 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Monitored Markov Decision Processes (Mon-MDPs)
May 13, 2025Reinforcement learning (RL) typically models the interaction between the agent and environment as a Markov decision process (MDP), where the rewards that guide the agent's behavior are always observable. However, in many real-world scenarios, rewards are not always observable, which can be modeled as a monitored Markov decision process (Mon-MDP). Prior work on Mon-MDPs have been limited to simple, tabular cases, restricting their applicability to real-world problems. This work explores Mon-MDPs using function approximation (FA) and investigates the challenges involved. We show that combining function approximation with a learned reward model enables agents to generalize from monitored states with observable rewards, to unmonitored environment states with unobservable rewards. Therefore, we demonstrate that such generalization with a reward model achieves near-optimal policies in environments formally defined as unsolvable. However, we identify a critical limitation of such function approximation, where agents incorrectly extrapolate rewards due to overgeneralization, resulting in undesirable behaviors. To mitigate overgeneralization, we propose a cautious police optimization method leveraging reward uncertainty. This work serves as a step towards bridging this gap between Mon-MDP theory and real-world applications.
Monitored Markov Decision Processes
Feb 13, 2024



In reinforcement learning (RL), an agent learns to perform a task by interacting with an environment and receiving feedback (a numerical reward) for its actions. However, the assumption that rewards are always observable is often not applicable in real-world problems. For example, the agent may need to ask a human to supervise its actions or activate a monitoring system to receive feedback. There may even be a period of time before rewards become observable, or a period of time after which rewards are no longer given. In other words, there are cases where the environment generates rewards in response to the agent's actions but the agent cannot observe them. In this paper, we formalize a novel but general RL framework - Monitored MDPs - where the agent cannot always observe rewards. We discuss the theoretical and practical consequences of this setting, show challenges raised even in toy environments, and propose algorithms to begin to tackle this novel setting. This paper introduces a powerful new formalism that encompasses both new and existing problems and lays the foundation for future research.
Learning to Be Cautious
Oct 29, 2021


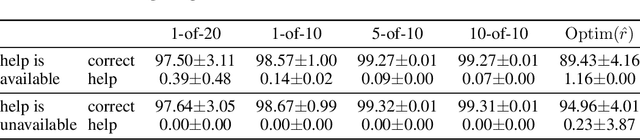
A key challenge in the field of reinforcement learning is to develop agents that behave cautiously in novel situations. It is generally impossible to anticipate all situations that an autonomous system may face or what behavior would best avoid bad outcomes. An agent that could learn to be cautious would overcome this challenge by discovering for itself when and how to behave cautiously. In contrast, current approaches typically embed task-specific safety information or explicit cautious behaviors into the system, which is error-prone and imposes extra burdens on practitioners. In this paper, we present both a sequence of tasks where cautious behavior becomes increasingly non-obvious, as well as an algorithm to demonstrate that it is possible for a system to \emph{learn} to be cautious. The essential features of our algorithm are that it characterizes reward function uncertainty without task-specific safety information and uses this uncertainty to construct a robust policy. Specifically, we construct robust policies with a $k$-of-$N$ counterfactual regret minimization (CFR) subroutine given a learned reward function uncertainty represented by a neural network ensemble belief. These policies exhibit caution in each of our tasks without any task-specific safety tuning.
Transfer Learning for Prosthetics Using Imitation Learning
Jan 15, 2019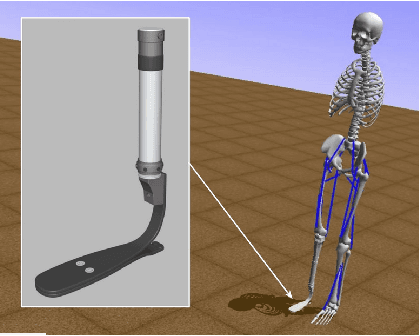
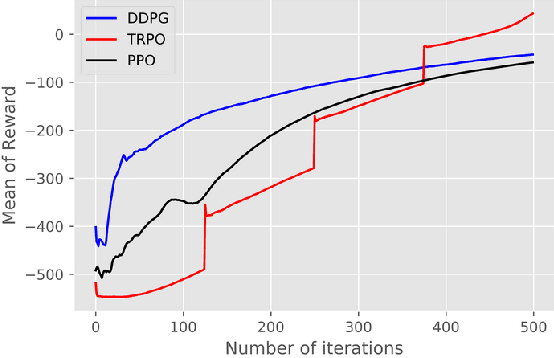
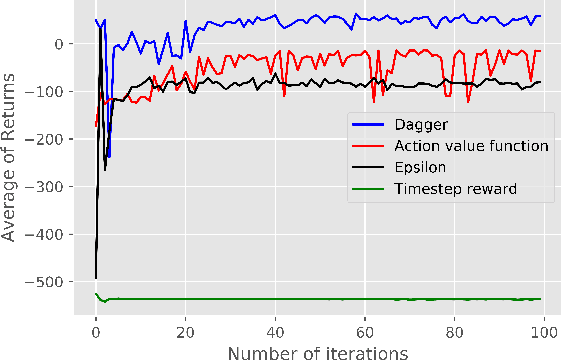
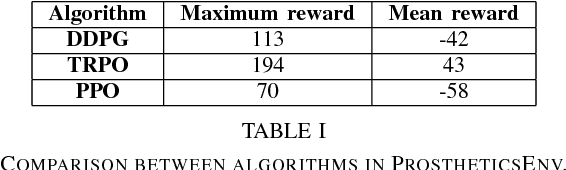
In this paper, We Apply Reinforcement learning (RL) techniques to train a realistic biomechanical model to work with different people and on different walking environments. We benchmarking 3 RL algorithms: Deep Deterministic Policy Gradient (DDPG), Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO) in OpenSim environment, Also we apply imitation learning to a prosthetics domain to reduce the training time needed to design customized prosthetics. We use DDPG algorithm to train an original expert agent. We then propose a modification to the Dataset Aggregation (DAgger) algorithm to reuse the expert knowledge and train a new target agent to replicate that behaviour in fewer than 5 iterations, compared to the 100 iterations taken by the expert agent which means reducing training time by 95%. Our modifications to the DAgger algorithm improve the balance between exploiting the expert policy and exploring the environment. We show empirically that these improve convergence time of the target agent, particularly when there is some degree of variation between expert and naive agent.
* Workshop paper, Black in AI, NeurIPS 2018