 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo-Regret Learning Under Adversarial Resource Constraints: A Spending Plan Is All You Need!
Jun 16, 2025We study online decision making problems under resource constraints, where both reward and cost functions are drawn from distributions that may change adversarially over time. We focus on two canonical settings: $(i)$ online resource allocation where rewards and costs are observed before action selection, and $(ii)$ online learning with resource constraints where they are observed after action selection, under full feedback or bandit feedback. It is well known that achieving sublinear regret in these settings is impossible when reward and cost distributions may change arbitrarily over time. To address this challenge, we analyze a framework in which the learner is guided by a spending plan--a sequence prescribing expected resource usage across rounds. We design general (primal-)dual methods that achieve sublinear regret with respect to baselines that follow the spending plan. Crucially, the performance of our algorithms improves when the spending plan ensures a well-balanced distribution of the budget across rounds. We additionally provide a robust variant of our methods to handle worst-case scenarios where the spending plan is highly imbalanced. To conclude, we study the regret of our algorithms when competing against benchmarks that deviate from the prescribed spending plan.
Catoni-Style Change Point Detection for Regret Minimization in Non-Stationary Heavy-Tailed Bandits
May 26, 2025Regret minimization in stochastic non-stationary bandits gained popularity over the last decade, as it can model a broad class of real-world problems, from advertising to recommendation systems. Existing literature relies on various assumptions about the reward-generating process, such as Bernoulli or subgaussian rewards. However, in settings such as finance and telecommunications, heavy-tailed distributions naturally arise. In this work, we tackle the heavy-tailed piecewise-stationary bandit problem. Heavy-tailed bandits, introduced by Bubeck et al., 2013, operate on the minimal assumption that the finite absolute centered moments of maximum order $1+\epsilon$ are uniformly bounded by a constant $v<+\infty$, for some $\epsilon \in (0,1]$. We focus on the most popular non-stationary bandit setting, i.e., the piecewise-stationary setting, in which the mean of reward-generating distributions may change at unknown time steps. We provide a novel Catoni-style change-point detection strategy tailored for heavy-tailed distributions that relies on recent advancements in the theory of sequential estimation, which is of independent interest. We introduce Robust-CPD-UCB, which combines this change-point detection strategy with optimistic algorithms for bandits, providing its regret upper bound and an impossibility result on the minimum attainable regret for any policy. Finally, we validate our approach through numerical experiments on synthetic and real-world datasets.
Data-Dependent Regret Bounds for Constrained MABs
May 26, 2025This paper initiates the study of data-dependent regret bounds in constrained MAB settings. These bounds depend on the sequence of losses that characterize the problem instance. Thus, they can be much smaller than classical $\widetilde{\mathcal{O}}(\sqrt{T})$ regret bounds, while being equivalent to them in the worst case. Despite this, data-dependent regret bounds have been completely overlooked in constrained MAB settings. The goal of this paper is to answer the following question: Can data-dependent regret bounds be derived in the presence of constraints? We answer this question affirmatively in constrained MABs with adversarial losses and stochastic constraints. Specifically, our main focus is on the most challenging and natural settings with hard constraints, where the learner must ensure that the constraints are always satisfied with high probability. We design an algorithm with a regret bound consisting of two data-dependent terms. The first term captures the difficulty of satisfying the constraints, while the second one encodes the complexity of learning independently of the presence of constraints. We also prove a lower bound showing that these two terms are not artifacts of our specific approach and analysis, but rather the fundamental components that inherently characterize the complexities of the problem. Finally, in designing our algorithm, we also derive some novel results in the related (and easier) soft constraints settings, which may be of independent interest.
Automating the loop in traffic incident management on highway
Mar 15, 2025



Effective traffic incident management is essential for ensuring safety, minimizing congestion, and reducing response times in emergency situations. Traditional highway incident management relies heavily on radio room operators, who must make rapid, informed decisions in high-stakes environments. This paper proposes an innovative solution to support and enhance these decisions by integrating Large Language Models (LLMs) into a decision-support system for traffic incident management. We introduce two approaches: (1) an LLM + Optimization hybrid that leverages both the flexibility of natural language interaction and the robustness of optimization techniques, and (2) a Full LLM approach that autonomously generates decisions using only LLM capabilities. We tested our solutions using historical event data from Autostrade per l'Italia. Experimental results indicate that while both approaches show promise, the LLM + Optimization solution demonstrates superior reliability, making it particularly suited to critical applications where consistency and accuracy are paramount. This research highlights the potential for LLMs to transform highway incident management by enabling accessible, data-driven decision-making support.
