 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning from Human Feedback via Bayesian Preference Inference
Nov 06, 2025



Learning from human preferences is a cornerstone of aligning machine learning models with subjective human judgments. Yet, collecting such preference data is often costly and time-consuming, motivating the need for more efficient learning paradigms. Two established approaches offer complementary advantages: RLHF scales effectively to high-dimensional tasks such as LLM fine-tuning, while PBO achieves greater sample efficiency through active querying. We propose a hybrid framework that unifies RLHF's scalability with PBO's query efficiency by integrating an acquisition-driven module into the RLHF pipeline, thereby enabling active and sample-efficient preference gathering. We validate the proposed approach on two representative domains: (i) high-dimensional preference optimization and (ii) LLM fine-tuning. Experimental results demonstrate consistent improvements in both sample efficiency and overall performance across these tasks.
Regularized GLISp for sensor-guided human-in-the-loop optimization
Nov 06, 2025Human-in-the-loop calibration is often addressed via preference-based optimization, where algorithms learn from pairwise comparisons rather than explicit cost evaluations. While effective, methods such as Preferential Bayesian Optimization or Global optimization based on active preference learning with radial basis functions (GLISp) treat the system as a black box and ignore informative sensor measurements. In this work, we introduce a sensor-guided regularized extension of GLISp that integrates measurable descriptors into the preference-learning loop through a physics-informed hypothesis function and a least-squares regularization term. This injects grey-box structure, combining subjective feedback with quantitative sensor information while preserving the flexibility of preference-based search. Numerical evaluations on an analytical benchmark and on a human-in-the-loop vehicle suspension tuning task show faster convergence and superior final solutions compared to baseline GLISp.
In-Context Learning for Zero-Shot Speed Estimation of BLDC motors
Apr 01, 2025Accurate speed estimation in sensorless brushless DC motors is essential for high-performance control and monitoring, yet conventional model-based approaches struggle with system nonlinearities and parameter uncertainties. In this work, we propose an in-context learning framework leveraging transformer-based models to perform zero-shot speed estimation using only electrical measurements. By training the filter offline on simulated motor trajectories, we enable real-time inference on unseen real motors without retraining, eliminating the need for explicit system identification while retaining adaptability to varying operating conditions. Experimental results demonstrate that our method outperforms traditional Kalman filter-based estimators, especially in low-speed regimes that are crucial during motor startup.
Automating the loop in traffic incident management on highway
Mar 15, 2025



Effective traffic incident management is essential for ensuring safety, minimizing congestion, and reducing response times in emergency situations. Traditional highway incident management relies heavily on radio room operators, who must make rapid, informed decisions in high-stakes environments. This paper proposes an innovative solution to support and enhance these decisions by integrating Large Language Models (LLMs) into a decision-support system for traffic incident management. We introduce two approaches: (1) an LLM + Optimization hybrid that leverages both the flexibility of natural language interaction and the robustness of optimization techniques, and (2) a Full LLM approach that autonomously generates decisions using only LLM capabilities. We tested our solutions using historical event data from Autostrade per l'Italia. Experimental results indicate that while both approaches show promise, the LLM + Optimization solution demonstrates superior reliability, making it particularly suited to critical applications where consistency and accuracy are paramount. This research highlights the potential for LLMs to transform highway incident management by enabling accessible, data-driven decision-making support.
Sentiment-driven prediction of financial returns: a Bayesian-enhanced FinBERT approach
Mar 07, 2024


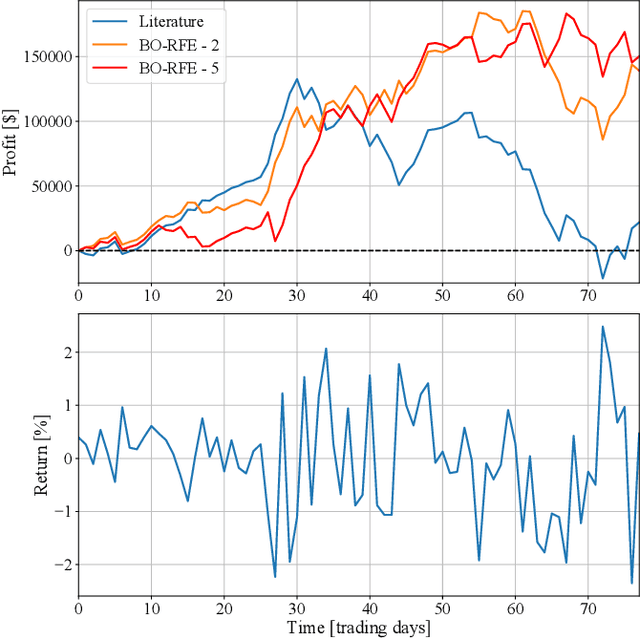
Predicting financial returns accurately poses a significant challenge due to the inherent uncertainty in financial time series data. Enhancing prediction models' performance hinges on effectively capturing both social and financial sentiment. In this study, we showcase the efficacy of leveraging sentiment information extracted from tweets using the FinBERT large language model. By meticulously curating an optimal feature set through correlation analysis and employing Bayesian-optimized Recursive Feature Elimination for automatic feature selection, we surpass existing methodologies, achieving an F1-score exceeding 70% on the test set. This success translates into demonstrably higher cumulative profits during backtested trading. Our investigation focuses on real-world SPY ETF data alongside corresponding tweets sourced from the StockTwits platform.
Explainable data-driven modeling via mixture of experts: towards effective blending of grey and black-box models
Jan 30, 2024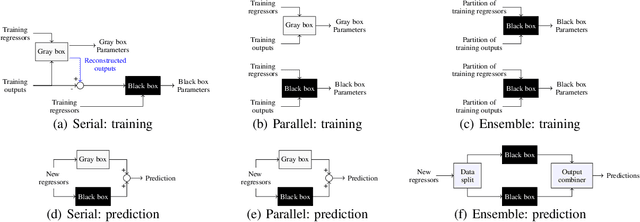

