 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Reinforcement Learning with Continuous Pareto Frontier Approximation Supplementary Material
Paper and Code
Nov 18, 2014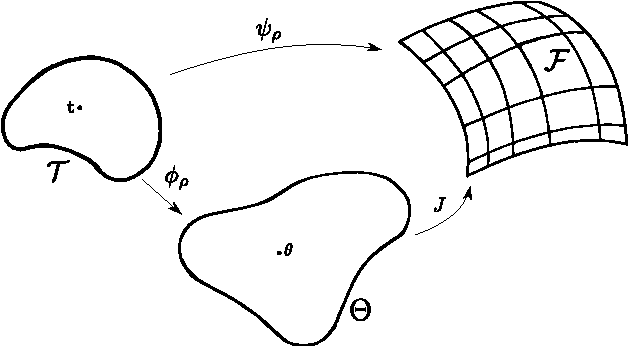
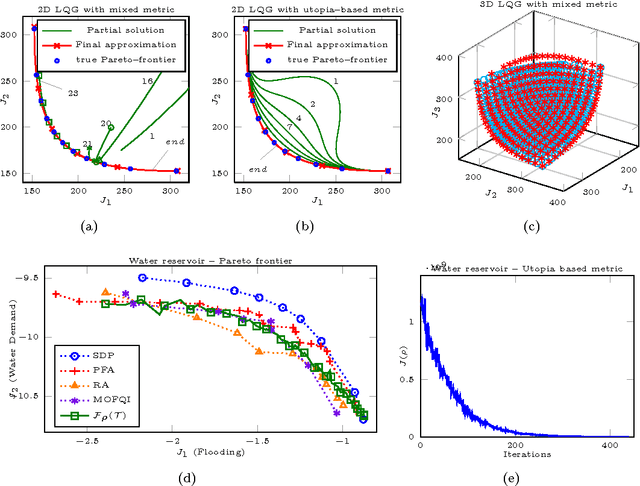
This document contains supplementary material for the paper "Multi-objective Reinforcement Learning with Continuous Pareto Frontier Approximation", published at the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI-15). The paper is about learning a continuous approximation of the Pareto frontier in Multi-Objective Markov Decision Problems (MOMDPs). We propose a policy-based approach that exploits gradient information to generate solutions close to the Pareto ones. Differently from previous policy-gradient multi-objective algorithms, where n optimization routines are use to have n solutions, our approach performs a single gradient-ascent run that at each step generates an improved continuous approximation of the Pareto frontier. The idea is to exploit a gradient-based approach to optimize the parameters of a function that defines a manifold in the policy parameter space so that the corresponding image in the objective space gets as close as possible to the Pareto frontier. Besides deriving how to compute and estimate such gradient, we will also discuss the non-trivial issue of defining a metric to assess the quality of the candidate Pareto frontiers. Finally, the properties of the proposed approach are empirically evaluated on two interesting MOMDPs.