 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Myriad: Jump-starting reinforcement learning with unsupervised parallel agents
Jan 26, 2026Parallelization in Reinforcement Learning is typically employed to speed up the training of a single policy, where multiple workers collect experience from an identical sampling distribution. This common design limits the potential of parallelization by neglecting the advantages of diverse exploration strategies. We propose K-Myriad, a scalable and unsupervised method that maximizes the collective state entropy induced by a population of parallel policies. By cultivating a portfolio of specialized exploration strategies, K-Myriad provides a robust initialization for Reinforcement Learning, leading to both higher training efficiency and the discovery of heterogeneous solutions. Experiments on high-dimensional continuous control tasks, with large-scale parallelization, demonstrate that K-Myriad can learn a broad set of distinct policies, highlighting its effectiveness for collective exploration and paving the way towards novel parallelization strategies.
From Parameters to Behavior: Unsupervised Compression of the Policy Space
Sep 26, 2025Despite its recent successes, Deep Reinforcement Learning (DRL) is notoriously sample-inefficient. We argue that this inefficiency stems from the standard practice of optimizing policies directly in the high-dimensional and highly redundant parameter space $\Theta$. This challenge is greatly compounded in multi-task settings. In this work, we develop a novel, unsupervised approach that compresses the policy parameter space $\Theta$ into a low-dimensional latent space $\mathcal{Z}$. We train a generative model $g:\mathcal{Z}\to\Theta$ by optimizing a behavioral reconstruction loss, which ensures that the latent space is organized by functional similarity rather than proximity in parameterization. We conjecture that the inherent dimensionality of this manifold is a function of the environment's complexity, rather than the size of the policy network. We validate our approach in continuous control domains, showing that the parameterization of standard policy networks can be compressed up to five orders of magnitude while retaining most of its expressivity. As a byproduct, we show that the learned manifold enables task-specific adaptation via Policy Gradient operating in the latent space $\mathcal{Z}$.
Limitations of Physics-Informed Neural Networks: a Study on Smart Grid Surrogation
Aug 29, 2025Physics-Informed Neural Networks (PINNs) present a transformative approach for smart grid modeling by integrating physical laws directly into learning frameworks, addressing critical challenges of data scarcity and physical consistency in conventional data-driven methods. This paper evaluates PINNs' capabilities as surrogate models for smart grid dynamics, comparing their performance against XGBoost, Random Forest, and Linear Regression across three key experiments: interpolation, cross-validation, and episodic trajectory prediction. By training PINNs exclusively through physics-based loss functions (enforcing power balance, operational constraints, and grid stability) we demonstrate their superior generalization, outperforming data-driven models in error reduction. Notably, PINNs maintain comparatively lower MAE in dynamic grid operations, reliably capturing state transitions in both random and expert-driven control scenarios, while traditional models exhibit erratic performance. Despite slight degradation in extreme operational regimes, PINNs consistently enforce physical feasibility, proving vital for safety-critical applications. Our results contribute to establishing PINNs as a paradigm-shifting tool for smart grid surrogation, bridging data-driven flexibility with first-principles rigor. This work advances real-time grid control and scalable digital twins, emphasizing the necessity of physics-aware architectures in mission-critical energy systems.
"So, Tell Me About Your Policy...": Distillation of interpretable policies from Deep Reinforcement Learning agents
Jul 10, 2025Recent advances in Reinforcement Learning (RL) largely benefit from the inclusion of Deep Neural Networks, boosting the number of novel approaches proposed in the field of Deep Reinforcement Learning (DRL). These techniques demonstrate the ability to tackle complex games such as Atari, Go, and other real-world applications, including financial trading. Nevertheless, a significant challenge emerges from the lack of interpretability, particularly when attempting to comprehend the underlying patterns learned, the relative importance of the state features, and how they are integrated to generate the policy's output. For this reason, in mission-critical and real-world settings, it is often preferred to deploy a simpler and more interpretable algorithm, although at the cost of performance. In this paper, we propose a novel algorithm, supported by theoretical guarantees, that can extract an interpretable policy (e.g., a linear policy) without disregarding the peculiarities of expert behavior. This result is obtained by considering the advantage function, which includes information about why an action is superior to the others. In contrast to previous works, our approach enables the training of an interpretable policy using previously collected experience. The proposed algorithm is empirically evaluated on classic control environments and on a financial trading scenario, demonstrating its ability to extract meaningful information from complex expert policies.
Enhancing Diversity in Parallel Agents: A Maximum State Entropy Exploration Story
May 02, 2025Parallel data collection has redefined Reinforcement Learning (RL), unlocking unprecedented efficiency and powering breakthroughs in large-scale real-world applications. In this paradigm, $N$ identical agents operate in $N$ replicas of an environment simulator, accelerating data collection by a factor of $N$. A critical question arises: \textit{Does specializing the policies of the parallel agents hold the key to surpass the $N$ factor acceleration?} In this paper, we introduce a novel learning framework that maximizes the entropy of collected data in a parallel setting. Our approach carefully balances the entropy of individual agents with inter-agent diversity, effectively minimizing redundancies. The latter idea is implemented with a centralized policy gradient method, which shows promise when evaluated empirically against systems of identical agents, as well as synergy with batch RL techniques that can exploit data diversity. Finally, we provide an original concentration analysis that shows faster rates for specialized parallel sampling distributions, which supports our methodology and may be of independent interest.
