 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Primal-Dual Online Learning Approach for Dynamic Pricing of Sequentially Displayed Complementary Items under Sale Constraints
Jul 08, 2024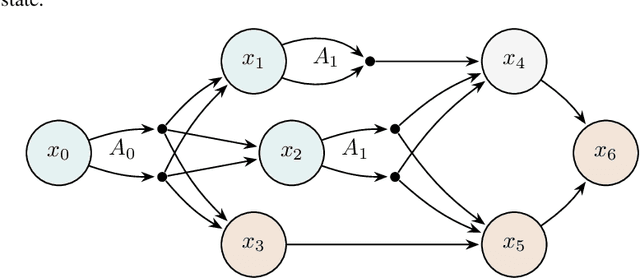

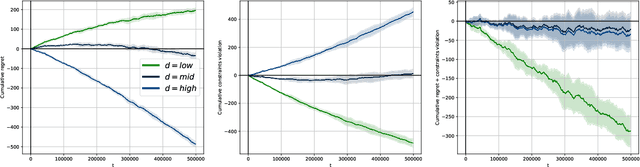
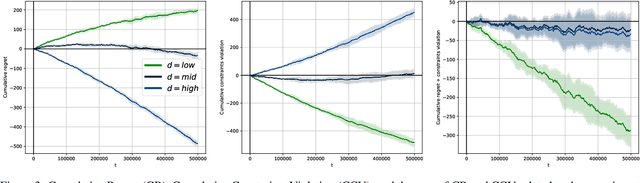
We address the challenging problem of dynamically pricing complementary items that are sequentially displayed to customers. An illustrative example is the online sale of flight tickets, where customers navigate through multiple web pages. Initially, they view the ticket cost, followed by ancillary expenses such as insurance and additional luggage fees. Coherent pricing policies for complementary items are essential because optimizing the pricing of each item individually is ineffective. Our scenario also involves a sales constraint, which specifies a minimum number of items to sell, and uncertainty regarding customer demand curves. To tackle this problem, we originally formulate it as a Markov Decision Process with constraints. Leveraging online learning tools, we design a primal-dual online optimization algorithm. We empirically evaluate our approach using synthetic settings randomly generated from real-world data, covering various configurations from stationary to non-stationary, and compare its performance in terms of constraints violation and regret against well-known baselines optimizing each state singularly.
A survey and taxonomy of loss functions in machine learning
Jan 13, 2023



Most state-of-the-art machine learning techniques revolve around the optimisation of loss functions. Defining appropriate loss functions is therefore critical to successfully solving problems in this field. We present a survey of the most commonly used loss functions for a wide range of different applications, divided into classification, regression, ranking, sample generation and energy based modelling. Overall, we introduce 33 different loss functions and we organise them into an intuitive taxonomy. Each loss function is given a theoretical backing and we describe where it is best used. This survey aims to provide a reference of the most essential loss functions for both beginner and advanced machine learning practitioners.
Maximum entropy exploration in contextual bandits with neural networks and energy based models
Oct 12, 2022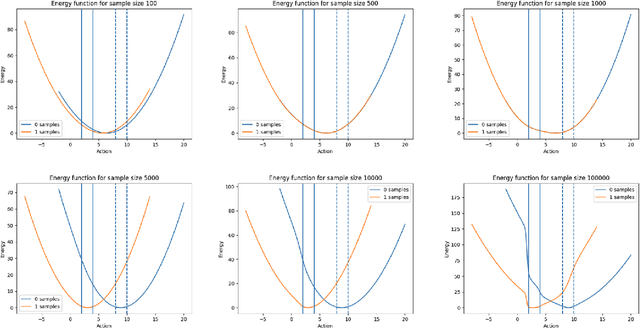

