 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Exploration in Monitored Markov Decision Processes
Feb 24, 2025A tenet of reinforcement learning is that rewards are always observed by the agent. However, this is not true in many realistic settings, e.g., a human observer may not always be able to provide rewards, a sensor to observe rewards may be limited or broken, or rewards may be unavailable during deployment. Monitored Markov decision processes (Mon-MDPs) have recently been proposed as a model of such settings. Yet, Mon-MDP algorithms developed thus far do not fully exploit the problem structure, cannot take advantage of a known monitor, have no worst-case guarantees for ``unsolvable'' Mon-MDPs without specific initialization, and only have asymptotic proofs of convergence. This paper makes three contributions. First, we introduce a model-based algorithm for Mon-MDPs that addresses all of these shortcomings. The algorithm uses two instances of model-based interval estimation, one to guarantee that observable rewards are indeed observed, and another to learn the optimal policy. Second, empirical results demonstrate these advantages, showing faster convergence than prior algorithms in over two dozen benchmark settings, and even more dramatic improvements when the monitor process is known. Third, we present the first finite-sample bound on performance and show convergence to an optimal worst-case policy when some rewards are never observable.
Beyond Optimism: Exploration With Partially Observable Rewards
Jun 20, 2024



Exploration in reinforcement learning (RL) remains an open challenge. RL algorithms rely on observing rewards to train the agent, and if informative rewards are sparse the agent learns slowly or may not learn at all. To improve exploration and reward discovery, popular algorithms rely on optimism. But what if sometimes rewards are unobservable, e.g., situations of partial monitoring in bandits and the recent formalism of monitored Markov decision process? In this case, optimism can lead to suboptimal behavior that does not explore further to collapse uncertainty. With this paper, we present a novel exploration strategy that overcomes the limitations of existing methods and guarantees convergence to an optimal policy even when rewards are not always observable. We further propose a collection of tabular environments for benchmarking exploration in RL (with and without unobservable rewards) and show that our method outperforms existing ones.
Monitored Markov Decision Processes
Feb 13, 2024



In reinforcement learning (RL), an agent learns to perform a task by interacting with an environment and receiving feedback (a numerical reward) for its actions. However, the assumption that rewards are always observable is often not applicable in real-world problems. For example, the agent may need to ask a human to supervise its actions or activate a monitoring system to receive feedback. There may even be a period of time before rewards become observable, or a period of time after which rewards are no longer given. In other words, there are cases where the environment generates rewards in response to the agent's actions but the agent cannot observe them. In this paper, we formalize a novel but general RL framework - Monitored MDPs - where the agent cannot always observe rewards. We discuss the theoretical and practical consequences of this setting, show challenges raised even in toy environments, and propose algorithms to begin to tackle this novel setting. This paper introduces a powerful new formalism that encompasses both new and existing problems and lays the foundation for future research.
The Unsurprising Effectiveness of Pre-Trained Vision Models for Control
Mar 07, 2022



Recent years have seen the emergence of pre-trained representations as a powerful abstraction for AI applications in computer vision, natural language, and speech. However, policy learning for control is still dominated by a tabula-rasa learning paradigm, with visuo-motor policies often trained from scratch using data from deployment environments. In this context, we revisit and study the role of pre-trained visual representations for control, and in particular representations trained on large-scale computer vision datasets. Through extensive empirical evaluation in diverse control domains (Habitat, DeepMind Control, Adroit, Franka Kitchen), we isolate and study the importance of different representation training methods, data augmentations, and feature hierarchies. Overall, we find that pre-trained visual representations can be competitive or even better than ground-truth state representations to train control policies. This is in spite of using only out-of-domain data from standard vision datasets, without any in-domain data from the deployment environments. Additional details and source code is available at https://sites.google.com/view/pvr-control
Interesting Object, Curious Agent: Learning Task-Agnostic Exploration
Nov 25, 2021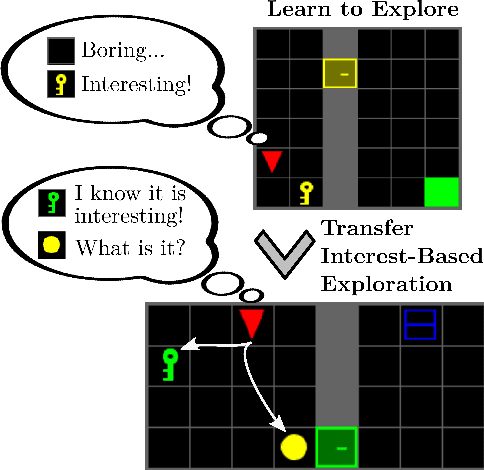

