 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Log-Barrier Helps Exploration in Policy Optimization
Mar 16, 2026Recently, it has been shown that the Stochastic Gradient Bandit (SGB) algorithm converges to a globally optimal policy with a constant learning rate. However, these guarantees rely on unrealistic assumptions about the learning process, namely that the probability of the optimal action is always bounded away from zero. We attribute this to the lack of an explicit exploration mechanism in SGB. To address these limitations, we propose to regularize the SGB objective with a log-barrier on the parametric policy, structurally enforcing a minimal amount of exploration. We prove that Log-Barrier Stochastic Gradient Bandit (LB-SGB) matches the sample complexity of SGB, but also converges (at a slower rate) without any assumptions on the learning process. We also show a connection between the log-barrier regularization and Natural Policy Gradient, as both exploit the geometry of the policy space by controlling the Fisher information. We validate our theoretical findings through numerical simulations, showing the benefits of the log-barrier regularization.
Impact of Connectivity on Laplacian Representations in Reinforcement Learning
Mar 09, 2026Learning compact state representations in Markov Decision Processes (MDPs) has proven crucial for addressing the curse of dimensionality in large-scale reinforcement learning (RL) problems. Existing principled approaches leverage structural priors on the MDP by constructing state representations as linear combinations of the state-graph Laplacian eigenvectors. When the transition graph is unknown or the state space is prohibitively large, the graph spectral features can be estimated directly via sample trajectories. In this work, we prove an upper bound on the approximation error of linear value function approximation under the learned spectral features. We show how this error scales with the algebraic connectivity of the state-graph, grounding the approximation quality in the topological structure of the MDP. We further bound the error introduced by the eigenvector estimation itself, leading to an end-to-end error decomposition across the representation learning pipeline. Additionally, our expression of the Laplacian operator for the RL setting, although equivalent to existing ones, prevents some common misunderstandings, of which we show some examples from the literature. Our results hold for general (non-uniform) policies without any assumptions on the symmetry of the induced transition kernel. We validate our theoretical findings with numerical simulations on gridworld environments.
Do It for HER: First-Order Temporal Logic Reward Specification in Reinforcement Learning (Extended Version)
Feb 05, 2026In this work, we propose a novel framework for the logical specification of non-Markovian rewards in Markov Decision Processes (MDPs) with large state spaces. Our approach leverages Linear Temporal Logic Modulo Theories over finite traces (LTLfMT), a more expressive extension of classical temporal logic in which predicates are first-order formulas of arbitrary first-order theories rather than simple Boolean variables. This enhanced expressiveness enables the specification of complex tasks over unstructured and heterogeneous data domains, promoting a unified and reusable framework that eliminates the need for manual predicate encoding. However, the increased expressive power of LTLfMT introduces additional theoretical and computational challenges compared to standard LTLf specifications. We address these challenges from a theoretical standpoint, identifying a fragment of LTLfMT that is tractable but sufficiently expressive for reward specification in an infinite-state-space context. From a practical perspective, we introduce a method based on reward machines and Hindsight Experience Replay (HER) to translate first-order logic specifications and address reward sparsity. We evaluate this approach to a continuous-control setting using Non-Linear Arithmetic Theory, showing that it enables natural specification of complex tasks. Experimental results show how a tailored implementation of HER is fundamental in solving tasks with complex goals.
Reusing Trajectories in Policy Gradients Enables Fast Convergence
Jun 06, 2025



Policy gradient (PG) methods are a class of effective reinforcement learning algorithms, particularly when dealing with continuous control problems. These methods learn the parameters of parametric policies via stochastic gradient ascent, typically using on-policy trajectory data to estimate the policy gradient. However, such reliance on fresh data makes them sample-inefficient. Indeed, vanilla PG methods require $O(\epsilon^{-2})$ trajectories to reach an $\epsilon$-approximate stationary point. A common strategy to improve efficiency is to reuse off-policy information from past iterations, such as previous gradients or trajectories. While gradient reuse has received substantial theoretical attention, leading to improved rates of $O(\epsilon^{-3/2})$, the reuse of past trajectories remains largely unexplored from a theoretical perspective. In this work, we provide the first rigorous theoretical evidence that extensive reuse of past off-policy trajectories can significantly accelerate convergence in PG methods. We introduce a power mean correction to the multiple importance weighting estimator and propose RPG (Retrospective Policy Gradient), a PG algorithm that combines old and new trajectories for policy updates. Through a novel analysis, we show that, under established assumptions, RPG achieves a sample complexity of $\widetilde{O}(\epsilon^{-1})$, the best known rate in the literature. We further validate empirically our approach against PG methods with state-of-the-art rates.
