 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Multispectral Sensors for Color Correction in Mobile Cameras
Dec 09, 2025Recent advances in snapshot multispectral (MS) imaging have enabled compact, low-cost spectral sensors for consumer and mobile devices. By capturing richer spectral information than conventional RGB sensors, these systems can enhance key imaging tasks, including color correction. However, most existing methods treat the color correction pipeline in separate stages, often discarding MS data early in the process. We propose a unified, learning-based framework that (i) performs end-to-end color correction and (ii) jointly leverages data from a high-resolution RGB sensor and an auxiliary low-resolution MS sensor. Our approach integrates the full pipeline within a single model, producing coherent and color-accurate outputs. We demonstrate the flexibility and generality of our framework by refactoring two different state-of-the-art image-to-image architectures. To support training and evaluation, we construct a dedicated dataset by aggregating and repurposing publicly available spectral datasets, rendering under multiple RGB camera sensitivities. Extensive experiments show that our approach improves color accuracy and stability, reducing error by up to 50% compared to RGB-only and MS-driven baselines. Datasets, code, and models will be made available upon acceptance.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024


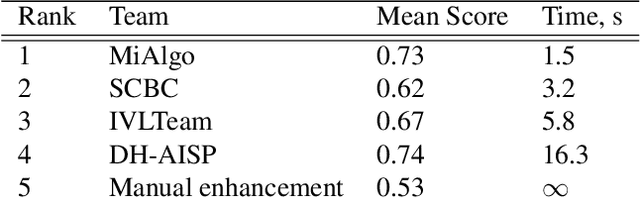
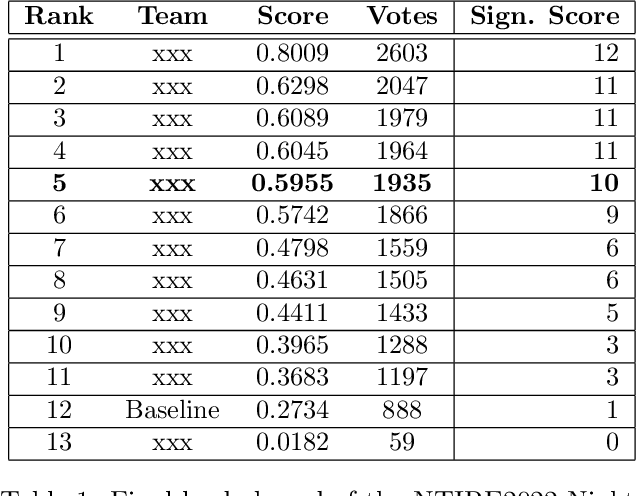
This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
A deep scalable neural architecture for soil properties estimation from spectral information
Oct 26, 2022In this paper we propose an adaptive deep neural architecture for the prediction of multiple soil characteristics from the analysis of hyperspectral signatures. The proposed method overcomes the limitations of previous methods in the state of art: (i) it allows to predict multiple soil variables at once; (ii) it permits to backtrace the spectral bands that most contribute to the estimation of a given variable; (iii) it is based on a flexible neural architecture capable of automatically adapting to the spectral library under analysis. The proposed architecture is experimented on LUCAS, a large laboratory dataset and on a dataset achieved by simulating PRISMA hyperspectral sensor. 