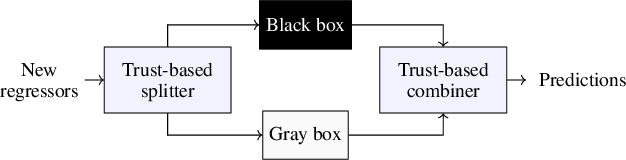

Traditional models grounded in first principles often struggle with accuracy as the system's complexity increases. Conversely, machine learning approaches, while powerful, face challenges in interpretability and in handling physical constraints. Efforts to combine these models often often stumble upon difficulties in finding a balance between accuracy and complexity. To address these issues, we propose a comprehensive framework based on a "mixture of experts" rationale. This approach enables the data-based fusion of diverse local models, leveraging the full potential of first-principle-based priors. Our solution allows independent training of experts, drawing on techniques from both machine learning and system identification, and it supports both collaborative and competitive learning paradigms. To enhance interpretability, we penalize abrupt variations in the expert's combination. Experimental results validate the effectiveness of our approach in producing an interpretable combination of models closely resembling the target phenomena.
Automatic dimensionality reduction of Twin-in-the-Loop Observers
Jan 18, 2024
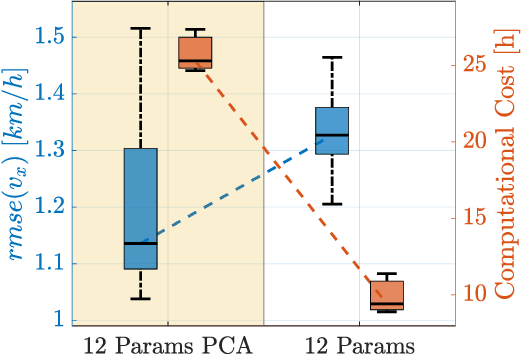


State-of-the-art vehicle dynamics estimation techniques usually share one common drawback: each variable to estimate is computed with an independent, simplified filtering module. These modules run in parallel and need to be calibrated separately. To solve this issue, a unified Twin-in-the-Loop (TiL) Observer architecture has recently been proposed: the classical simplified control-oriented vehicle model in the estimators is replaced by a full-fledged vehicle simulator, or digital twin (DT). The states of the DT are corrected in real time with a linear time invariant output error law. Since the simulator is a black-box, no explicit analytical formulation is available, hence classical filter tuning techniques cannot be used. Due to this reason, Bayesian Optimization will be used to solve a data-driven optimization problem to tune the filter. Due to the complexity of the DT, the optimization problem is high-dimensional. This paper aims to find a procedure to tune the high-complexity observer by lowering its dimensionality. In particular, in this work we will analyze both a supervised and an unsupervised learning approach. The strategies have been validated for speed and yaw-rate estimation on real-world data.
Hawkes-based cryptocurrency forecasting via Limit Order Book data
Dec 21, 2023Accurately forecasting the direction of financial returns poses a formidable challenge, given the inherent unpredictability of financial time series. The task becomes even more arduous when applied to cryptocurrency returns, given the chaotic and intricately complex nature of crypto markets. In this study, we present a novel prediction algorithm using limit order book (LOB) data rooted in the Hawkes model, a category of point processes. Coupled with a continuous output error (COE) model, our approach offers a precise forecast of return signs by leveraging predictions of future financial interactions. Capitalizing on the non-uniformly sampled structure of the original time series, our strategy surpasses benchmark models in both prediction accuracy and cumulative profit when implemented in a trading environment. The efficacy of our approach is validated through Monte Carlo simulations across 50 scenarios. The research draws on LOB measurements from a centralized cryptocurrency exchange where the stablecoin Tether is exchanged against the U.S. dollar.
Unraveling the Control Engineer's Craft with Neural Networks
Nov 20, 2023Many industrial processes require suitable controllers to meet their performance requirements. More often, a sophisticated digital twin is available, which is a highly complex model that is a virtual representation of a given physical process, whose parameters may not be properly tuned to capture the variations in the physical process. In this paper, we present a sim2real, direct data-driven controller tuning approach, where the digital twin is used to generate input-output data and suitable controllers for several perturbations in its parameters. State-of-the art neural-network architectures are then used to learn the controller tuning rule that maps input-output data onto the controller parameters, based on artificially generated data from perturbed versions of the digital twin. In this way, as far as we are aware, we tackle for the first time the problem of re-calibrating the controller by meta-learning the tuning rule directly from data, thus practically replacing the control engineer with a machine learning model. The benefits of this methodology are illustrated via numerical simulations for several choices of neural-network architectures.
Split-Boost Neural Networks
Sep 06, 2023



The calibration and training of a neural network is a complex and time-consuming procedure that requires significant computational resources to achieve satisfactory results. Key obstacles are a large number of hyperparameters to select and the onset of overfitting in the face of a small amount of data. In this framework, we propose an innovative training strategy for feed-forward architectures - called split-boost - that improves performance and automatically includes a regularizing behaviour without modeling it explicitly. Such a novel approach ultimately allows us to avoid explicitly modeling the regularization term, decreasing the total number of hyperparameters and speeding up the tuning phase. The proposed strategy is tested on a real-world (anonymized) dataset within a benchmark medical insurance design problem.