 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Be Cautious
Oct 29, 2021


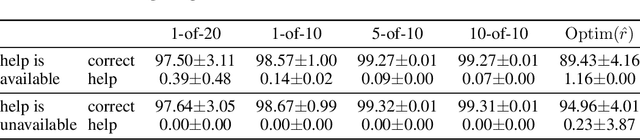
A key challenge in the field of reinforcement learning is to develop agents that behave cautiously in novel situations. It is generally impossible to anticipate all situations that an autonomous system may face or what behavior would best avoid bad outcomes. An agent that could learn to be cautious would overcome this challenge by discovering for itself when and how to behave cautiously. In contrast, current approaches typically embed task-specific safety information or explicit cautious behaviors into the system, which is error-prone and imposes extra burdens on practitioners. In this paper, we present both a sequence of tasks where cautious behavior becomes increasingly non-obvious, as well as an algorithm to demonstrate that it is possible for a system to \emph{learn} to be cautious. The essential features of our algorithm are that it characterizes reward function uncertainty without task-specific safety information and uses this uncertainty to construct a robust policy. Specifically, we construct robust policies with a $k$-of-$N$ counterfactual regret minimization (CFR) subroutine given a learned reward function uncertainty represented by a neural network ensemble belief. These policies exhibit caution in each of our tasks without any task-specific safety tuning.
Explaining Deep Reinforcement Learning Agents In The Atari Domain through a Surrogate Model
Oct 07, 2021


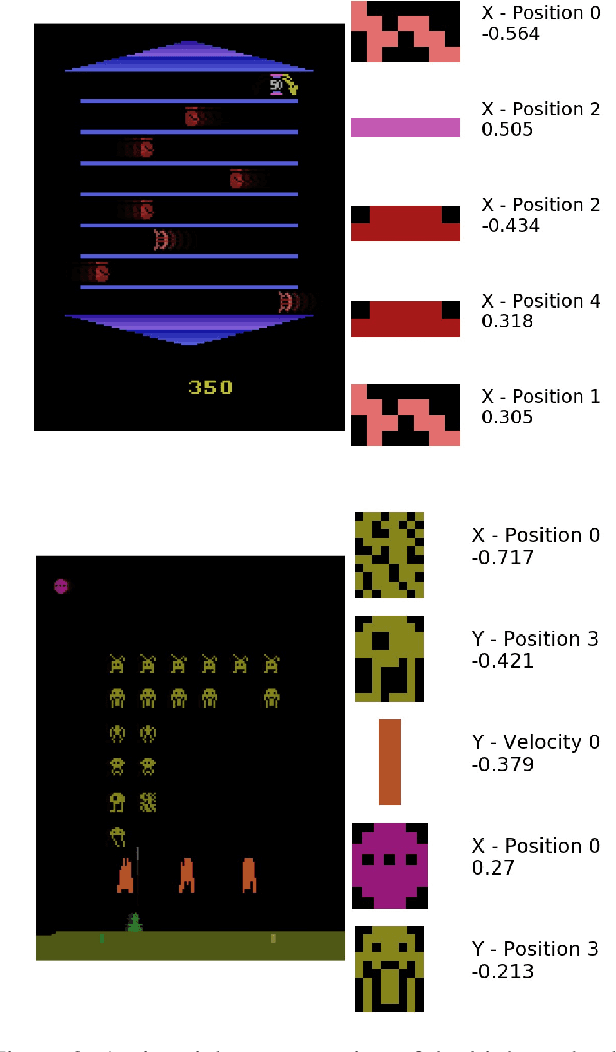
One major barrier to applications of deep Reinforcement Learning (RL) both inside and outside of games is the lack of explainability. In this paper, we describe a lightweight and effective method to derive explanations for deep RL agents, which we evaluate in the Atari domain. Our method relies on a transformation of the pixel-based input of the RL agent to an interpretable, percept-like input representation. We then train a surrogate model, which is itself interpretable, to replicate the behavior of the target, deep RL agent. Our experiments demonstrate that we can learn an effective surrogate that accurately approximates the underlying decision making of a target agent on a suite of Atari games.
* 9 pages, 3 figures, AIIDE 2021