'Results, compared with other state-of-the-art methods confirm the effectiveness of the proposed solution.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022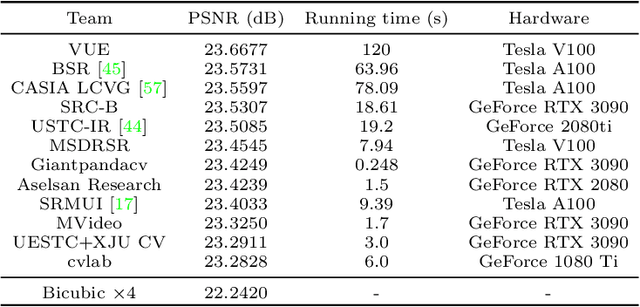

This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
A health telemonitoring platform based on data integration from different sources
Jul 28, 2022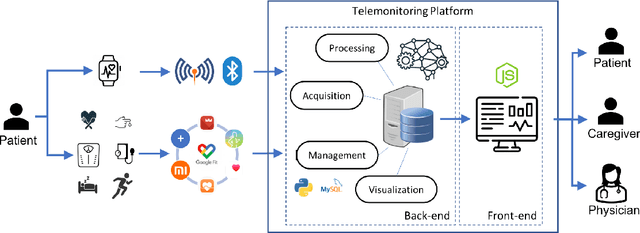
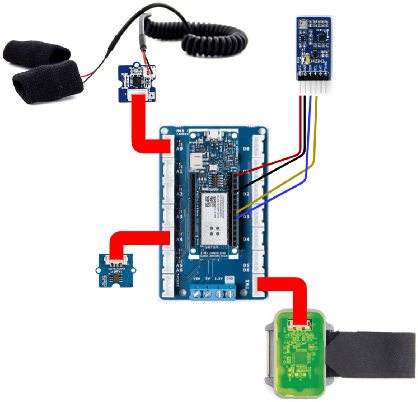
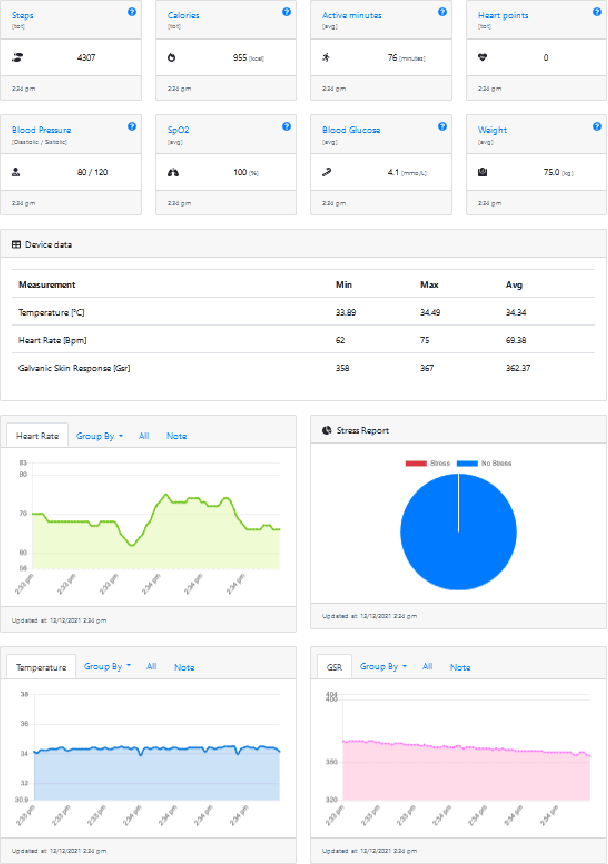
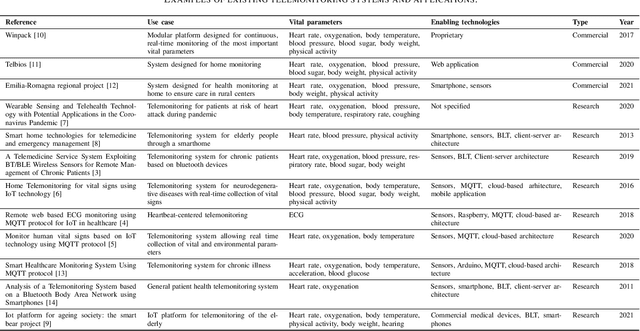
The management of people with long-term or chronic illness is one of the biggest challenges for national health systems. In fact, these diseases are among the leading causes of hospitalization, especially for the elderly, and huge amount of resources required to monitor them leads to problems with sustainability of the healthcare systems. The increasing diffusion of portable devices and new connectivity technologies allows the implementation of telemonitoring system capable of providing support to health care providers and lighten the burden on hospitals and clinics. In this paper, we present the implementation of a telemonitoring platform for healthcare, designed to capture several types of physiological health parameters from different consumer mobile and custom devices. Consumer medical devices can be integrated into the platform via the Google Fit ecosystem that supports hundreds of devices, while custom devices can directly interact with the platform with standard communication protocols. The platform is designed to process the acquired data using machine learning algorithms, and to provide patients and physicians the physiological health parameters with a user-friendly, comprehensive, and easy to understand dashboard which monitors the parameters through time. Preliminary usability tests show a good user satisfaction in terms of functionality and usefulness.
