 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusing Trajectories in Policy Gradients Enables Fast Convergence
Jun 06, 2025



Policy gradient (PG) methods are a class of effective reinforcement learning algorithms, particularly when dealing with continuous control problems. These methods learn the parameters of parametric policies via stochastic gradient ascent, typically using on-policy trajectory data to estimate the policy gradient. However, such reliance on fresh data makes them sample-inefficient. Indeed, vanilla PG methods require $O(\epsilon^{-2})$ trajectories to reach an $\epsilon$-approximate stationary point. A common strategy to improve efficiency is to reuse off-policy information from past iterations, such as previous gradients or trajectories. While gradient reuse has received substantial theoretical attention, leading to improved rates of $O(\epsilon^{-3/2})$, the reuse of past trajectories remains largely unexplored from a theoretical perspective. In this work, we provide the first rigorous theoretical evidence that extensive reuse of past off-policy trajectories can significantly accelerate convergence in PG methods. We introduce a power mean correction to the multiple importance weighting estimator and propose RPG (Retrospective Policy Gradient), a PG algorithm that combines old and new trajectories for policy updates. Through a novel analysis, we show that, under established assumptions, RPG achieves a sample complexity of $\widetilde{O}(\epsilon^{-1})$, the best known rate in the literature. We further validate empirically our approach against PG methods with state-of-the-art rates.
Learning Deterministic Policies with Policy Gradients in Constrained Markov Decision Processes
Jun 06, 2025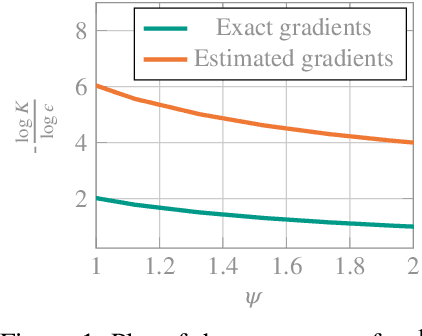



Constrained Reinforcement Learning (CRL) addresses sequential decision-making problems where agents are required to achieve goals by maximizing the expected return while meeting domain-specific constraints. In this setting, policy-based methods are widely used thanks to their advantages when dealing with continuous-control problems. These methods search in the policy space with an action-based or a parameter-based exploration strategy, depending on whether they learn the parameters of a stochastic policy or those of a stochastic hyperpolicy. We introduce an exploration-agnostic algorithm, called C-PG, which enjoys global last-iterate convergence guarantees under gradient domination assumptions. Furthermore, under specific noise models where the (hyper)policy is expressed as a stochastic perturbation of the actions or of the parameters of an underlying deterministic policy, we additionally establish global last-iterate convergence guarantees of C-PG to the optimal deterministic policy. This holds when learning a stochastic (hyper)policy and subsequently switching off the stochasticity at the end of training, thereby deploying a deterministic policy. Finally, we empirically validate both the action-based (C-PGAE) and parameter-based (C-PGPE) variants of C-PG on constrained control tasks, and compare them against state-of-the-art baselines, demonstrating their effectiveness, in particular when deploying deterministic policies after training.
A Refined Analysis of UCBVI
Feb 24, 2025In this work, we provide a refined analysis of the UCBVI algorithm (Azar et al., 2017), improving both the bonus terms and the regret analysis. Additionally, we compare our version of UCBVI with both its original version and the state-of-the-art MVP algorithm. Our empirical validation demonstrates that improving the multiplicative constants in the bounds has significant positive effects on the empirical performance of the algorithms.
Bridging Rested and Restless Bandits with Graph-Triggering: Rising and Rotting
Sep 09, 2024

Rested and Restless Bandits are two well-known bandit settings that are useful to model real-world sequential decision-making problems in which the expected reward of an arm evolves over time due to the actions we perform or due to the nature. In this work, we propose Graph-Triggered Bandits (GTBs), a unifying framework to generalize and extend rested and restless bandits. In this setting, the evolution of the arms' expected rewards is governed by a graph defined over the arms. An edge connecting a pair of arms $(i,j)$ represents the fact that a pull of arm $i$ triggers the evolution of arm $j$, and vice versa. Interestingly, rested and restless bandits are both special cases of our model for some suitable (degenerated) graph. As relevant case studies for this setting, we focus on two specific types of monotonic bandits: rising, where the expected reward of an arm grows as the number of triggers increases, and rotting, where the opposite behavior occurs. For these cases, we study the optimal policies. We provide suitable algorithms for all scenarios and discuss their theoretical guarantees, highlighting the complexity of the learning problem concerning instance-dependent terms that encode specific properties of the underlying graph structure.
State and Action Factorization in Power Grids
Sep 03, 2024