Learning Deterministic Policies with Policy Gradients in Constrained Markov Decision Processes
Jun 06, 2025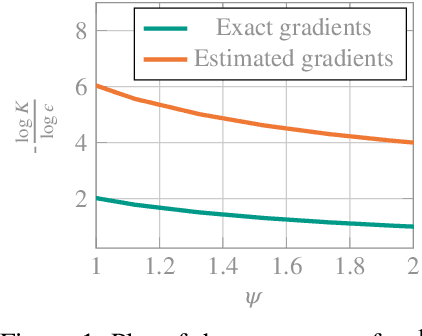



Constrained Reinforcement Learning (CRL) addresses sequential decision-making problems where agents are required to achieve goals by maximizing the expected return while meeting domain-specific constraints. In this setting, policy-based methods are widely used thanks to their advantages when dealing with continuous-control problems. These methods search in the policy space with an action-based or a parameter-based exploration strategy, depending on whether they learn the parameters of a stochastic policy or those of a stochastic hyperpolicy. We introduce an exploration-agnostic algorithm, called C-PG, which enjoys global last-iterate convergence guarantees under gradient domination assumptions. Furthermore, under specific noise models where the (hyper)policy is expressed as a stochastic perturbation of the actions or of the parameters of an underlying deterministic policy, we additionally establish global last-iterate convergence guarantees of C-PG to the optimal deterministic policy. This holds when learning a stochastic (hyper)policy and subsequently switching off the stochasticity at the end of training, thereby deploying a deterministic policy. Finally, we empirically validate both the action-based (C-PGAE) and parameter-based (C-PGPE) variants of C-PG on constrained control tasks, and compare them against state-of-the-art baselines, demonstrating their effectiveness, in particular when deploying deterministic policies after training.
Statistical Analysis of Policy Space Compression Problem
Nov 15, 2024Policy search methods are crucial in reinforcement learning, offering a framework to address continuous state-action and partially observable problems. However, the complexity of exploring vast policy spaces can lead to significant inefficiencies. Reducing the policy space through policy compression emerges as a powerful, reward-free approach to accelerate the learning process. This technique condenses the policy space into a smaller, representative set while maintaining most of the original effectiveness. Our research focuses on determining the necessary sample size to learn this compressed set accurately. We employ R\'enyi divergence to measure the similarity between true and estimated policy distributions, establishing error bounds for good approximations. To simplify the analysis, we employ the $l_1$ norm, determining sample size requirements for both model-based and model-free settings. Finally, we correlate the error bounds from the $l_1$ norm with those from R\'enyi divergence, distinguishing between policies near the vertices and those in the middle of the policy space, to determine the lower and upper bounds for the required sample sizes.
Local Linearity: the Key for No-regret Reinforcement Learning in Continuous MDPs
Oct 31, 2024Achieving the no-regret property for Reinforcement Learning (RL) problems in continuous state and action-space environments is one of the major open problems in the field. Existing solutions either work under very specific assumptions or achieve bounds that are vacuous in some regimes. Furthermore, many structural assumptions are known to suffer from a provably unavoidable exponential dependence on the time horizon $H$ in the regret, which makes any possible solution unfeasible in practice. In this paper, we identify local linearity as the feature that makes Markov Decision Processes (MDPs) both learnable (sublinear regret) and feasible (regret that is polynomial in $H$). We define a novel MDP representation class, namely Locally Linearizable MDPs, generalizing other representation classes like Linear MDPs and MDPS with low inherent Belmman error. Then, i) we introduce Cinderella, a no-regret algorithm for this general representation class, and ii) we show that all known learnable and feasible MDP families are representable in this class. We first show that all known feasible MDPs belong to a family that we call Mildly Smooth MDPs. Then, we show how any mildly smooth MDP can be represented as a Locally Linearizable MDP by an appropriate choice of representation. This way, Cinderella is shown to achieve state-of-the-art regret bounds for all previously known (and some new) continuous MDPs for which RL is learnable and feasible.