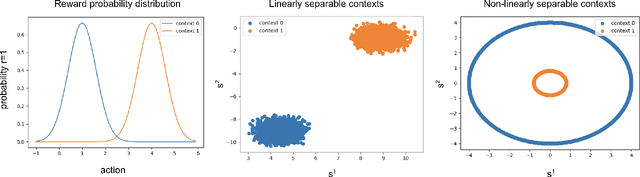
Contextual bandits can solve a huge range of real-world problems. However, current popular algorithms to solve them either rely on linear models, or unreliable uncertainty estimation in non-linear models, which are required to deal with the exploration-exploitation trade-off. Inspired by theories of human cognition, we introduce novel techniques that use maximum entropy exploration, relying on neural networks to find optimal policies in settings with both continuous and discrete action spaces. We present two classes of models, one with neural networks as reward estimators, and the other with energy based models, which model the probability of obtaining an optimal reward given an action. We evaluate the performance of these models in static and dynamic contextual bandit simulation environments. We show that both techniques outperform well-known standard algorithms, where energy based models have the best overall performance. This provides practitioners with new techniques that perform well in static and dynamic settings, and are particularly well suited to non-linear scenarios with continuous action spaces.
Composition and Style Attributes Guided Image Aesthetic Assessment
Nov 08, 2021
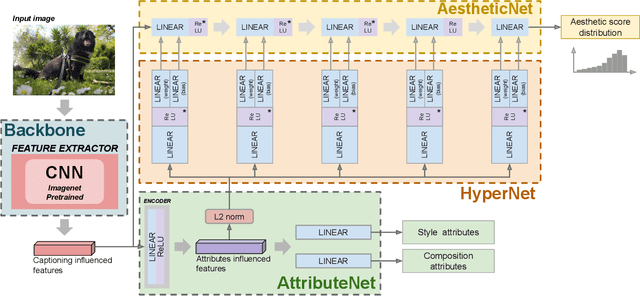

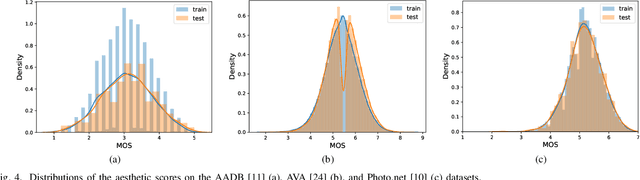
The aesthetic quality of an image is defined as the measure or appreciation of the beauty of an image. Aesthetics is inherently a subjective property but there are certain factors that influence it such as, the semantic content of the image, the attributes describing the artistic aspect, the photographic setup used for the shot, etc. In this paper we propose a method for the automatic prediction of the aesthetics of an image that is based on the analysis of the semantic content, the artistic style and the composition of the image. The proposed network includes: a pre-trained network for semantic features extraction (the Backbone); a Multi Layer Perceptron (MLP) network that relies on the Backbone features for the prediction of image attributes (the AttributeNet); a self-adaptive Hypernetwork that exploits the attributes prior encoded into the embedding generated by the AttributeNet to predict the parameters of the target network dedicated to aesthetic estimation (the AestheticNet). Given an image, the proposed multi-network is able to predict: style and composition attributes, and aesthetic score distribution. Results on three benchmark datasets demonstrate the effectiveness of the proposed method, while the ablation study gives a better understanding of the proposed network.
Ranking Micro-Influencers: a Novel Multi-Task Learning and Interpretable Framework
Jul 29, 2021



With the rise in use of social media to promote branded products, the demand for effective influencer marketing has increased. Brands are looking for improved ways to identify valuable influencers among a vast catalogue; this is even more challenging with "micro-influencers", which are more affordable than mainstream ones but difficult to discover. In this paper, we propose a novel multi-task learning framework to improve the state of the art in micro-influencer ranking based on multimedia content. Moreover, since the visual congruence between a brand and influencer has been shown to be good measure of compatibility, we provide an effective visual method for interpreting our models' decisions, which can also be used to inform brands' media strategies. We compare with the current state-of-the-art on a recently constructed public dataset and we show significant improvement both in terms of accuracy and model complexity. The techniques for ranking and interpretation presented in this work can be generalised to arbitrary multimedia ranking tasks that have datasets with a similar structure.
Graph-Based Neural Network Models with Multiple Self-Supervised Auxiliary Tasks
Dec 04, 2020

Self-supervised learning is currently gaining a lot of attention, as it allows neural networks to learn robust representations from large quantities of unlabeled data. Additionally, multi-task learning can further improve representation learning by training networks simultaneously on related tasks, leading to significant performance improvements. In this paper, we propose three novel self-supervised auxiliary tasks to train graph-based neural network models in a multi-task fashion. Since Graph Convolutional Networks are among the most promising approaches for capturing relationships among structured data points, we use them as a building block to achieve competitive results on standard semi-supervised graph classification tasks.
Learning Combinations of Activation Functions
Jan 29, 2018