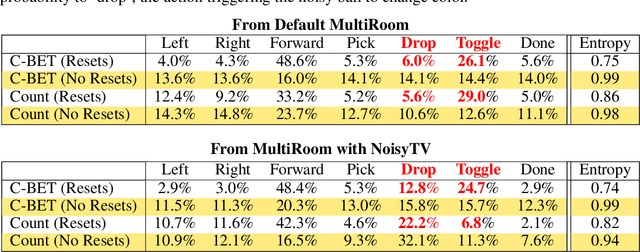
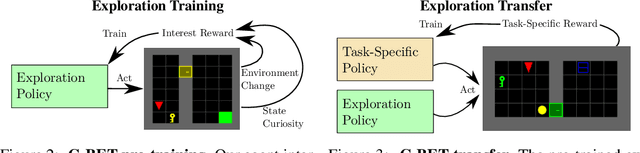
Common approaches for task-agnostic exploration learn tabula-rasa --the agent assumes isolated environments and no prior knowledge or experience. However, in the real world, agents learn in many environments and always come with prior experiences as they explore new ones. Exploration is a lifelong process. In this paper, we propose a paradigm change in the formulation and evaluation of task-agnostic exploration. In this setup, the agent first learns to explore across many environments without any extrinsic goal in a task-agnostic manner. Later on, the agent effectively transfers the learned exploration policy to better explore new environments when solving tasks. In this context, we evaluate several baseline exploration strategies and present a simple yet effective approach to learning task-agnostic exploration policies. Our key idea is that there are two components of exploration: (1) an agent-centric component encouraging exploration of unseen parts of the environment based on an agent's belief; (2) an environment-centric component encouraging exploration of inherently interesting objects. We show that our formulation is effective and provides the most consistent exploration across several training-testing environment pairs. We also introduce benchmarks and metrics for evaluating task-agnostic exploration strategies. The source code is available at https://github.com/sparisi/cbet/.
Long-Term Visitation Value for Deep Exploration in Sparse Reward Reinforcement Learning
Jan 01, 2020

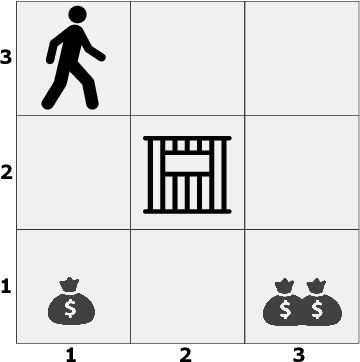

Reinforcement learning with sparse rewards is still an open challenge. Classic methods rely on getting feedback via extrinsic rewards to train the agent, and in situations where this occurs very rarely the agent learns slowly or cannot learn at all. Similarly, if the agent receives also rewards that create suboptimal modes of the objective function, it will likely prematurely stop exploring. More recent methods add auxiliary intrinsic rewards to encourage exploration. However, auxiliary rewards lead to a non-stationary target for the Q-function. In this paper, we present a novel approach that (1) plans exploration actions far into the future by using a long-term visitation count, and (2) decouples exploration and exploitation by learning a separate function assessing the exploration value of the actions. Contrary to existing methods which use models of reward and dynamics, our approach is off-policy and model-free. We further propose new tabular environments for benchmarking exploration in reinforcement learning. Empirical results on classic and novel benchmarks show that the proposed approach outperforms existing methods in environments with sparse rewards, especially in the presence of rewards that create suboptimal modes of the objective function. Results also suggest that our approach scales gracefully with the size of the environment. Source code is available at https://github.com/sparisi/visit-value-explore
TD-Regularized Actor-Critic Methods
Dec 23, 2018

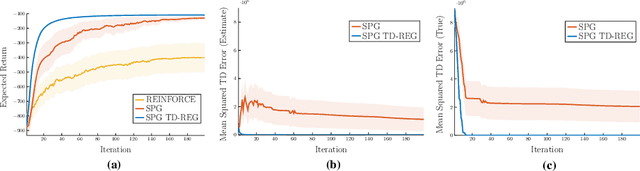
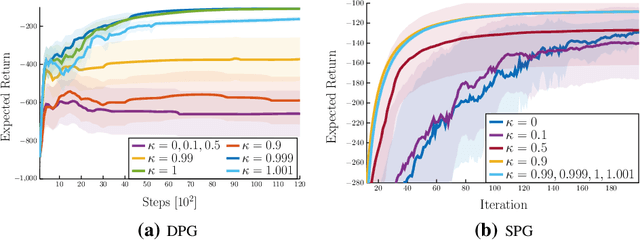
Actor-critic methods can achieve incredible performance on difficult reinforcement learning problems, but they are also prone to instability. This is partly due to the interaction between the actor and critic during learning, e.g., an inaccurate step taken by one of them might adversely affect the other and destabilize the learning. To avoid such issues, we propose to regularize the learning objective of the actor by penalizing the temporal difference (TD) error of the critic. This improves stability by avoiding large steps in the actor update whenever the critic is highly inaccurate. The resulting method, which we call the TD-regularized actor-critic method, is a simple plug-and-play approach to improve stability and overall performance of the actor-critic methods. Evaluations on standard benchmarks confirm this.
Policy Search with High-Dimensional Context Variables
Nov 10, 2016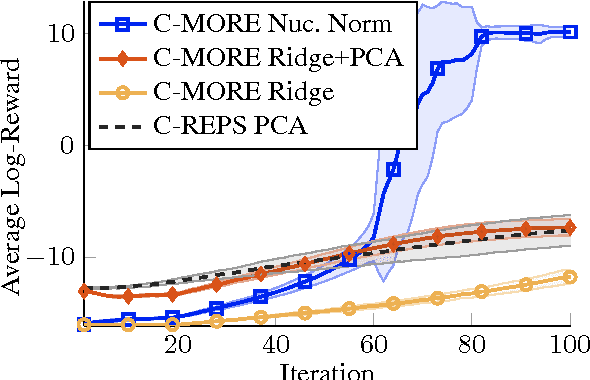
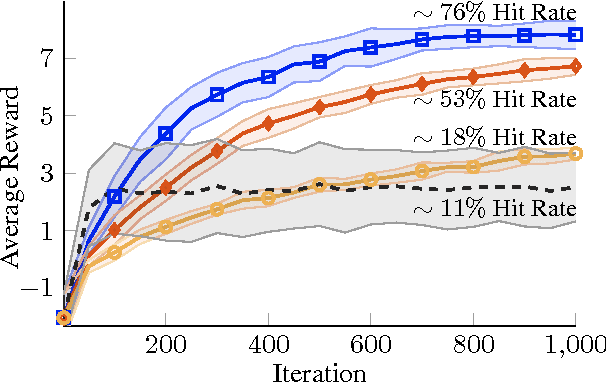