Semi-supervised cross-lingual speech emotion recognition
Jul 14, 2022
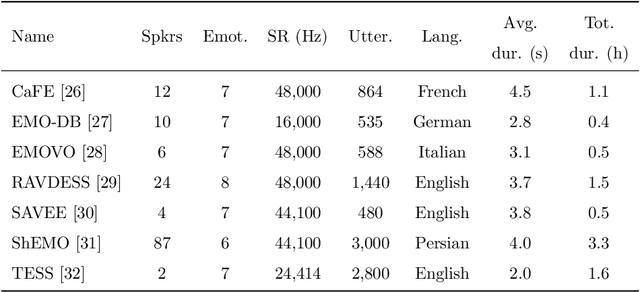
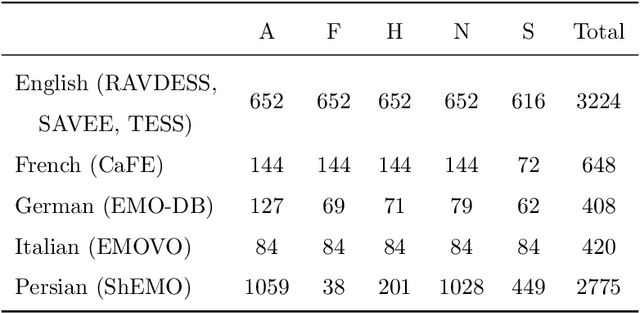
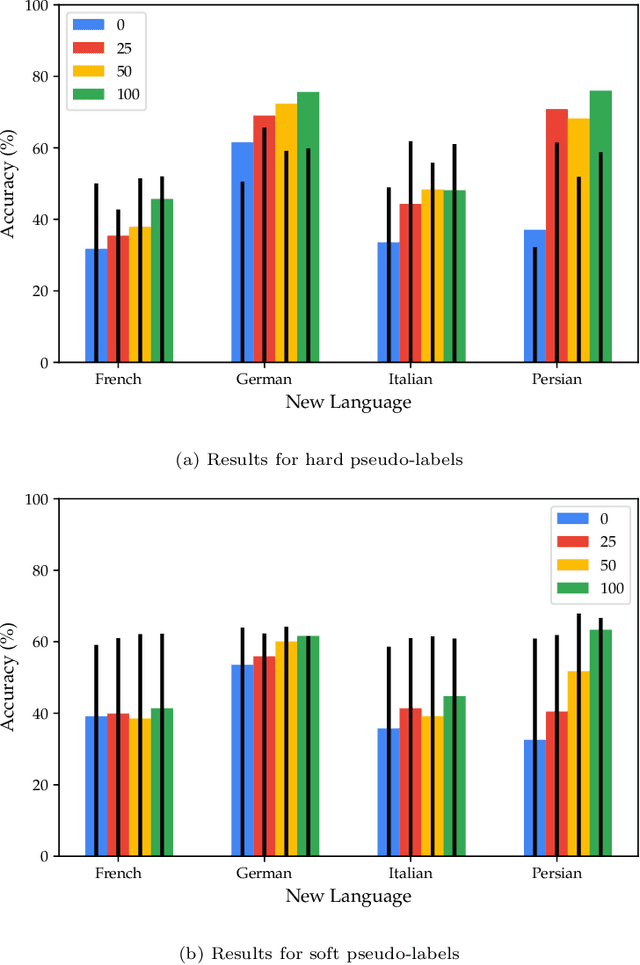
Speech emotion recognition (SER) on a single language has achieved remarkable results through deep learning approaches over the last decade. However, cross-lingual SER remains a challenge in real-world applications due to (i) a large difference between the source and target domain distributions, (ii) the availability of few labeled and many unlabeled utterances for the new language. Taking into account previous aspects, we propose a Semi-Supervised Learning (SSL) method for cross-lingual emotion recognition when a few labels from the new language are available. Based on a Convolutional Neural Network (CNN), our method adapts to a new language by exploiting a pseudo-labeling strategy for the unlabeled utterances. In particular, the use of a hard and soft pseudo-labels approach is investigated. We thoroughly evaluate the performance of the method in a speaker-independent setup on both the source and the new language and show its robustness across five languages belonging to different linguistic strains.