Regret Minimization for Piecewise Linear Rewards: Contracts, Auctions, and Beyond
Mar 03, 2025Most microeconomic models of interest involve optimizing a piecewise linear function. These include contract design in hidden-action principal-agent problems, selling an item in posted-price auctions, and bidding in first-price auctions. When the relevant model parameters are unknown and determined by some (unknown) probability distributions, the problem becomes learning how to optimize an unknown and stochastic piecewise linear reward function. Such a problem is usually framed within an online learning framework, where the decision-maker (learner) seeks to minimize the regret of not knowing an optimal decision in hindsight. This paper introduces a general online learning framework that offers a unified approach to tackle regret minimization for piecewise linear rewards, under a suitable monotonicity assumption commonly satisfied by microeconomic models. We design a learning algorithm that attains a regret of $\widetilde{O}(\sqrt{nT})$, where $n$ is the number of ``pieces'' of the reward function and $T$ is the number of rounds. This result is tight when $n$ is \emph{small} relative to $T$, specifically when $n \leq T^{1/3}$. Our algorithm solves two open problems in the literature on learning in microeconomic settings. First, it shows that the $\widetilde{O}(T^{2/3})$ regret bound obtained by Zhu et al. [Zhu+23] for learning optimal linear contracts in hidden-action principal-agent problems is not tight when the number of agent's actions is small relative to $T$. Second, our algorithm demonstrates that, in the problem of learning to set prices in posted-price auctions, it is possible to attain suitable (and desirable) instance-independent regret bounds, addressing an open problem posed by Cesa-Bianchi et al. [CBCP19].
Optimal Strong Regret and Violation in Constrained MDPs via Policy Optimization
Oct 03, 2024We study online learning in \emph{constrained MDPs} (CMDPs), focusing on the goal of attaining sublinear strong regret and strong cumulative constraint violation. Differently from their standard (weak) counterparts, these metrics do not allow negative terms to compensate positive ones, raising considerable additional challenges. Efroni et al. (2020) were the first to propose an algorithm with sublinear strong regret and strong violation, by exploiting linear programming. Thus, their algorithm is highly inefficient, leaving as an open problem achieving sublinear bounds by means of policy optimization methods, which are much more efficient in practice. Very recently, Muller et al. (2024) have partially addressed this problem by proposing a policy optimization method that allows to attain $\widetilde{\mathcal{O}}(T^{0.93})$ strong regret/violation. This still leaves open the question of whether optimal bounds are achievable by using an approach of this kind. We answer such a question affirmatively, by providing an efficient policy optimization algorithm with $\widetilde{\mathcal{O}}(\sqrt{T})$ strong regret/violation. Our algorithm implements a primal-dual scheme that employs a state-of-the-art policy optimization approach for adversarial (unconstrained) MDPs as primal algorithm, and a UCB-like update for dual variables.
Best-of-Both-Worlds Policy Optimization for CMDPs with Bandit Feedback
Oct 03, 2024We study online learning in constrained Markov decision processes (CMDPs) in which rewards and constraints may be either stochastic or adversarial. In such settings, Stradi et al.(2024) proposed the first best-of-both-worlds algorithm able to seamlessly handle stochastic and adversarial constraints, achieving optimal regret and constraint violation bounds in both cases. This algorithm suffers from two major drawbacks. First, it only works under full feedback, which severely limits its applicability in practice. Moreover, it relies on optimizing over the space of occupancy measures, which requires solving convex optimization problems, an highly inefficient task. In this paper, we provide the first best-of-both-worlds algorithm for CMDPs with bandit feedback. Specifically, when the constraints are stochastic, the algorithm achieves $\widetilde{\mathcal{O}}(\sqrt{T})$ regret and constraint violation, while, when they are adversarial, it attains $\widetilde{\mathcal{O}}(\sqrt{T})$ constraint violation and a tight fraction of the optimal reward. Moreover, our algorithm is based on a policy optimization approach, which is much more efficient than occupancy-measure-based methods.
