 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Regret Rates in Bilateral Trade via Sublinear Budget Violation
Jul 15, 2025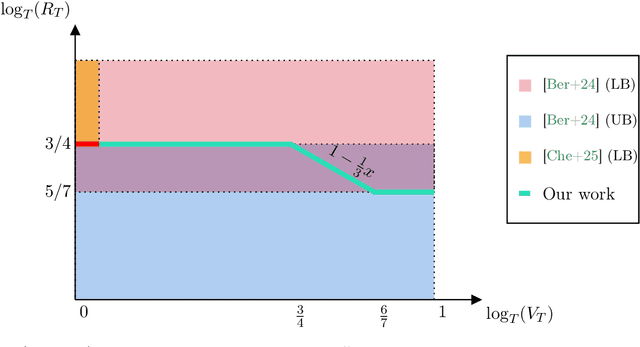

Bilateral trade is a central problem in algorithmic economics, and recent work has explored how to design trading mechanisms using no-regret learning algorithms. However, no-regret learning is impossible when budget balance has to be enforced at each time step. Bernasconi et al. [Ber+24] show how this impossibility can be circumvented by relaxing the budget balance constraint to hold only globally over all time steps. In particular, they design an algorithm achieving regret of the order of $\tilde O(T^{3/4})$ and provide a lower bound of $\Omega(T^{5/7})$. In this work, we interpolate between these two extremes by studying how the optimal regret rate varies with the allowed violation of the global budget balance constraint. Specifically, we design an algorithm that, by violating the constraint by at most $T^{\beta}$ for any given $\beta \in [\frac{3}{4}, \frac{6}{7}]$, attains regret $\tilde O(T^{1 - \beta/3})$. We complement this result with a matching lower bound, thus fully characterizing the trade-off between regret and budget violation. Our results show that both the $\tilde O(T^{3/4})$ upper bound in the global budget balance case and the $\Omega(T^{5/7})$ lower bound under unconstrained budget balance violation obtained by Bernasconi et al. [Ber+24] are tight.
Best-of-Both-Worlds Policy Optimization for CMDPs with Bandit Feedback
Oct 03, 2024We study online learning in constrained Markov decision processes (CMDPs) in which rewards and constraints may be either stochastic or adversarial. In such settings, Stradi et al.(2024) proposed the first best-of-both-worlds algorithm able to seamlessly handle stochastic and adversarial constraints, achieving optimal regret and constraint violation bounds in both cases. This algorithm suffers from two major drawbacks. First, it only works under full feedback, which severely limits its applicability in practice. Moreover, it relies on optimizing over the space of occupancy measures, which requires solving convex optimization problems, an highly inefficient task. In this paper, we provide the first best-of-both-worlds algorithm for CMDPs with bandit feedback. Specifically, when the constraints are stochastic, the algorithm achieves $\widetilde{\mathcal{O}}(\sqrt{T})$ regret and constraint violation, while, when they are adversarial, it attains $\widetilde{\mathcal{O}}(\sqrt{T})$ constraint violation and a tight fraction of the optimal reward. Moreover, our algorithm is based on a policy optimization approach, which is much more efficient than occupancy-measure-based methods.
Learning Constrained Markov Decision Processes With Non-stationary Rewards and Constraints
May 23, 2024In constrained Markov decision processes (CMDPs) with adversarial rewards and constraints, a well-known impossibility result prevents any algorithm from attaining both sublinear regret and sublinear constraint violation, when competing against a best-in-hindsight policy that satisfies constraints on average. In this paper, we show that this negative result can be eased in CMDPs with non-stationary rewards and constraints, by providing algorithms whose performances smoothly degrade as non-stationarity increases. Specifically, we propose algorithms attaining $\tilde{\mathcal{O}} (\sqrt{T} + C)$ regret and positive constraint violation under bandit feedback, where $C$ is a corruption value measuring the environment non-stationarity. This can be $\Theta(T)$ in the worst case, coherently with the impossibility result for adversarial CMDPs. First, we design an algorithm with the desired guarantees when $C$ is known. Then, in the case $C$ is unknown, we show how to obtain the same results by embedding such an algorithm in a general meta-procedure. This is of independent interest, as it can be applied to any non-stationary constrained online learning setting.