 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear System Identification Nano-drone Benchmark
Dec 16, 2025We introduce a benchmark for system identification based on 75k real-world samples from the Crazyflie 2.1 Brushless nano-quadrotor, a sub-50g aerial vehicle widely adopted in robotics research. The platform presents a challenging testbed due to its multi-input, multi-output nature, open-loop instability, and nonlinear dynamics under agile maneuvers. The dataset comprises four aggressive trajectories with synchronized 4-dimensional motor inputs and 13-dimensional output measurements. To enable fair comparison of identification methods, the benchmark includes a suite of multi-horizon prediction metrics for evaluating both one-step and multi-step error propagation. In addition to the data, we provide a detailed description of the platform and experimental setup, as well as baseline models highlighting the challenge of accurate prediction under real-world noise and actuation nonlinearities. All data, scripts, and reference implementations are released as open-source at https://github.com/idsia-robotics/nanodrone-sysid-benchmark to facilitate transparent comparison of algorithms and support research on agile, miniaturized aerial robotics.
Enhanced Transformer architecture for in-context learning of dynamical systems
Oct 04, 2024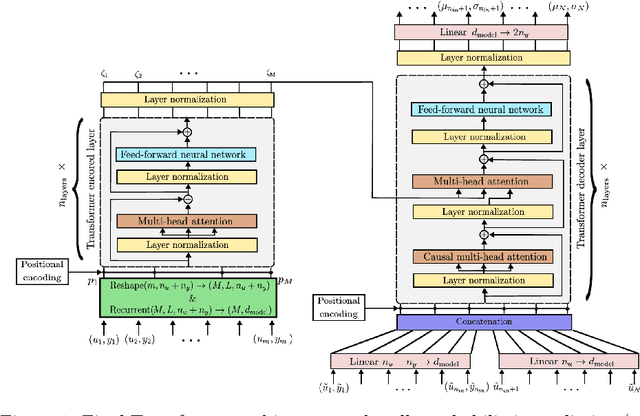

