge of using belief-based rewards for a deep RL agent, by offering a simple insight that maximizing any convex function of the belief of the agent can be approximated by instead maximizing a prediction reward: a reward based on prediction accuracy. In particular, we derive the exact error between negative entropy and the expected prediction reward. This insight provides theoretical motivation for several fields using prediction rewards---namely visual attention, question answering systems, and intrinsic motivation---and highlights their connection to the usually distinct fields of active perception, active sensing, and sensor placement. Based on this insight we present deep anticipatory networks (DANs), which enables an agent to take actions to reduce its uncertainty without performing explicit belief inference. We present two applications of DANs: building a sensor selection system for tracking people in a shopping mall and learning discrete models of attention on fashion MNIST and MNIST digit classification.
Probably Approximately Correct Greedy Maximization
Feb 25, 2016
Submodular function maximization finds application in a variety of real-world decision-making problems. However, most existing methods, based on greedy maximization, assume it is computationally feasible to evaluate F, the function being maximized. Unfortunately, in many realistic settings F is too expensive to evaluate exactly even once. We present probably approximately correct greedy maximization, which requires access only to cheap anytime confidence bounds on F and uses them to prune elements. We show that, with high probability, our method returns an approximately optimal set. We propose novel, cheap confidence bounds for conditional entropy, which appears in many common choices of F and for which it is difficult to find unbiased or bounded estimates. Finally, results on a real-world dataset from a multi-camera tracking system in a shopping mall demonstrate that our approach performs comparably to existing methods, but at a fraction of the computational cost.