 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024


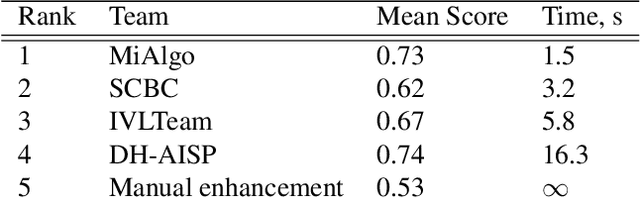
This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
Deep Learning Hyperspectral Pansharpening on large scale PRISMA dataset
Jul 28, 2023In this work, we assess several deep learning strategies for hyperspectral pansharpening. First, we present a new dataset with a greater extent than any other in the state of the art. This dataset, collected using the ASI PRISMA satellite, covers about 262200 km2, and its heterogeneity is granted by randomly sampling the Earth's soil. Second, we adapted several state of the art approaches based on deep learning to fit PRISMA hyperspectral data and then assessed, quantitatively and qualitatively, the performance in this new scenario. The investigation has included two settings: Reduced Resolution (RR) to evaluate the techniques in a supervised environment and Full Resolution (FR) for a real-world evaluation. The main purpose is the evaluation of the reconstruction fidelity of the considered methods. In both scenarios, for the sake of completeness, we also included machine-learning-free approaches. From this extensive analysis has emerged that data-driven neural network methods outperform machine-learning-free approaches and adapt better to the task of hyperspectral pansharpening, both in RR and FR protocols.
Shallow camera pipeline for night photography rendering
Apr 19, 2022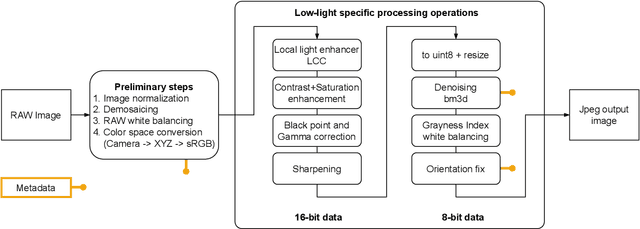
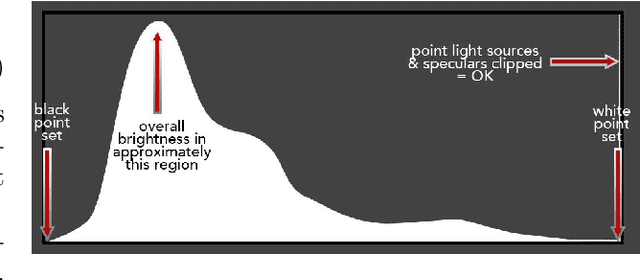