In the last decade, an active area of research has been devoted to design novel activation functions that are able to help deep neural networks to converge, obtaining better performance. The training procedure of these architectures usually involves optimization of the weights of their layers only, while non-linearities are generally pre-specified and their (possible) parameters are usually considered as hyper-parameters to be tuned manually. In this paper, we introduce two approaches to automatically learn different combinations of base activation functions (such as the identity function, ReLU, and tanh) during the training phase. We present a thorough comparison of our novel approaches with well-known architectures (such as LeNet-5, AlexNet, and ResNet-56) on three standard datasets (Fashion-MNIST, CIFAR-10, and ILSVRC-2012), showing substantial improvements in the overall performance, such as an increase in the top-1 accuracy for AlexNet on ILSVRC-2012 of 3.01 percentage points.
Automated Pruning for Deep Neural Network Compression
Dec 05, 2017



In this work we present a method to improve the pruning step of the current state-of-the-art methodology to compress neural networks. The novelty of the proposed pruning technique is in its differentiability, which allows pruning to be performed during the backpropagation phase of the network training. This enables an end-to-end learning and strongly reduces the training time. The technique is based on a family of differentiable pruning functions and a new regularizer specifically designed to enforce pruning. The experimental results show that the joint optimization of both the thresholds and the network weights permits to reach a higher compression rate, reducing the number of weights of the pruned network by a further 14% to 33% with respect to the current state-of-the-art. Furthermore, we believe that this is the first study where the generalization capabilities in transfer learning tasks of the features extracted by a pruned network are analyzed. To achieve this goal, we show that the representations learned using the proposed pruning methodology maintain the same effectiveness and generality of those learned by the corresponding non-compressed network on a set of different recognition tasks.