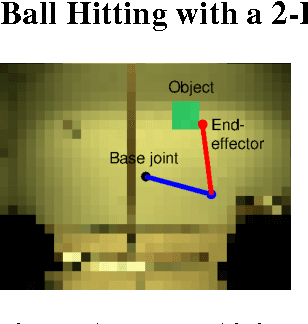
Direct contextual policy search methods learn to improve policy parameters and simultaneously generalize these parameters to different context or task variables. However, learning from high-dimensional context variables, such as camera images, is still a prominent problem in many real-world tasks. A naive application of unsupervised dimensionality reduction methods to the context variables, such as principal component analysis, is insufficient as task-relevant input may be ignored. In this paper, we propose a contextual policy search method in the model-based relative entropy stochastic search framework with integrated dimensionality reduction. We learn a model of the reward that is locally quadratic in both the policy parameters and the context variables. Furthermore, we perform supervised linear dimensionality reduction on the context variables by nuclear norm regularization. The experimental results show that the proposed method outperforms naive dimensionality reduction via principal component analysis and a state-of-the-art contextual policy search method.
Multi-objective Reinforcement Learning with Continuous Pareto Frontier Approximation Supplementary Material
Nov 18, 2014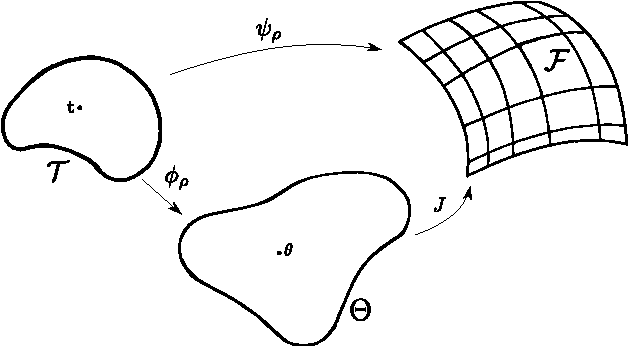
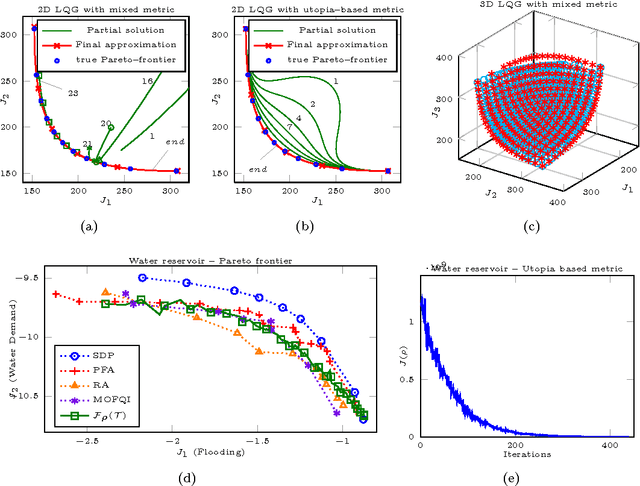
This document contains supplementary material for the paper "Multi-objective Reinforcement Learning with Continuous Pareto Frontier Approximation", published at the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI-15). The paper is about learning a continuous approximation of the Pareto frontier in Multi-Objective Markov Decision Problems (MOMDPs). We propose a policy-based approach that exploits gradient information to generate solutions close to the Pareto ones. Differently from previous policy-gradient multi-objective algorithms, where n optimization routines are use to have n solutions, our approach performs a single gradient-ascent run that at each step generates an improved continuous approximation of the Pareto frontier. The idea is to exploit a gradient-based approach to optimize the parameters of a function that defines a manifold in the policy parameter space so that the corresponding image in the objective space gets as close as possible to the Pareto frontier. Besides deriving how to compute and estimate such gradient, we will also discuss the non-trivial issue of defining a metric to assess the quality of the candidate Pareto frontiers. Finally, the properties of the proposed approach are empirically evaluated on two interesting MOMDPs.