We introduce a camera pipeline for rendering visually pleasing photographs in low light conditions, as part of the NTIRE2022 Night Photography Rendering challenge. Given the nature of the task, where the objective is verbally defined by an expert photographer instead of relying on explicit ground truth images, we design an handcrafted solution, characterized by a shallow structure and by a low parameter count. Our pipeline exploits a local light enhancer as a form of high dynamic range correction, followed by a global adjustment of the image histogram to prevent washed-out results. We proportionally apply image denoising to darker regions, where it is more easily perceived, without losing details on brighter regions. The solution reached the fifth place in the competition, with a preference vote count comparable to those of other entries, based on deep convolutional neural networks. Code is available at www.github.com/AvailableAfterAcceptance.
Planckian jitter: enhancing the color quality of self-supervised visual representations
Feb 16, 2022
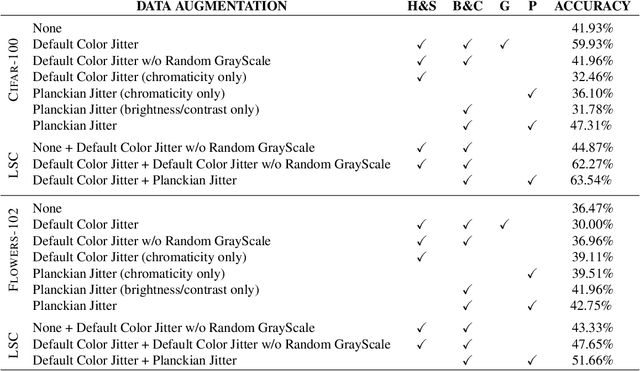
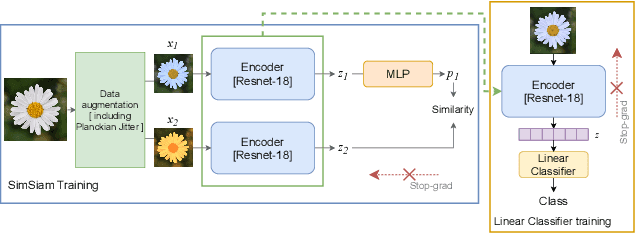
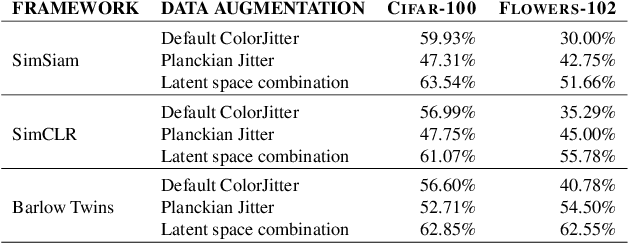
Several recent works on self-supervised learning are trained by mapping different augmentations of the same image to the same feature representation. The set of used data augmentations is of crucial importance for the quality of the learned feature representation. We analyze how the traditionally used color jitter negatively impacts the quality of the color features in the learned feature representation. To address this problem, we replace this module with physics-based color augmentation, called Planckian jitter, which creates realistic variations in chromaticity, producing a model robust to llumination changes that can be commonly observed in real life, while maintaining the ability to discriminate the image content based on color information. We further improve the performance by introducing a latent space combination of color-sensitive and non-color-sensitive features. These are found to be complementary and the combination leads to large absolute performance gains over the default data augmentation on color classification tasks, including on Flowers-102 (+15%), Cub200 (+11%), VegFru (+15%), and T1K+ (+12%). Finally, we present a color sensitivity analysis to document the impact of different training methods on the model neurons and we show that the performance of the learned features is robust with respect to illuminant variations.
Deep Residual Autoencoder for quality independent JPEG restoration
Mar 14, 2019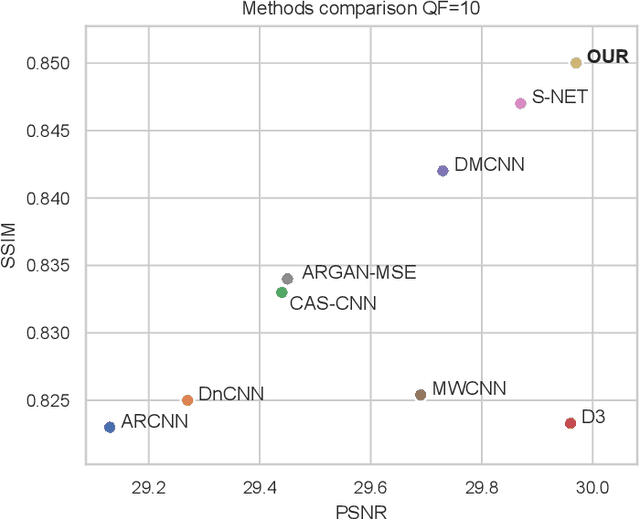
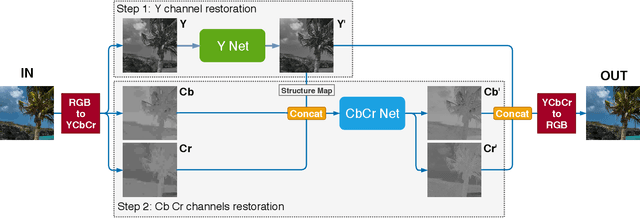

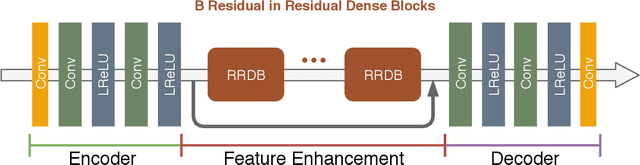
In this paper we propose a deep residual autoencoder exploiting Residual-in-Residual Dense Blocks (RRDB) to remove artifacts in JPEG compressed images that is independent from the Quality Factor (QF) used. The proposed approach leverages both the learning capacity of deep residual networks and prior knowledge of the JPEG compression pipeline. The proposed model operates in the YCbCr color space and performs JPEG artifact restoration in two phases using two different autoencoders: the first one restores the luma channel exploiting 2D convolutions; the second one, using the restored luma channel as a guide, restores the chroma channels explotining 3D convolutions. Extensive experimental results on three widely used benchmark datasets (i.e. LIVE1, BDS500, and CLASSIC-5) show that our model is able to outperform the state of the art with respect to all the evaluation metrics considered (i.e. PSNR, PSNR-B, and SSIM). This results is remarkable since the approaches in the state of the art use a different set of weights for each compression quality, while the proposed model uses the same weights for all of them, making it applicable to images in the wild where the QF used for compression is unkwnown. Furthermore, the proposed model shows a greater robustness than state-of-the-art methods when applied to compression qualities not seen during training.