A Cross-Entropy-based Method to Perform Information-based Feature Selection
May 22, 2017
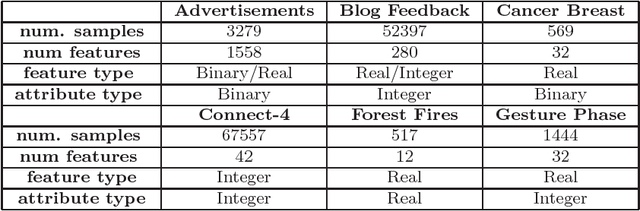
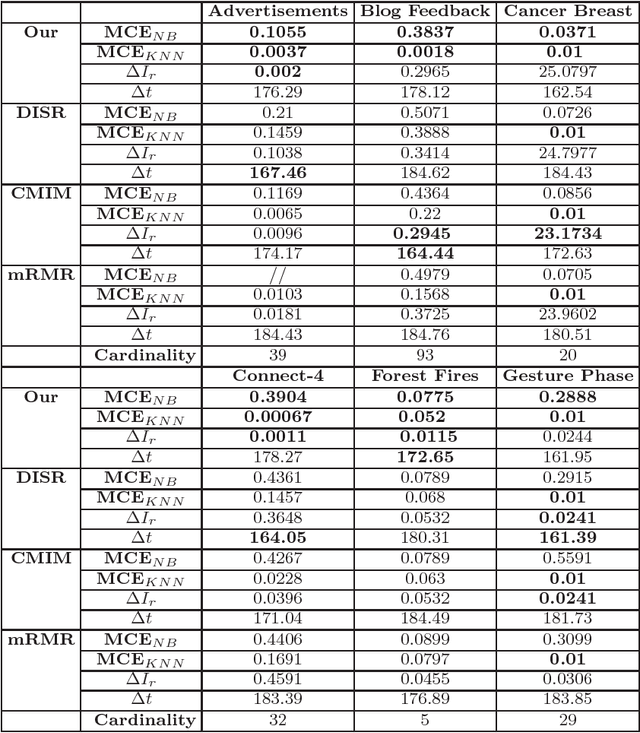
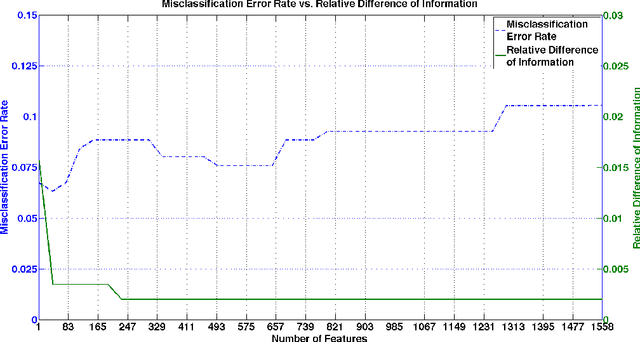
From a machine learning point of view, identifying a subset of relevant features from a real data set can be useful to improve the results achieved by classification methods and to reduce their time and space complexity. To achieve this goal, feature selection methods are usually employed. These approaches assume that the data contains redundant or irrelevant attributes that can be eliminated. In this work, we propose a novel algorithm to manage the optimization problem that is at the foundation of the Mutual Information feature selection methods. Furthermore, our novel approach is able to estimate automatically the number of dimensions to retain. The quality of our method is confirmed by the promising results achieved on standard real data sets.
Dynamic Graph Convolutional Networks
Apr 20, 2017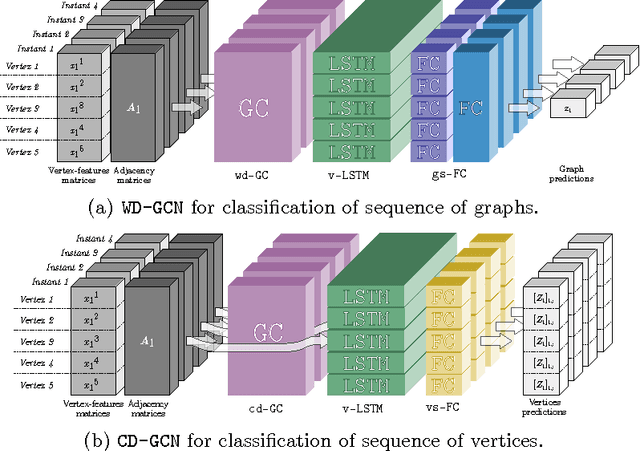
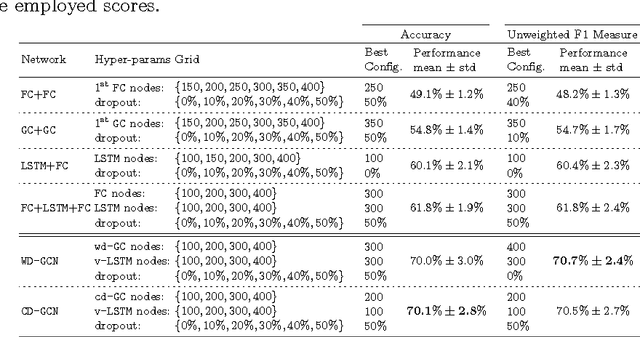
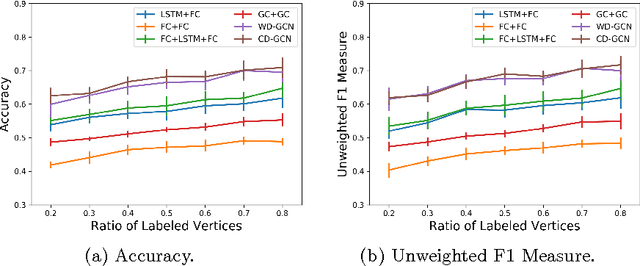
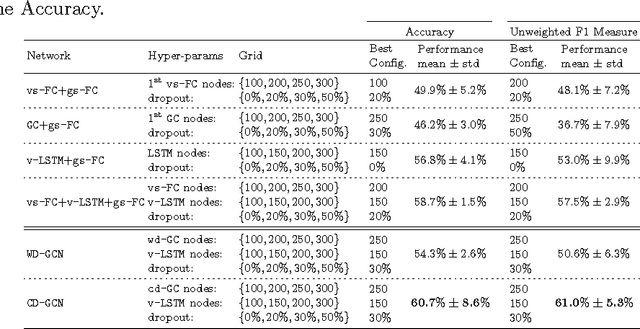
Many different classification tasks need to manage structured data, which are usually modeled as graphs. Moreover, these graphs can be dynamic, meaning that the vertices/edges of each graph may change during time. Our goal is to jointly exploit structured data and temporal information through the use of a neural network model. To the best of our knowledge, this task has not been addressed using these kind of architectures. For this reason, we propose two novel approaches, which combine Long Short-Term Memory networks and Graph Convolutional Networks to learn long short-term dependencies together with graph structure. The quality of our methods is confirmed by the promising results achieved.