 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold meta-learning for reduced-complexity neural system identification
Apr 16, 2025



System identification has greatly benefited from deep learning techniques, particularly for modeling complex, nonlinear dynamical systems with partially unknown physics where traditional approaches may not be feasible. However, deep learning models often require large datasets and significant computational resources at training and inference due to their high-dimensional parameterizations. To address this challenge, we propose a meta-learning framework that discovers a low-dimensional manifold within the parameter space of an over-parameterized neural network architecture. This manifold is learned from a meta-dataset of input-output sequences generated by a class of related dynamical systems, enabling efficient model training while preserving the network's expressive power for the considered system class. Unlike bilevel meta-learning approaches, our method employs an auxiliary neural network to map datasets directly onto the learned manifold, eliminating the need for costly second-order gradient computations during meta-training and reducing the number of first-order updates required in inference, which could be expensive for large models. We validate our approach on a family of Bouc-Wen oscillators, which is a well-studied nonlinear system identification benchmark. We demonstrate that we are able to learn accurate models even in small-data scenarios.
Enhanced Transformer architecture for in-context learning of dynamical systems
Oct 04, 2024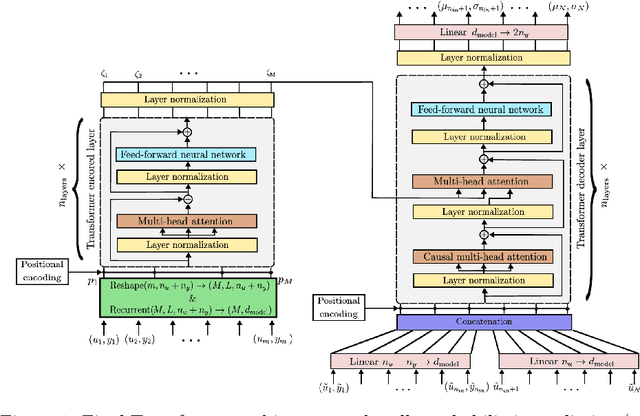

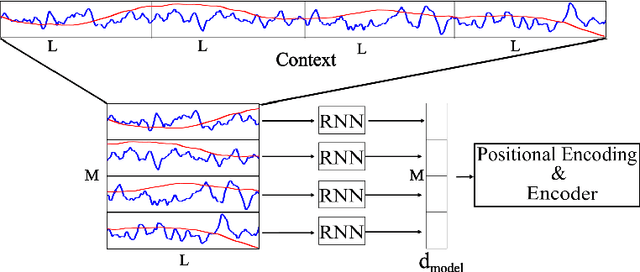

Recently introduced by some of the authors, the in-context identification paradigm aims at estimating, offline and based on synthetic data, a meta-model that describes the behavior of a whole class of systems. Once trained, this meta-model is fed with an observed input/output sequence (context) generated by a real system to predict its behavior in a zero-shot learning fashion. In this paper, we enhance the original meta-modeling framework through three key innovations: by formulating the learning task within a probabilistic framework; by managing non-contiguous context and query windows; and by adopting recurrent patching to effectively handle long context sequences. The efficacy of these modifications is demonstrated through a numerical example focusing on the Wiener-Hammerstein system class, highlighting the model's enhanced performance and scalability.
Synthetic data generation for system identification: leveraging knowledge transfer from similar systems
Mar 08, 2024This paper addresses the challenge of overfitting in the learning of dynamical systems by introducing a novel approach for the generation of synthetic data, aimed at enhancing model generalization and robustness in scenarios characterized by data scarcity. Central to the proposed methodology is the concept of knowledge transfer from systems within the same class. Specifically, synthetic data is generated through a pre-trained meta-model that describes a broad class of systems to which the system of interest is assumed to belong. Training data serves a dual purpose: firstly, as input to the pre-trained meta model to discern the system's dynamics, enabling the prediction of its behavior and thereby generating synthetic output sequences for new input sequences; secondly, in conjunction with synthetic data, to define the loss function used for model estimation. A validation dataset is used to tune a scalar hyper-parameter balancing the relative importance of training and synthetic data in the definition of the loss function. The same validation set can be also used for other purposes, such as early stopping during the training, fundamental to avoid overfitting in case of small-size training datasets. The efficacy of the approach is shown through a numerical example that highlights the advantages of integrating synthetic data into the system identification process.