The increase of renewable energy generation towards the zero-emission target is making the problem of controlling power grids more and more challenging. The recent series of competitions Learning To Run a Power Network (L2RPN) have encouraged the use of Reinforcement Learning (RL) for the assistance of human dispatchers in operating power grids. All the solutions proposed so far severely restrict the action space and are based on a single agent acting on the entire grid or multiple independent agents acting at the substations level. In this work, we propose a domain-agnostic algorithm that estimates correlations between state and action components entirely based on data. Highly correlated state-action pairs are grouped together to create simpler, possibly independent subproblems that can lead to distinct learning processes with less computational and data requirements. The algorithm is validated on a power grid benchmark obtained with the Grid2Op simulator that has been used throughout the aforementioned competitions, showing that our algorithm is in line with domain-expert analysis. Based on these results, we lay a theoretically-grounded foundation for using distributed reinforcement learning in order to improve the existing solutions.
Last-Iterate Global Convergence of Policy Gradients for Constrained Reinforcement Learning
Jul 15, 2024Constrained Reinforcement Learning (CRL) tackles sequential decision-making problems where agents are required to achieve goals by maximizing the expected return while meeting domain-specific constraints, which are often formulated as expected costs. In this setting, policy-based methods are widely used since they come with several advantages when dealing with continuous-control problems. These methods search in the policy space with an action-based or parameter-based exploration strategy, depending on whether they learn directly the parameters of a stochastic policy or those of a stochastic hyperpolicy. In this paper, we propose a general framework for addressing CRL problems via gradient-based primal-dual algorithms, relying on an alternate ascent/descent scheme with dual-variable regularization. We introduce an exploration-agnostic algorithm, called C-PG, which exhibits global last-iterate convergence guarantees under (weak) gradient domination assumptions, improving and generalizing existing results. Then, we design C-PGAE and C-PGPE, the action-based and the parameter-based versions of C-PG, respectively, and we illustrate how they naturally extend to constraints defined in terms of risk measures over the costs, as it is often requested in safety-critical scenarios. Finally, we numerically validate our algorithms on constrained control problems, and compare them with state-of-the-art baselines, demonstrating their effectiveness.
Open Problem: Tight Bounds for Kernelized Multi-Armed Bandits with Bernoulli Rewards
Jul 08, 2024We consider Kernelized Bandits (KBs) to optimize a function $f : \mathcal{X} \rightarrow [0,1]$ belonging to the Reproducing Kernel Hilbert Space (RKHS) $\mathcal{H}_k$. Mainstream works on kernelized bandits focus on a subgaussian noise model in which observations of the form $f(\mathbf{x}_t)+\epsilon_t$, being $\epsilon_t$ a subgaussian noise, are available (Chowdhury and Gopalan, 2017). Differently, we focus on the case in which we observe realizations $y_t \sim \text{Ber}(f(\mathbf{x}_t))$ sampled from a Bernoulli distribution with parameter $f(\mathbf{x}_t)$. While the Bernoulli model has been investigated successfully in multi-armed bandits (Garivier and Capp\'e, 2011), logistic bandits (Faury et al., 2022), bandits in metric spaces (Magureanu et al., 2014), it remains an open question whether tight results can be obtained for KBs. This paper aims to draw the attention of the online learning community to this open problem.
Learning Optimal Deterministic Policies with Stochastic Policy Gradients
May 03, 2024



Policy gradient (PG) methods are successful approaches to deal with continuous reinforcement learning (RL) problems. They learn stochastic parametric (hyper)policies by either exploring in the space of actions or in the space of parameters. Stochastic controllers, however, are often undesirable from a practical perspective because of their lack of robustness, safety, and traceability. In common practice, stochastic (hyper)policies are learned only to deploy their deterministic version. In this paper, we make a step towards the theoretical understanding of this practice. After introducing a novel framework for modeling this scenario, we study the global convergence to the best deterministic policy, under (weak) gradient domination assumptions. Then, we illustrate how to tune the exploration level used for learning to optimize the trade-off between the sample complexity and the performance of the deployed deterministic policy. Finally, we quantitatively compare action-based and parameter-based exploration, giving a formal guise to intuitive results.
Best Arm Identification for Stochastic Rising Bandits
Feb 15, 2023Stochastic Rising Bandits is a setting in which the values of the expected rewards of the available options increase every time they are selected. This framework models a wide range of scenarios in which the available options are learning entities whose performance improves over time. In this paper, we focus on the Best Arm Identification (BAI) problem for the stochastic rested rising bandits. In this scenario, we are asked, given a fixed budget of rounds, to provide a recommendation about the best option at the end of the selection process. We propose two algorithms to tackle the above-mentioned setting, namely R-UCBE, which resorts to a UCB-like approach, and R-SR, which employs a successive reject procedure. We show that they provide guarantees on the probability of properly identifying the optimal option at the end of the learning process. Finally, we numerically validate the proposed algorithms in synthetic and realistic environments and compare them with the currently available BAI strategies.
Autoregressive Bandits
Dec 12, 2022Autoregressive processes naturally arise in a large variety of real-world scenarios, including e.g., stock markets, sell forecasting, weather prediction, advertising, and pricing. When addressing a sequential decision-making problem in such a context, the temporal dependence between consecutive observations should be properly accounted for converge to the optimal decision policy. In this work, we propose a novel online learning setting, named Autoregressive Bandits (ARBs), in which the observed reward follows an autoregressive process of order $k$, whose parameters depend on the action the agent chooses, within a finite set of $n$ actions. Then, we devise an optimistic regret minimization algorithm AutoRegressive Upper Confidence Bounds (AR-UCB) that suffers regret of order $\widetilde{\mathcal{O}} \left( \frac{(k+1)^{3/2}\sqrt{nT}}{(1-\Gamma)^2} \right)$, being $T$ the optimization horizon and $\Gamma < 1$ an index of the stability of the system. Finally, we present a numerical validation in several synthetic and one real-world setting, in comparison with general and specific purpose bandit baselines showing the advantages of the proposed approach.