Last-Iterate Global Convergence of Policy Gradients for Constrained Reinforcement Learning
Jul 15, 2024Constrained Reinforcement Learning (CRL) tackles sequential decision-making problems where agents are required to achieve goals by maximizing the expected return while meeting domain-specific constraints, which are often formulated as expected costs. In this setting, policy-based methods are widely used since they come with several advantages when dealing with continuous-control problems. These methods search in the policy space with an action-based or parameter-based exploration strategy, depending on whether they learn directly the parameters of a stochastic policy or those of a stochastic hyperpolicy. In this paper, we propose a general framework for addressing CRL problems via gradient-based primal-dual algorithms, relying on an alternate ascent/descent scheme with dual-variable regularization. We introduce an exploration-agnostic algorithm, called C-PG, which exhibits global last-iterate convergence guarantees under (weak) gradient domination assumptions, improving and generalizing existing results. Then, we design C-PGAE and C-PGPE, the action-based and the parameter-based versions of C-PG, respectively, and we illustrate how they naturally extend to constraints defined in terms of risk measures over the costs, as it is often requested in safety-critical scenarios. Finally, we numerically validate our algorithms on constrained control problems, and compare them with state-of-the-art baselines, demonstrating their effectiveness.
Projection by Convolution: Optimal Sample Complexity for Reinforcement Learning in Continuous-Space MDPs
May 10, 2024We consider the problem of learning an $\varepsilon$-optimal policy in a general class of continuous-space Markov decision processes (MDPs) having smooth Bellman operators. Given access to a generative model, we achieve rate-optimal sample complexity by performing a simple, \emph{perturbed} version of least-squares value iteration with orthogonal trigonometric polynomials as features. Key to our solution is a novel projection technique based on ideas from harmonic analysis. Our~$\widetilde{\mathcal{O}}(\epsilon^{-2-d/(\nu+1)})$ sample complexity, where $d$ is the dimension of the state-action space and $\nu$ the order of smoothness, recovers the state-of-the-art result of discretization approaches for the special case of Lipschitz MDPs $(\nu=0)$. At the same time, for $\nu\to\infty$, it recovers and greatly generalizes the $\mathcal{O}(\epsilon^{-2})$ rate of low-rank MDPs, which are more amenable to regression approaches. In this sense, our result bridges the gap between two popular but conflicting perspectives on continuous-space MDPs.
Policy Gradient with Active Importance Sampling
May 09, 2024



Importance sampling (IS) represents a fundamental technique for a large surge of off-policy reinforcement learning approaches. Policy gradient (PG) methods, in particular, significantly benefit from IS, enabling the effective reuse of previously collected samples, thus increasing sample efficiency. However, classically, IS is employed in RL as a passive tool for re-weighting historical samples. However, the statistical community employs IS as an active tool combined with the use of behavioral distributions that allow the reduction of the estimate variance even below the sample mean one. In this paper, we focus on this second setting by addressing the behavioral policy optimization (BPO) problem. We look for the best behavioral policy from which to collect samples to reduce the policy gradient variance as much as possible. We provide an iterative algorithm that alternates between the cross-entropy estimation of the minimum-variance behavioral policy and the actual policy optimization, leveraging on defensive IS. We theoretically analyze such an algorithm, showing that it enjoys a convergence rate of order $O(\epsilon^{-4})$ to a stationary point, but depending on a more convenient variance term w.r.t. standard PG methods. We then provide a practical version that is numerically validated, showing the advantages in the policy gradient estimation variance and on the learning speed.