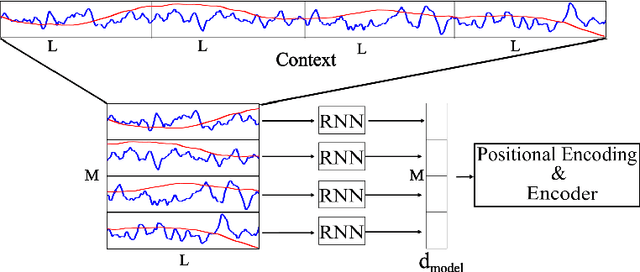

Recently introduced by some of the authors, the in-context identification paradigm aims at estimating, offline and based on synthetic data, a meta-model that describes the behavior of a whole class of systems. Once trained, this meta-model is fed with an observed input/output sequence (context) generated by a real system to predict its behavior in a zero-shot learning fashion. In this paper, we enhance the original meta-modeling framework through three key innovations: by formulating the learning task within a probabilistic framework; by managing non-contiguous context and query windows; and by adopting recurrent patching to effectively handle long context sequences. The efficacy of these modifications is demonstrated through a numerical example focusing on the Wiener-Hammerstein system class, highlighting the model's enhanced performance and scalability.
LightCPPgen: An Explainable Machine Learning Pipeline for Rational Design of Cell Penetrating Peptides
May 31, 2024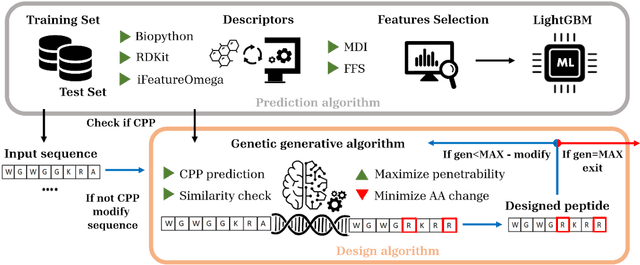
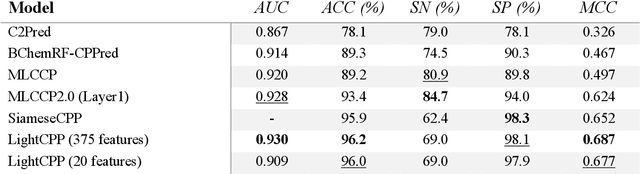
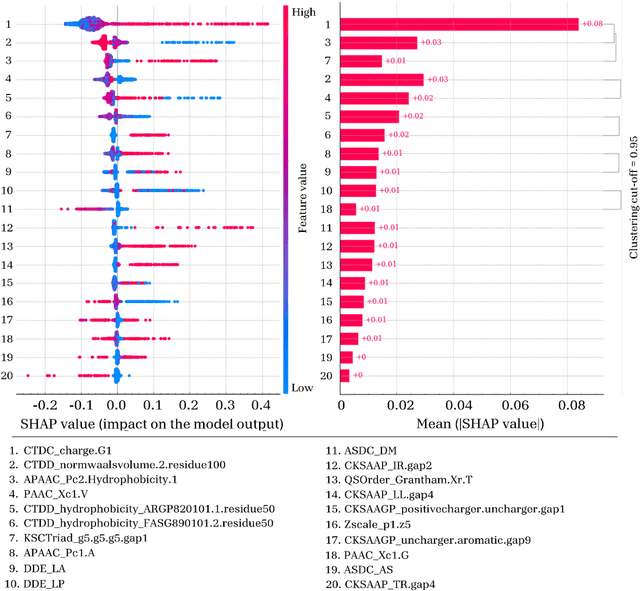
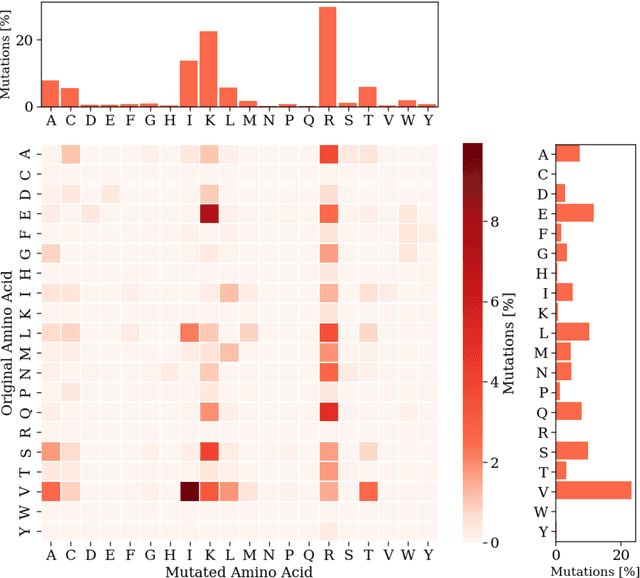
Cell-penetrating peptides (CPPs) are powerful vectors for the intracellular delivery of a diverse array of therapeutic molecules. Despite their potential, the rational design of CPPs remains a challenging task that often requires extensive experimental efforts and iterations. In this study, we introduce an innovative approach for the de novo design of CPPs, leveraging the strengths of machine learning (ML) and optimization algorithms. Our strategy, named LightCPPgen, integrates a LightGBM-based predictive model with a genetic algorithm (GA), enabling the systematic generation and optimization of CPP sequences. At the core of our methodology is the development of an accurate, efficient, and interpretable predictive model, which utilizes 20 explainable features to shed light on the critical factors influencing CPP translocation capacity. The CPP predictive model works synergistically with an optimization algorithm, which is tuned to enhance computational efficiency while maintaining optimization performance. The GA solutions specifically target the candidate sequences' penetrability score, while trying to maximize similarity with the original non-penetrating peptide in order to retain its original biological and physicochemical properties. By prioritizing the synthesis of only the most promising CPP candidates, LightCPPgen can drastically reduce the time and cost associated with wet lab experiments. In summary, our research makes a substantial contribution to the field of CPP design, offering a robust framework that combines ML and optimization techniques to facilitate the rational design of penetrating peptides, by enhancing the explainability and interpretability of the design process.
Synthetic data generation for system identification: leveraging knowledge transfer from similar systems
Mar 08, 2024This paper addresses the challenge of overfitting in the learning of dynamical systems by introducing a novel approach for the generation of synthetic data, aimed at enhancing model generalization and robustness in scenarios characterized by data scarcity. Central to the proposed methodology is the concept of knowledge transfer from systems within the same class. Specifically, synthetic data is generated through a pre-trained meta-model that describes a broad class of systems to which the system of interest is assumed to belong. Training data serves a dual purpose: firstly, as input to the pre-trained meta model to discern the system's dynamics, enabling the prediction of its behavior and thereby generating synthetic output sequences for new input sequences; secondly, in conjunction with synthetic data, to define the loss function used for model estimation. A validation dataset is used to tune a scalar hyper-parameter balancing the relative importance of training and synthetic data in the definition of the loss function. The same validation set can be also used for other purposes, such as early stopping during the training, fundamental to avoid overfitting in case of small-size training datasets. The efficacy of the approach is shown through a numerical example that highlights the advantages of integrating synthetic data into the system identification process.
Gradient-based bilevel optimization for multi-penalty Ridge regression through matrix differential calculus
Nov 23, 2023Common regularization algorithms for linear regression, such as LASSO and Ridge regression, rely on a regularization hyperparameter that balances the tradeoff between minimizing the fitting error and the norm of the learned model coefficients. As this hyperparameter is scalar, it can be easily selected via random or grid search optimizing a cross-validation criterion. However, using a scalar hyperparameter limits the algorithm's flexibility and potential for better generalization. In this paper, we address the problem of linear regression with l2-regularization, where a different regularization hyperparameter is associated with each input variable. We optimize these hyperparameters using a gradient-based approach, wherein the gradient of a cross-validation criterion with respect to the regularization hyperparameters is computed analytically through matrix differential calculus. Additionally, we introduce two strategies tailored for sparse model learning problems aiming at reducing the risk of overfitting to the validation data. Numerical examples demonstrate that our multi-hyperparameter regularization approach outperforms LASSO, Ridge, and Elastic Net regression. Moreover, the analytical computation of the gradient proves to be more efficient in terms of computational time compared to automatic differentiation, especially when handling a large number of input variables. Application to the identification of over-parameterized Linear Parameter-Varying models is also presented.
Split-Boost Neural Networks
Sep 06, 2023



The calibration and training of a neural network is a complex and time-consuming procedure that requires significant computational resources to achieve satisfactory results. Key obstacles are a large number of hyperparameters to select and the onset of overfitting in the face of a small amount of data. In this framework, we propose an innovative training strategy for feed-forward architectures - called split-boost - that improves performance and automatically includes a regularizing behaviour without modeling it explicitly. Such a novel approach ultimately allows us to avoid explicitly modeling the regularization term, decreasing the total number of hyperparameters and speeding up the tuning phase. The proposed strategy is tested on a real-world (anonymized) dataset within a benchmark medical insurance design problem.