Unsupervised Segmentation of Hyperspectral Remote Sensing Images with Superpixels
Apr 26, 2022
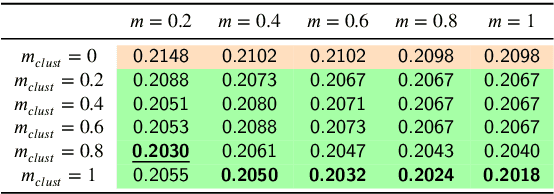
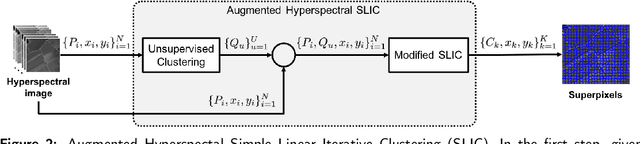
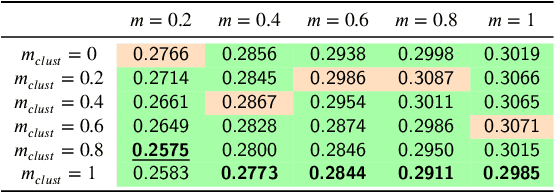
In this paper, we propose an unsupervised method for hyperspectral remote sensing image segmentation. The method exploits the mean-shift clustering algorithm that takes as input a preliminary hyperspectral superpixels segmentation together with the spectral pixel information. The proposed method does not require the number of segmentation classes as input parameter, and it does not exploit any a-priori knowledge about the type of land-cover or land-use to be segmented (e.g. water, vegetation, building etc.). Experiments on Salinas, SalinasA, Pavia Center and Pavia University datasets are carried out. Performance are measured in terms of normalized mutual information, adjusted Rand index and F1-score. Results demonstrate the validity of the proposed method in comparison with the state of the art.
Shallow camera pipeline for night photography rendering
Apr 19, 2022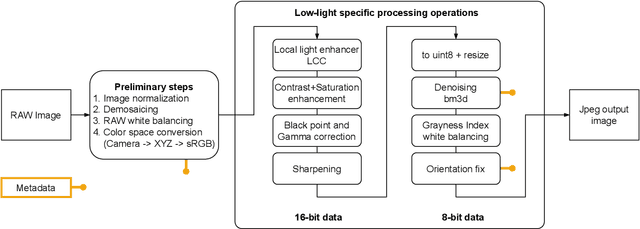
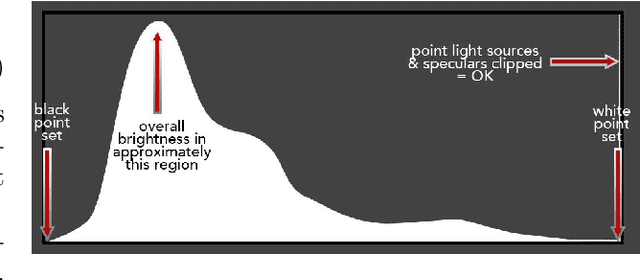

We introduce a camera pipeline for rendering visually pleasing photographs in low light conditions, as part of the NTIRE2022 Night Photography Rendering challenge. Given the nature of the task, where the objective is verbally defined by an expert photographer instead of relying on explicit ground truth images, we design an handcrafted solution, characterized by a shallow structure and by a low parameter count. Our pipeline exploits a local light enhancer as a form of high dynamic range correction, followed by a global adjustment of the image histogram to prevent washed-out results. We proportionally apply image denoising to darker regions, where it is more easily perceived, without losing details on brighter regions. The solution reached the fifth place in the competition, with a preference vote count comparable to those of other entries, based on deep convolutional neural networks. Code is available at www.github.com/AvailableAfterAcceptance.
