 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment-driven prediction of financial returns: a Bayesian-enhanced FinBERT approach
Mar 07, 2024


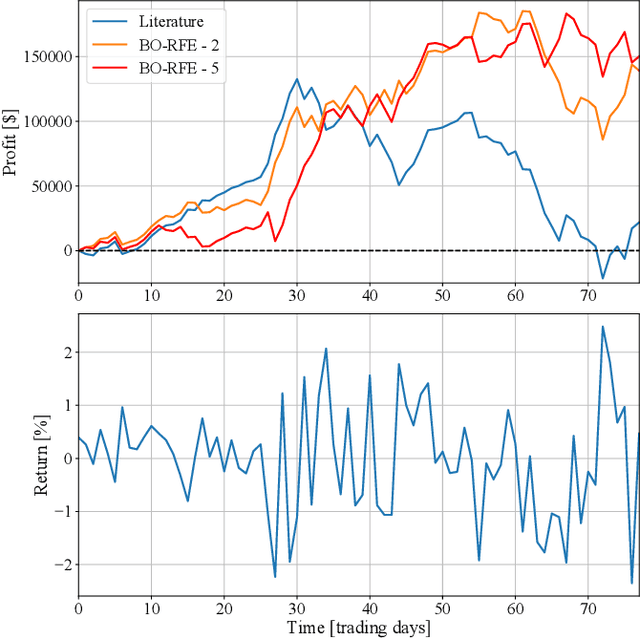
Predicting financial returns accurately poses a significant challenge due to the inherent uncertainty in financial time series data. Enhancing prediction models' performance hinges on effectively capturing both social and financial sentiment. In this study, we showcase the efficacy of leveraging sentiment information extracted from tweets using the FinBERT large language model. By meticulously curating an optimal feature set through correlation analysis and employing Bayesian-optimized Recursive Feature Elimination for automatic feature selection, we surpass existing methodologies, achieving an F1-score exceeding 70% on the test set. This success translates into demonstrably higher cumulative profits during backtested trading. Our investigation focuses on real-world SPY ETF data alongside corresponding tweets sourced from the StockTwits platform.
Hawkes-based cryptocurrency forecasting via Limit Order Book data
Dec 21, 2023Accurately forecasting the direction of financial returns poses a formidable challenge, given the inherent unpredictability of financial time series. The task becomes even more arduous when applied to cryptocurrency returns, given the chaotic and intricately complex nature of crypto markets. In this study, we present a novel prediction algorithm using limit order book (LOB) data rooted in the Hawkes model, a category of point processes. Coupled with a continuous output error (COE) model, our approach offers a precise forecast of return signs by leveraging predictions of future financial interactions. Capitalizing on the non-uniformly sampled structure of the original time series, our strategy surpasses benchmark models in both prediction accuracy and cumulative profit when implemented in a trading environment. The efficacy of our approach is validated through Monte Carlo simulations across 50 scenarios. The research draws on LOB measurements from a centralized cryptocurrency exchange where the stablecoin Tether is exchanged against the U.S. dollar.
Split-Boost Neural Networks
Sep 06, 2023



The calibration and training of a neural network is a complex and time-consuming procedure that requires significant computational resources to achieve satisfactory results. Key obstacles are a large number of hyperparameters to select and the onset of overfitting in the face of a small amount of data. In this framework, we propose an innovative training strategy for feed-forward architectures - called split-boost - that improves performance and automatically includes a regularizing behaviour without modeling it explicitly. Such a novel approach ultimately allows us to avoid explicitly modeling the regularization term, decreasing the total number of hyperparameters and speeding up the tuning phase. The proposed strategy is tested on a real-world (anonymized) dataset within a benchmark medical insurance design problem.
Scenario-based model predictive control of water reservoir systems
Sep 01, 2023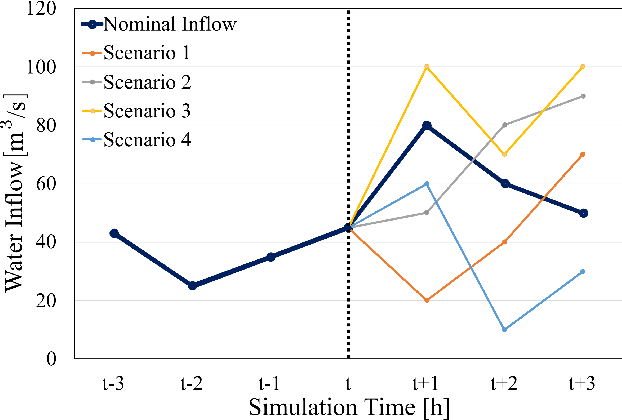
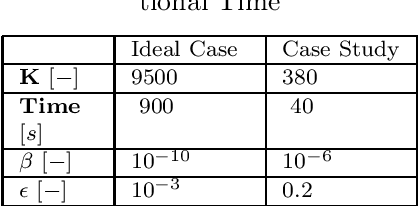
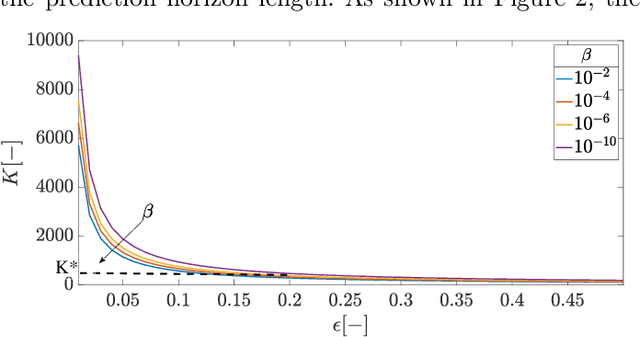
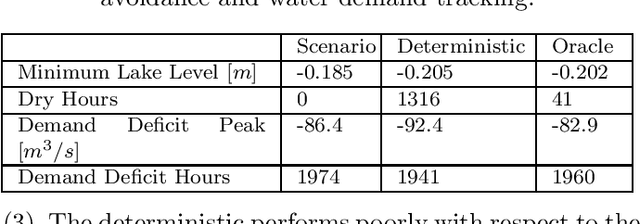
The optimal operation of water reservoir systems is a challenging task involving multiple conflicting objectives. The main source of complexity is the presence of the water inflow, which acts as an exogenous, highly uncertain disturbance on the system. When model predictive control (MPC) is employed, the optimal water release is usually computed based on the (predicted) trajectory of the inflow. This choice may jeopardize the closed-loop performance when the actual inflow differs from its forecast. In this work, we consider - for the first time - a stochastic MPC approach for water reservoirs, in which the control is optimized based on a set of plausible future inflows directly generated from past data. Such a scenario-based MPC strategy allows the controller to be more cautious, counteracting droughty periods (e.g., the lake level going below the dry limit) while at the same time guaranteeing that the agricultural water demand is satisfied. The method's effectiveness is validated through extensive Monte Carlo tests using actual inflow data from Lake Como, Italy.