Towards Principled Multi-Agent Task Agnostic Exploration
Feb 12, 2025In reinforcement learning, we typically refer to task-agnostic exploration when we aim to explore the environment without access to the task specification a priori. In a single-agent setting the problem has been extensively studied and mostly understood. A popular approach cast the task-agnostic objective as maximizing the entropy of the state distribution induced by the agent's policy, from which principles and methods follows. In contrast, little is known about task-agnostic exploration in multi-agent settings, which are ubiquitous in the real world. How should different agents explore in the presence of others? In this paper, we address this question through a generalization to multiple agents of the problem of maximizing the state distribution entropy. First, we investigate alternative formulations, highlighting respective positives and negatives. Then, we present a scalable, decentralized, trust-region policy search algorithm to address the problem in practical settings. Finally, we provide proof of concept experiments to both corroborate the theoretical findings and pave the way for task-agnostic exploration in challenging multi-agent settings.
Achieving $\widetilde{\mathcal{O}}(\sqrt{T})$ Regret in Average-Reward POMDPs with Known Observation Models
Jan 30, 2025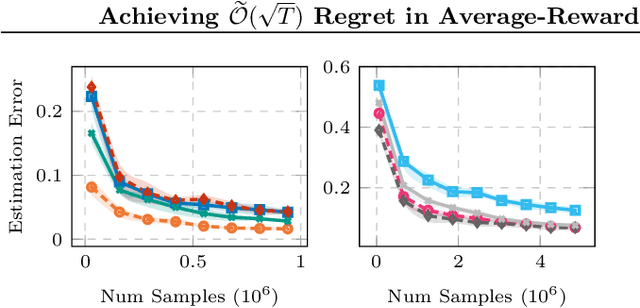
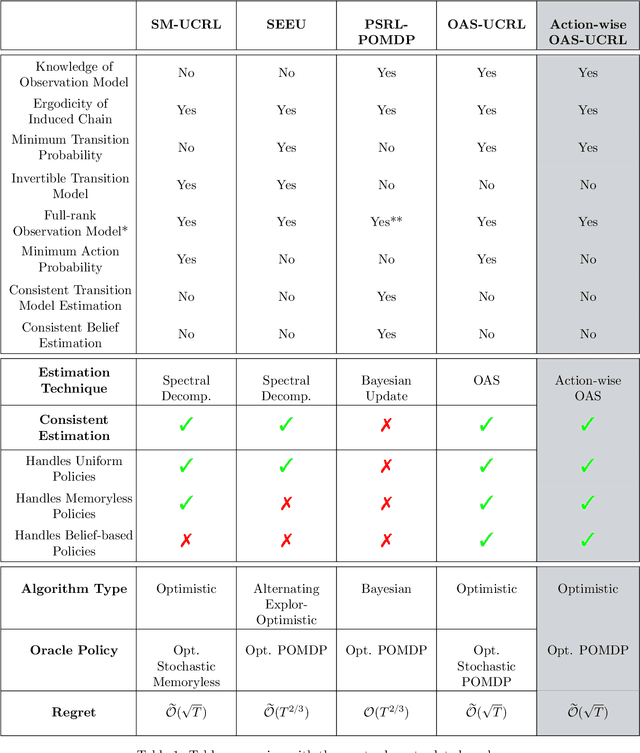
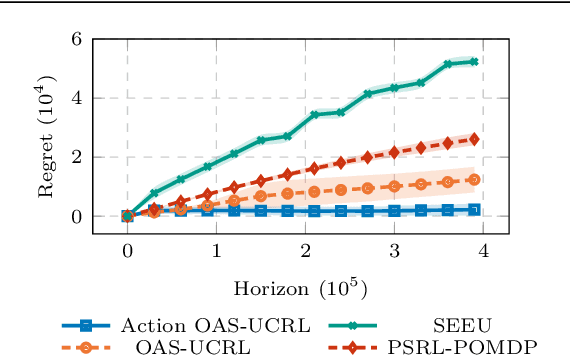
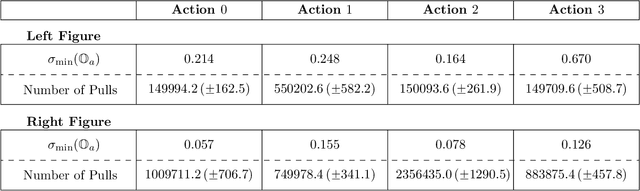
We tackle average-reward infinite-horizon POMDPs with an unknown transition model but a known observation model, a setting that has been previously addressed in two limiting ways: (i) frequentist methods relying on suboptimal stochastic policies having a minimum probability of choosing each action, and (ii) Bayesian approaches employing the optimal policy class but requiring strong assumptions about the consistency of employed estimators. Our work removes these limitations by proving convenient estimation guarantees for the transition model and introducing an optimistic algorithm that leverages the optimal class of deterministic belief-based policies. We introduce modifications to existing estimation techniques providing theoretical guarantees separately for each estimated action transition matrix. Unlike existing estimation methods that are unable to use samples from different policies, we present a novel and simple estimator that overcomes this barrier. This new data-efficient technique, combined with the proposed \emph{Action-wise OAS-UCRL} algorithm and a tighter theoretical analysis, leads to the first approach enjoying a regret guarantee of order $\mathcal{O}(\sqrt{T \,\log T})$ when compared against the optimal policy, thus improving over state of the art techniques. Finally, theoretical results are validated through numerical simulations showing the efficacy of our method against baseline methods.