Bridging Rested and Restless Bandits with Graph-Triggering: Rising and Rotting
Sep 09, 2024

Rested and Restless Bandits are two well-known bandit settings that are useful to model real-world sequential decision-making problems in which the expected reward of an arm evolves over time due to the actions we perform or due to the nature. In this work, we propose Graph-Triggered Bandits (GTBs), a unifying framework to generalize and extend rested and restless bandits. In this setting, the evolution of the arms' expected rewards is governed by a graph defined over the arms. An edge connecting a pair of arms $(i,j)$ represents the fact that a pull of arm $i$ triggers the evolution of arm $j$, and vice versa. Interestingly, rested and restless bandits are both special cases of our model for some suitable (degenerated) graph. As relevant case studies for this setting, we focus on two specific types of monotonic bandits: rising, where the expected reward of an arm grows as the number of triggers increases, and rotting, where the opposite behavior occurs. For these cases, we study the optimal policies. We provide suitable algorithms for all scenarios and discuss their theoretical guarantees, highlighting the complexity of the learning problem concerning instance-dependent terms that encode specific properties of the underlying graph structure.
A Primal-Dual Online Learning Approach for Dynamic Pricing of Sequentially Displayed Complementary Items under Sale Constraints
Jul 08, 2024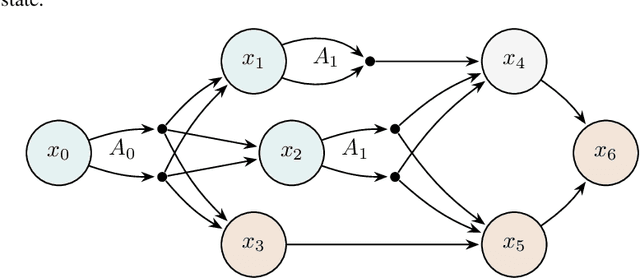

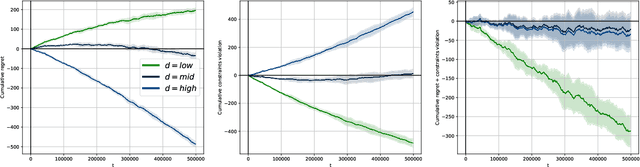
We address the challenging problem of dynamically pricing complementary items that are sequentially displayed to customers. An illustrative example is the online sale of flight tickets, where customers navigate through multiple web pages. Initially, they view the ticket cost, followed by ancillary expenses such as insurance and additional luggage fees. Coherent pricing policies for complementary items are essential because optimizing the pricing of each item individually is ineffective. Our scenario also involves a sales constraint, which specifies a minimum number of items to sell, and uncertainty regarding customer demand curves. To tackle this problem, we originally formulate it as a Markov Decision Process with constraints. Leveraging online learning tools, we design a primal-dual online optimization algorithm. We empirically evaluate our approach using synthetic settings randomly generated from real-world data, covering various configurations from stationary to non-stationary, and compare its performance in terms of constraints violation and regret against well-known baselines optimizing each state singularly.
Learning Constrained Markov Decision Processes With Non-stationary Rewards and Constraints
May 23, 2024In constrained Markov decision processes (CMDPs) with adversarial rewards and constraints, a well-known impossibility result prevents any algorithm from attaining both sublinear regret and sublinear constraint violation, when competing against a best-in-hindsight policy that satisfies constraints on average. In this paper, we show that this negative result can be eased in CMDPs with non-stationary rewards and constraints, by providing algorithms whose performances smoothly degrade as non-stationarity increases. Specifically, we propose algorithms attaining $\tilde{\mathcal{O}} (\sqrt{T} + C)$ regret and positive constraint violation under bandit feedback, where $C$ is a corruption value measuring the environment non-stationarity. This can be $\Theta(T)$ in the worst case, coherently with the impossibility result for adversarial CMDPs. First, we design an algorithm with the desired guarantees when $C$ is known. Then, in the case $C$ is unknown, we show how to obtain the same results by embedding such an algorithm in a general meta-procedure. This is of independent interest, as it can be applied to any non-stationary constrained online learning setting.