Illumination Estimation Challenge: experience of past two years
Dec 31, 2020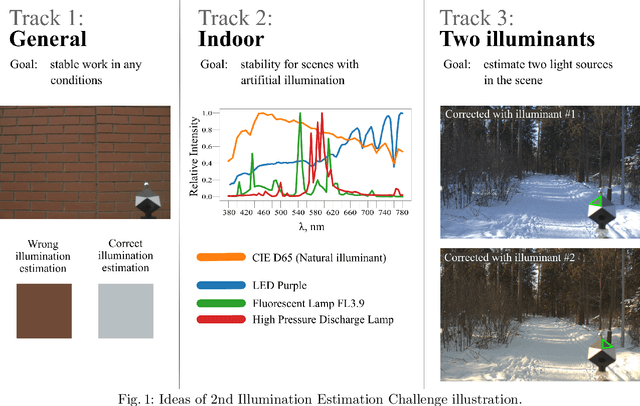
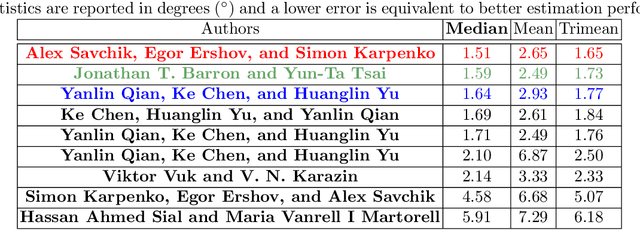

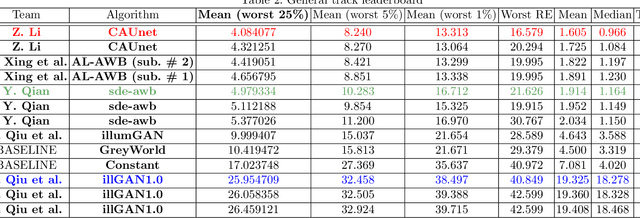
Illumination estimation is the essential step of computational color constancy, one of the core parts of various image processing pipelines of modern digital cameras. Having an accurate and reliable illumination estimation is important for reducing the illumination influence on the image colors. To motivate the generation of new ideas and the development of new algorithms in this field, the 2nd Illumination estimation challenge~(IEC\#2) was conducted. The main advantage of testing a method on a challenge over testing in on some of the known datasets is the fact that the ground-truth illuminations for the challenge test images are unknown up until the results have been submitted, which prevents any potential hyperparameter tuning that may be biased. The challenge had several tracks: general, indoor, and two-illuminant with each of them focusing on different parameters of the scenes. Other main features of it are a new large dataset of images (about 5000) taken with the same camera sensor model, a manual markup accompanying each image, diverse content with scenes taken in numerous countries under a huge variety of illuminations extracted by using the SpyderCube calibration object, and a contest-like markup for the images from the Cube+ dataset that was used in IEC\#1. This paper focuses on the description of the past two challenges, algorithms which won in each track, and the conclusions that were drawn based on the results obtained during the 1st and 2nd challenge that can be useful for similar future developments.