A parametric algorithm is optimal for non-parametric regression of smooth functions
Dec 19, 2024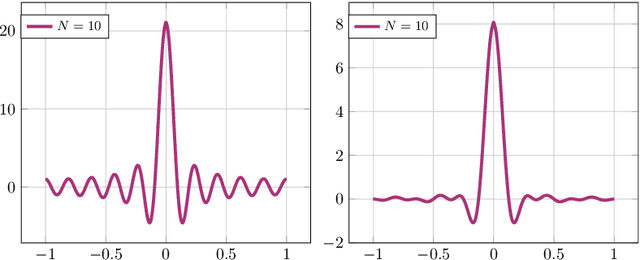

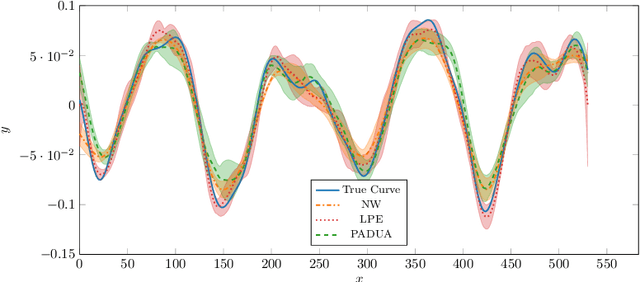
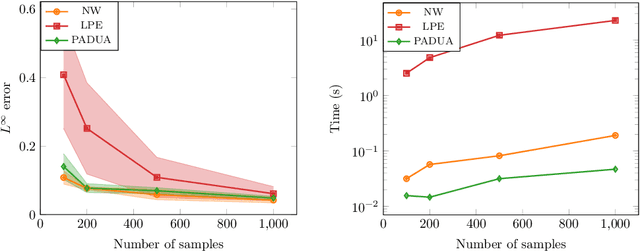
We address the regression problem for a general function $f:[-1,1]^d\to \mathbb R$ when the learner selects the training points $\{x_i\}_{i=1}^n$ to achieve a uniform error bound across the entire domain. In this setting, known historically as nonparametric regression, we aim to establish a sample complexity bound that depends solely on the function's degree of smoothness. Assuming periodicity at the domain boundaries, we introduce PADUA, an algorithm that, with high probability, provides performance guarantees optimal up to constant or logarithmic factors across all problem parameters. Notably, PADUA is the first parametric algorithm with optimal sample complexity for this setting. Due to this feature, we prove that, differently from the non-parametric state of the art, PADUA enjoys optimal space complexity in the prediction phase. To validate these results, we perform numerical experiments over functions coming from real audio data, where PADUA shows comparable performance to state-of-the-art methods, while requiring only a fraction of the computational time.
Statistical Analysis of Policy Space Compression Problem
Nov 15, 2024Policy search methods are crucial in reinforcement learning, offering a framework to address continuous state-action and partially observable problems. However, the complexity of exploring vast policy spaces can lead to significant inefficiencies. Reducing the policy space through policy compression emerges as a powerful, reward-free approach to accelerate the learning process. This technique condenses the policy space into a smaller, representative set while maintaining most of the original effectiveness. Our research focuses on determining the necessary sample size to learn this compressed set accurately. We employ R\'enyi divergence to measure the similarity between true and estimated policy distributions, establishing error bounds for good approximations. To simplify the analysis, we employ the $l_1$ norm, determining sample size requirements for both model-based and model-free settings. Finally, we correlate the error bounds from the $l_1$ norm with those from R\'enyi divergence, distinguishing between policies near the vertices and those in the middle of the policy space, to determine the lower and upper bounds for the required sample sizes.
A Retrospective on the Robot Air Hockey Challenge: Benchmarking Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Nov 08, 2024Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited. Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks. The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging. Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution. The successful real-world air hockey deployment of best-performing agents sets the foundation for future competitions and follow-up research directions.